 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlash-GMM: A Memory-Efficient Kernel for Scalable Soft Clustering
Jun 09, 2026We present \textbf{Flash-GMM}, a fused Triton kernel for efficient computation of Gaussian Mixture Models (GMMs) over large-scale data in a single GPU pass. By eliminating the need to materialize the full responsibility matrix in GPU memory, Flash-GMM achieves a \textbf{20$\times$} speedup over existing implementations and enables training on datasets more than \textbf{100$\times$} larger than previously feasible on one device. To demonstrate its impact, we integrate Flash-GMM into the IVF coarse quantizer for approximate nearest-neighbor (ANN) search. We show that soft GMM clustering is now a viable drop-in replacement for $k$-means, and that GMM responsibilities can be leveraged to assign border vectors to multiple clusters. Our approach reaches fixed recall targets with up to $1.7\times$ fewer distance computations, or equivalently, yields $+2$--$12$ recall@10 at matched computational cost. We release the kernel as an open-source project.
An Analysis of Hyper-Parameter Optimization Methods for Retrieval Augmented Generation
May 06, 2025Finding the optimal Retrieval-Augmented Generation (RAG) configuration for a given use case can be complex and expensive. Motivated by this challenge, frameworks for RAG hyper-parameter optimization (HPO) have recently emerged, yet their effectiveness has not been rigorously benchmarked. To address this gap, we present a comprehensive study involving 5 HPO algorithms over 5 datasets from diverse domains, including a new one collected for this work on real-world product documentation. Our study explores the largest HPO search space considered to date, with two optimized evaluation metrics. Analysis of the results shows that RAG HPO can be done efficiently, either greedily or with iterative random search, and that it significantly boosts RAG performance for all datasets. For greedy HPO approaches, we show that optimizing models first is preferable to the prevalent practice of optimizing sequentially according to the RAG pipeline order.
Unitxt: Flexible, Shareable and Reusable Data Preparation and Evaluation for Generative AI
Jan 25, 2024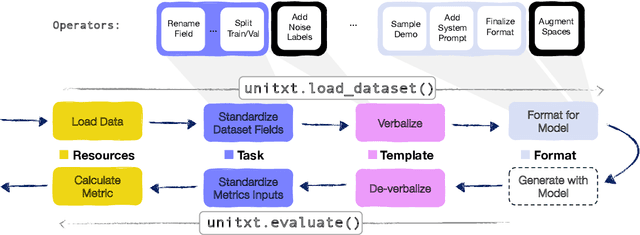

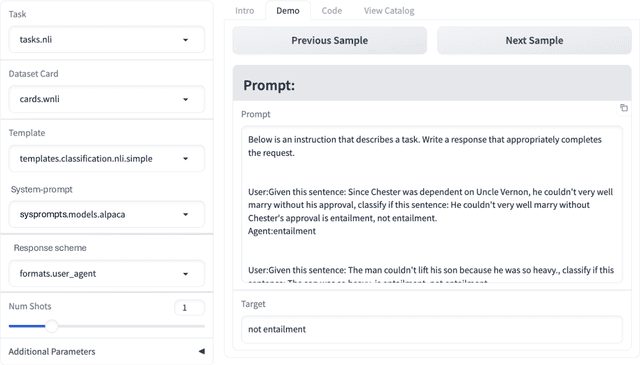

In the dynamic landscape of generative NLP, traditional text processing pipelines limit research flexibility and reproducibility, as they are tailored to specific dataset, task, and model combinations. The escalating complexity, involving system prompts, model-specific formats, instructions, and more, calls for a shift to a structured, modular, and customizable solution. Addressing this need, we present Unitxt, an innovative library for customizable textual data preparation and evaluation tailored to generative language models. Unitxt natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively. Join the Unitxt community at https://github.com/IBM/unitxt!
Multi-Domain Targeted Sentiment Analysis
May 08, 2022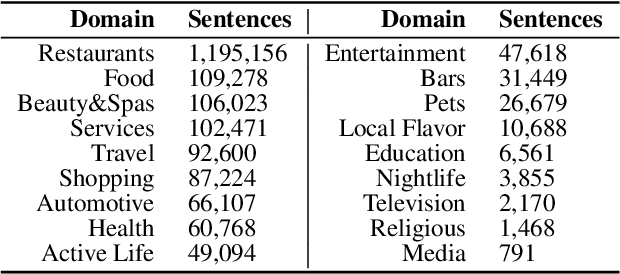
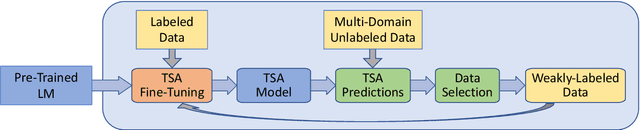
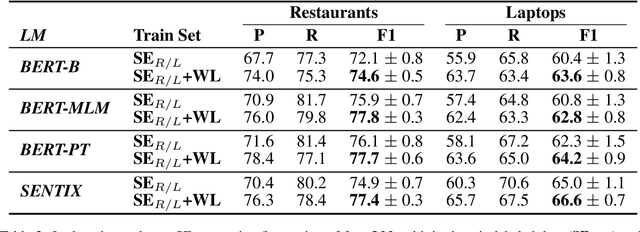
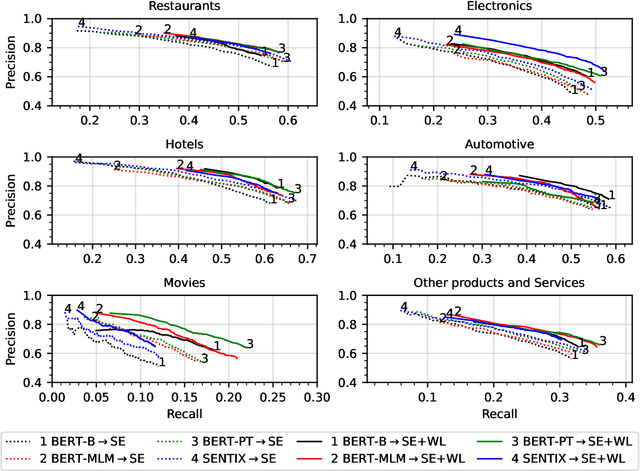
Targeted Sentiment Analysis (TSA) is a central task for generating insights from consumer reviews. Such content is extremely diverse, with sites like Amazon or Yelp containing reviews on products and businesses from many different domains. A real-world TSA system should gracefully handle that diversity. This can be achieved by a multi-domain model -- one that is robust to the domain of the analyzed texts, and performs well on various domains. To address this scenario, we present a multi-domain TSA system based on augmenting a given training set with diverse weak labels from assorted domains. These are obtained through self-training on the Yelp reviews corpus. Extensive experiments with our approach on three evaluation datasets across different domains demonstrate the effectiveness of our solution. We further analyze how restrictions imposed on the available labeled data affect the performance, and compare the proposed method to the costly alternative of manually gathering diverse TSA labeled data. Our results and analysis show that our approach is a promising step towards a practical domain-robust TSA system.
YASO: A New Benchmark for Targeted Sentiment Analysis
Dec 29, 2020


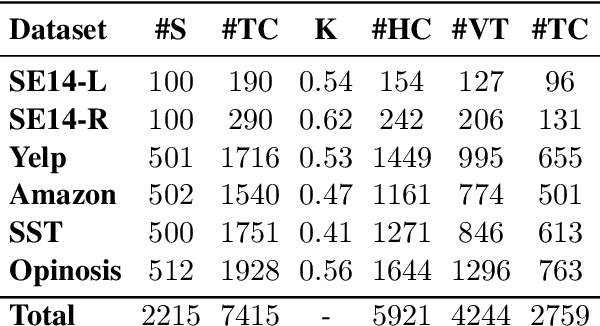
Sentiment analysis research has shifted over the years from the analysis of full documents or single sentences to a finer-level of detail -- identifying the sentiment towards single words or phrases -- with the task of Targeted Sentiment Analysis (TSA). While this problem is attracting a plethora of works focusing on algorithmic aspects, they are typically evaluated on a selection from a handful of datasets, and little effort, if any, is dedicated to the expansion of the available evaluation data. In this work, we present YASO -- a new crowd-sourced TSA evaluation dataset, collected using a new annotation scheme for labeling targets and their sentiments. The dataset contains 2,215 English sentences from movie, business and product reviews, and 7,415 terms and their corresponding sentiments annotated within these sentences. Our analysis verifies the reliability of our annotations, and explores the characteristics of the collected data. Lastly, benchmark results using five contemporary TSA systems lay the foundation for future work, and show there is ample room for improvement on this challenging new dataset.
Multilingual Argument Mining: Datasets and Analysis
Oct 13, 2020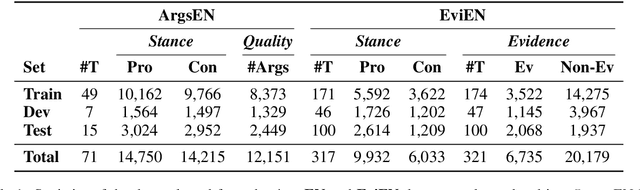
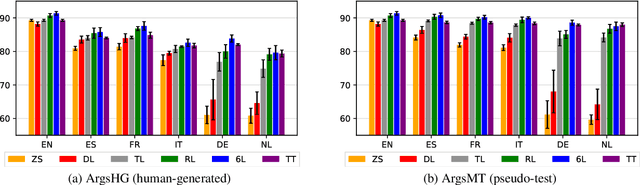
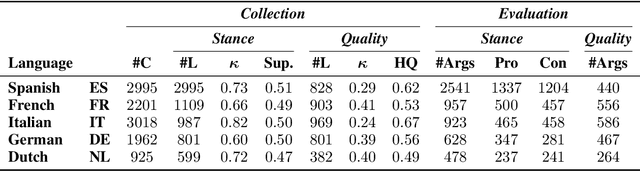
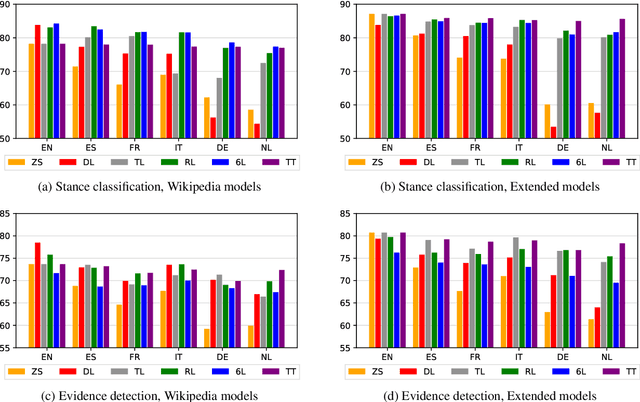
The growing interest in argument mining and computational argumentation brings with it a plethora of Natural Language Understanding (NLU) tasks and corresponding datasets. However, as with many other NLU tasks, the dominant language is English, with resources in other languages being few and far between. In this work, we explore the potential of transfer learning using the multilingual BERT model to address argument mining tasks in non-English languages, based on English datasets and the use of machine translation. We show that such methods are well suited for classifying the stance of arguments and detecting evidence, but less so for assessing the quality of arguments, presumably because quality is harder to preserve under translation. In addition, focusing on the translate-train approach, we show how the choice of languages for translation, and the relations among them, affect the accuracy of the resultant model. Finally, to facilitate evaluation of transfer learning on argument mining tasks, we provide a human-generated dataset with more than 10k arguments in multiple languages, as well as machine translation of the English datasets.
Out of the Echo Chamber: Detecting Countering Debate Speeches
May 03, 2020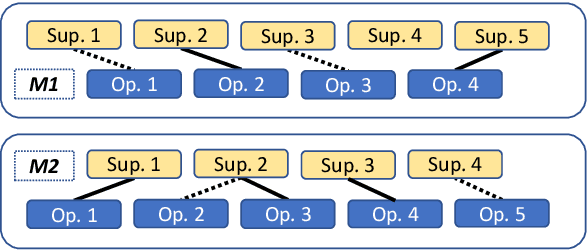
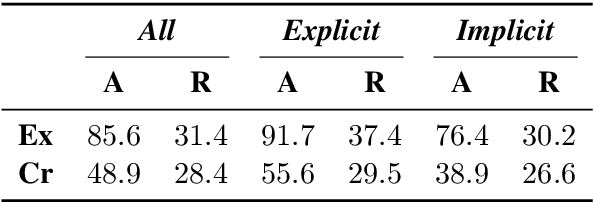
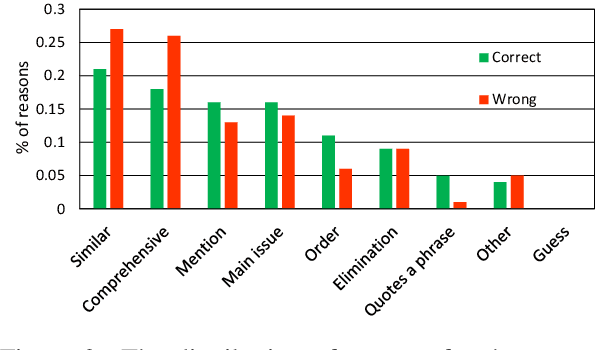

An educated and informed consumption of media content has become a challenge in modern times. With the shift from traditional news outlets to social media and similar venues, a major concern is that readers are becoming encapsulated in "echo chambers" and may fall prey to fake news and disinformation, lacking easy access to dissenting views. We suggest a novel task aiming to alleviate some of these concerns -- that of detecting articles that most effectively counter the arguments -- and not just the stance -- made in a given text. We study this problem in the context of debate speeches. Given such a speech, we aim to identify, from among a set of speeches on the same topic and with an opposing stance, the ones that directly counter it. We provide a large dataset of 3,685 such speeches (in English), annotated for this relation, which hopefully would be of general interest to the NLP community. We explore several algorithms addressing this task, and while some are successful, all fall short of expert human performance, suggesting room for further research. All data collected during this work is freely available for research.
A Dataset of General-Purpose Rebuttal
Sep 01, 2019
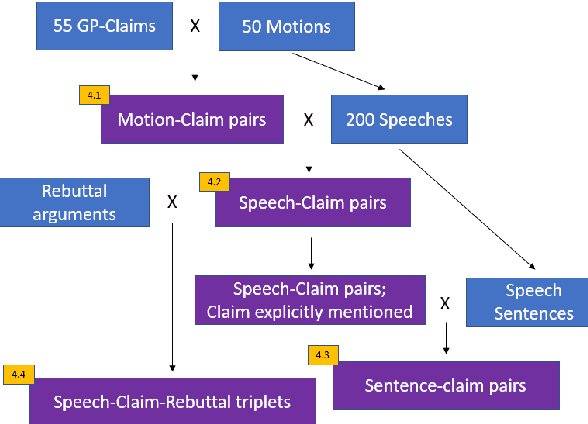
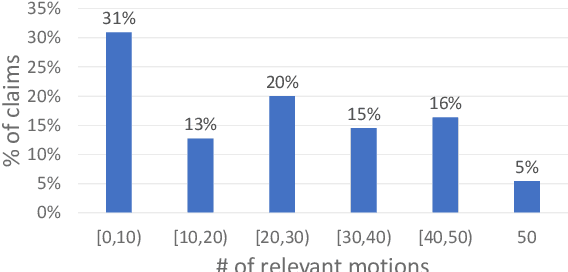
In Natural Language Understanding, the task of response generation is usually focused on responses to short texts, such as tweets or a turn in a dialog. Here we present a novel task of producing a critical response to a long argumentative text, and suggest a method based on general rebuttal arguments to address it. We do this in the context of the recently-suggested task of listening comprehension over argumentative content: given a speech on some specified topic, and a list of relevant arguments, the goal is to determine which of the arguments appear in the speech. The general rebuttals we describe here (written in English) overcome the need for topic-specific arguments to be provided, by proving to be applicable for a large set of topics. This allows creating responses beyond the scope of topics for which specific arguments are available. All data collected during this work is freely available for research.
Towards Effective Rebuttal: Listening Comprehension using Corpus-Wide Claim Mining
Jul 27, 2019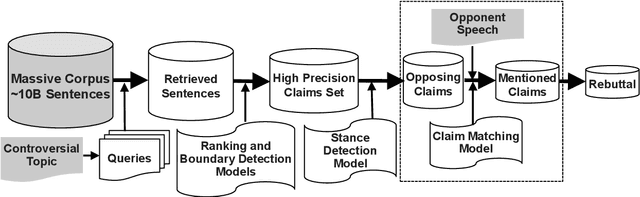
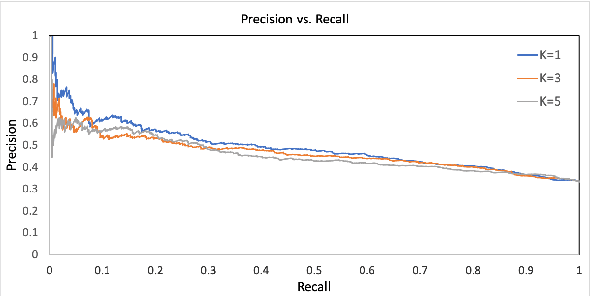
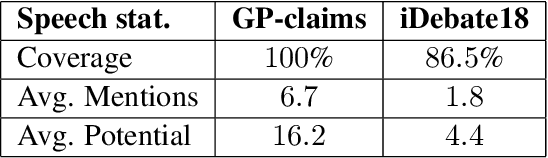
Engaging in a live debate requires, among other things, the ability to effectively rebut arguments claimed by your opponent. In particular, this requires identifying these arguments. Here, we suggest doing so by automatically mining claims from a corpus of news articles containing billions of sentences, and searching for them in a given speech. This raises the question of whether such claims indeed correspond to those made in spoken speeches. To this end, we collected a large dataset of $400$ speeches in English discussing $200$ controversial topics, mined claims for each topic, and asked annotators to identify the mined claims mentioned in each speech. Results show that in the vast majority of speeches debaters indeed make use of such claims. In addition, we present several baselines for the automatic detection of mined claims in speeches, forming the basis for future work. All collected data is freely available for research.