 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Sleuth: From Unlabeled Text to a Classifier in a Few Hours
Aug 02, 2022



Text classification can be useful in many real-world scenarios, saving a lot of time for end users. However, building a custom classifier typically requires coding skills and ML knowledge, which poses a significant barrier for many potential users. To lift this barrier, we introduce Label Sleuth, a free open source system for labeling and creating text classifiers. This system is unique for (a) being a no-code system, making NLP accessible to non-experts, (b) guiding users through the entire labeling process until they obtain a custom classifier, making the process efficient -- from cold start to classifier in a few hours, and (c) being open for configuration and extension by developers. By open sourcing Label Sleuth we hope to build a community of users and developers that will broaden the utilization of NLP models.
Quality Controlled Paraphrase Generation
Apr 01, 2022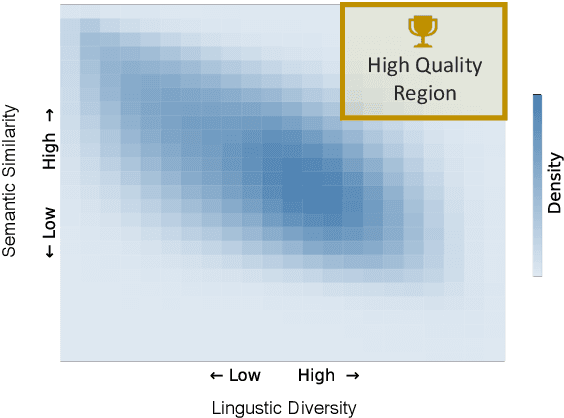

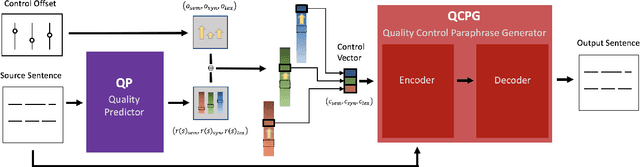
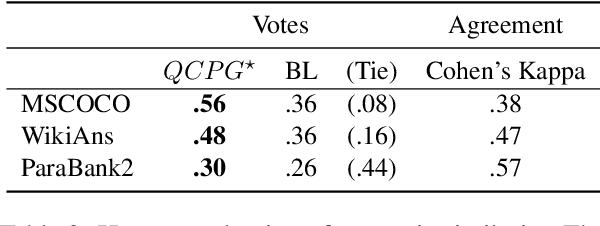
Paraphrase generation has been widely used in various downstream tasks. Most tasks benefit mainly from high quality paraphrases, namely those that are semantically similar to, yet linguistically diverse from, the original sentence. Generating high-quality paraphrases is challenging as it becomes increasingly hard to preserve meaning as linguistic diversity increases. Recent works achieve nice results by controlling specific aspects of the paraphrase, such as its syntactic tree. However, they do not allow to directly control the quality of the generated paraphrase, and suffer from low flexibility and scalability. Here we propose $QCPG$, a quality-guided controlled paraphrase generation model, that allows directly controlling the quality dimensions. Furthermore, we suggest a method that given a sentence, identifies points in the quality control space that are expected to yield optimal generated paraphrases. We show that our method is able to generate paraphrases which maintain the original meaning while achieving higher diversity than the uncontrolled baseline. The models, the code, and the data can be found in https://github.com/IBM/quality-controlled-paraphrase-generation.
Cluster & Tune: Boost Cold Start Performance in Text Classification
Mar 20, 2022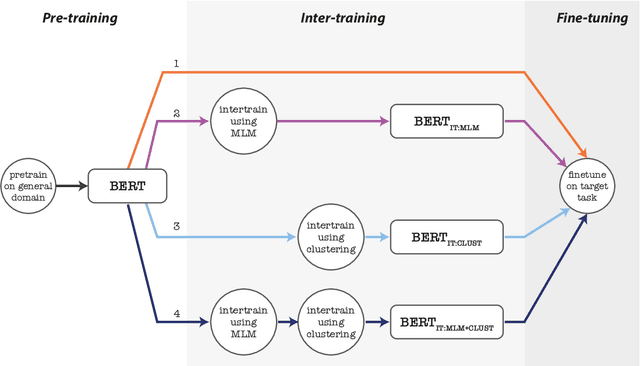
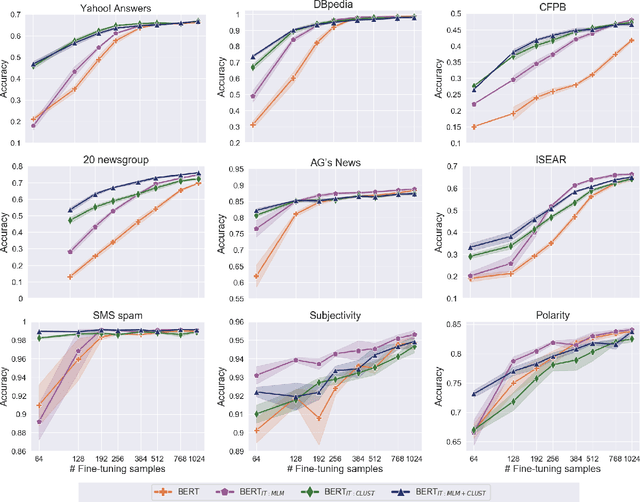
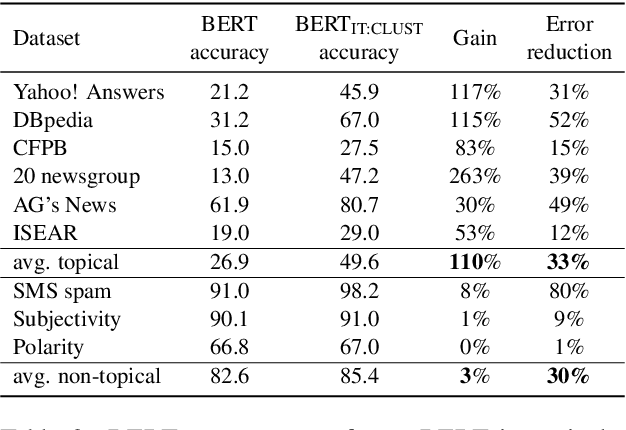
In real-world scenarios, a text classification task often begins with a cold start, when labeled data is scarce. In such cases, the common practice of fine-tuning pre-trained models, such as BERT, for a target classification task, is prone to produce poor performance. We suggest a method to boost the performance of such models by adding an intermediate unsupervised classification task, between the pre-training and fine-tuning phases. As such an intermediate task, we perform clustering and train the pre-trained model on predicting the cluster labels. We test this hypothesis on various data sets, and show that this additional classification phase can significantly improve performance, mainly for topical classification tasks, when the number of labeled instances available for fine-tuning is only a couple of dozen to a few hundred.
Fortunately, Discourse Markers Can Enhance Language Models for Sentiment Analysis
Jan 06, 2022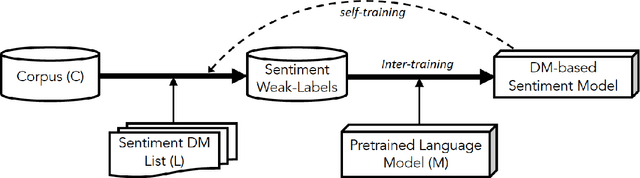

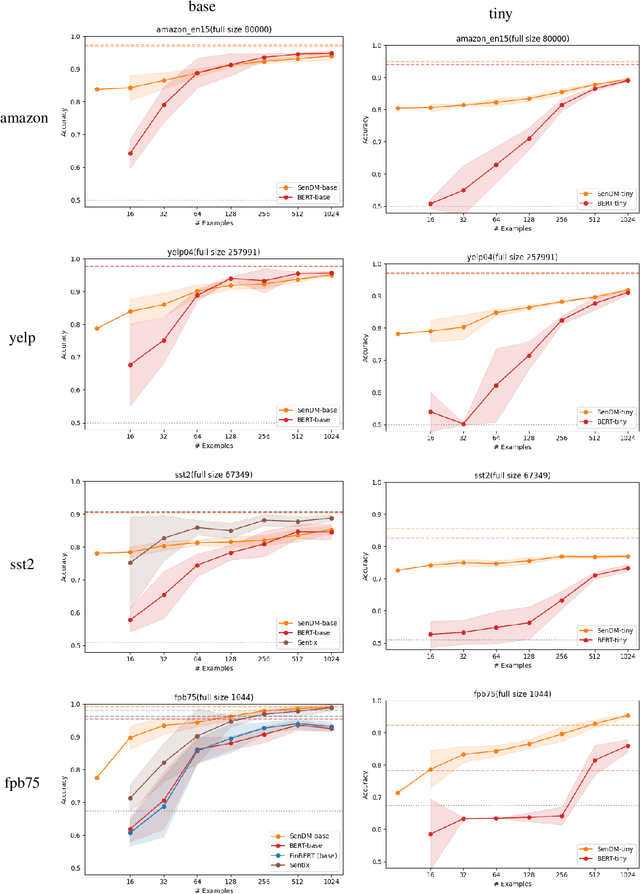
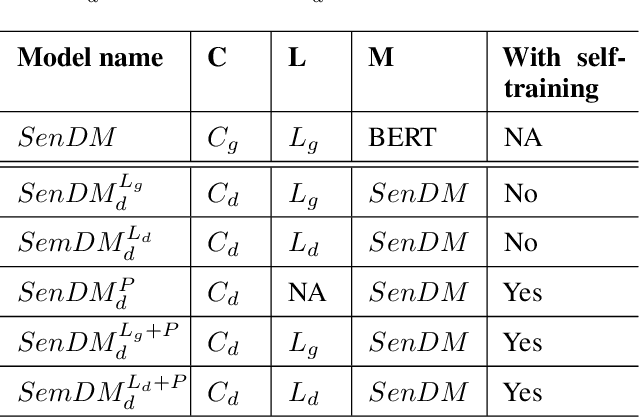
In recent years, pretrained language models have revolutionized the NLP world, while achieving state of the art performance in various downstream tasks. However, in many cases, these models do not perform well when labeled data is scarce and the model is expected to perform in the zero or few shot setting. Recently, several works have shown that continual pretraining or performing a second phase of pretraining (inter-training) which is better aligned with the downstream task, can lead to improved results, especially in the scarce data setting. Here, we propose to leverage sentiment-carrying discourse markers to generate large-scale weakly-labeled data, which in turn can be used to adapt language models for sentiment analysis. Extensive experimental results show the value of our approach on various benchmark datasets, including the finance domain. Code, models and data are available at https://github.com/ibm/tslm-discourse-markers.
TWEETSUMM -- A Dialog Summarization Dataset for Customer Service
Nov 23, 2021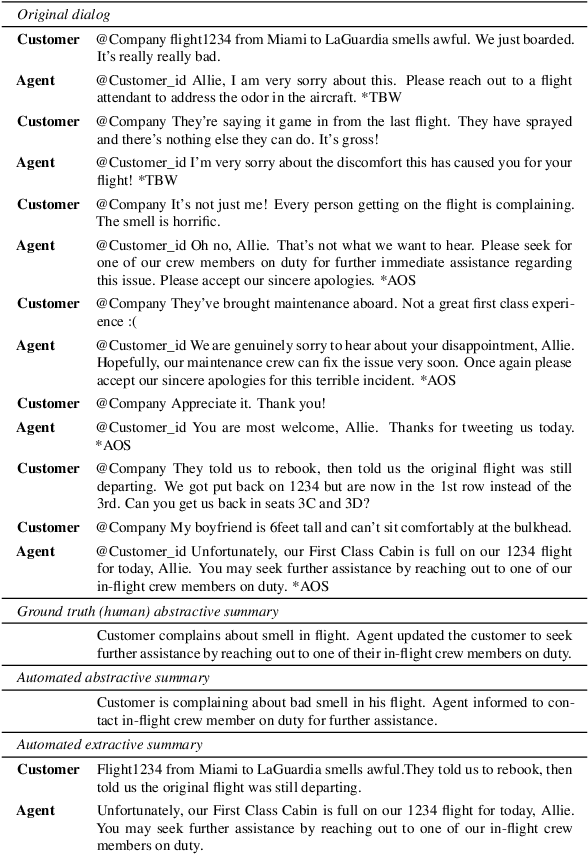
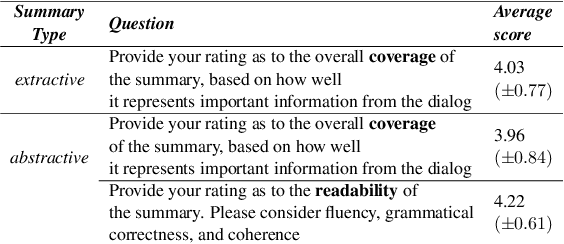


In a typical customer service chat scenario, customers contact a support center to ask for help or raise complaints, and human agents try to solve the issues. In most cases, at the end of the conversation, agents are asked to write a short summary emphasizing the problem and the proposed solution, usually for the benefit of other agents that may have to deal with the same customer or issue. The goal of the present article is advancing the automation of this task. We introduce the first large scale, high quality, customer care dialog summarization dataset with close to 6500 human annotated summaries. The data is based on real-world customer support dialogs and includes both extractive and abstractive summaries. We also introduce a new unsupervised, extractive summarization method specific to dialogs.
Overview of the 2021 Key Point Analysis Shared Task
Oct 20, 2021
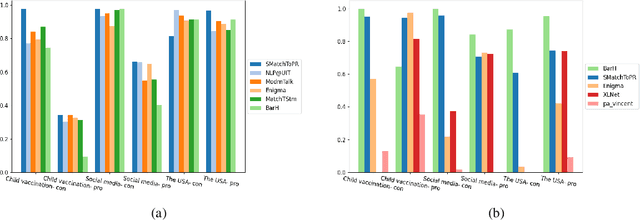
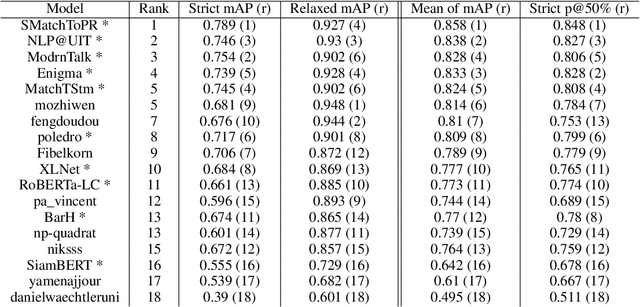
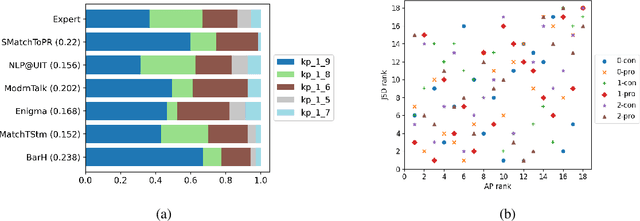
We describe the 2021 Key Point Analysis (KPA-2021) shared task on key point analysis that we organized as a part of the 8th Workshop on Argument Mining (ArgMining 2021) at EMNLP 2021. We outline various approaches and discuss the results of the shared task. We expect the task and the findings reported in this paper to be relevant for researchers working on text summarization and argument mining.
YASO: A New Benchmark for Targeted Sentiment Analysis
Dec 29, 2020


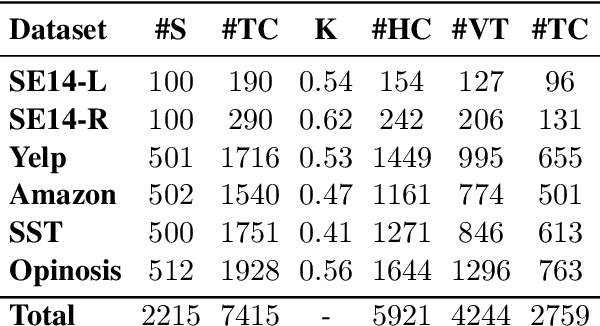
Sentiment analysis research has shifted over the years from the analysis of full documents or single sentences to a finer-level of detail -- identifying the sentiment towards single words or phrases -- with the task of Targeted Sentiment Analysis (TSA). While this problem is attracting a plethora of works focusing on algorithmic aspects, they are typically evaluated on a selection from a handful of datasets, and little effort, if any, is dedicated to the expansion of the available evaluation data. In this work, we present YASO -- a new crowd-sourced TSA evaluation dataset, collected using a new annotation scheme for labeling targets and their sentiments. The dataset contains 2,215 English sentences from movie, business and product reviews, and 7,415 terms and their corresponding sentiments annotated within these sentences. Our analysis verifies the reliability of our annotations, and explores the characteristics of the collected data. Lastly, benchmark results using five contemporary TSA systems lay the foundation for future work, and show there is ample room for improvement on this challenging new dataset.
Improved Semantic Role Labeling using Parameterized Neighborhood Memory Adaptation
Nov 29, 2020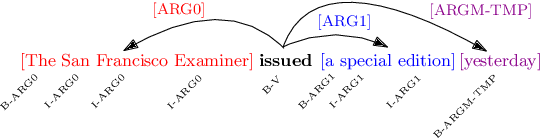
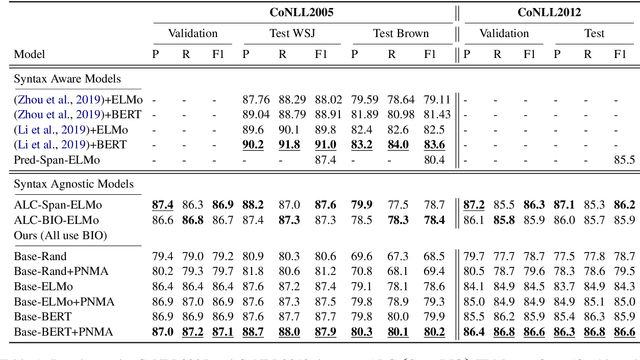
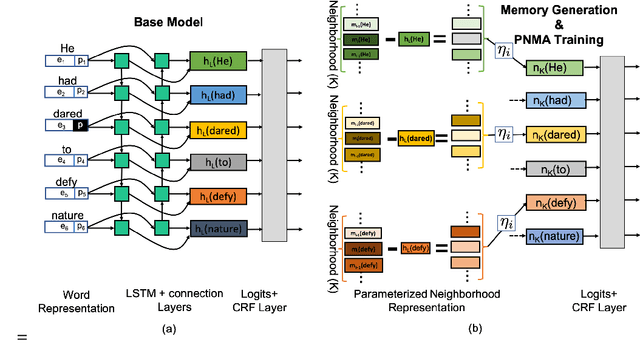
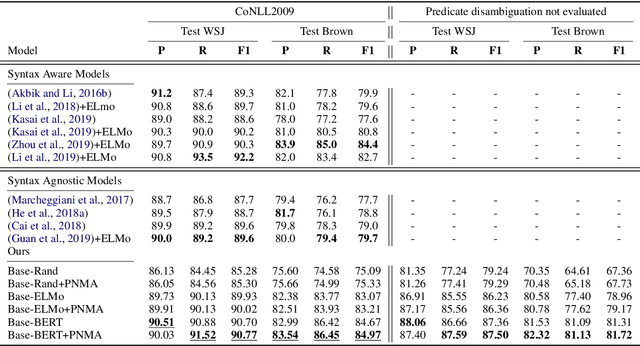
Deep neural models achieve some of the best results for semantic role labeling. Inspired by instance-based learning that utilizes nearest neighbors to handle low-frequency context-specific training samples, we investigate the use of memory adaptation techniques in deep neural models. We propose a parameterized neighborhood memory adaptive (PNMA) method that uses a parameterized representation of the nearest neighbors of tokens in a memory of activations and makes predictions based on the most similar samples in the training data. We empirically show that PNMA consistently improves the SRL performance of the base model irrespective of types of word embeddings. Coupled with contextualized word embeddings derived from BERT, PNMA improves over existing models for both span and dependency semantic parsing datasets, especially on out-of-domain text, reaching F1 scores of 80.2, and 84.97 on CoNLL2005, and CoNLL2009 datasets, respectively.
Unsupervised Expressive Rules Provide Explainability and Assist Human Experts Grasping New Domains
Oct 19, 2020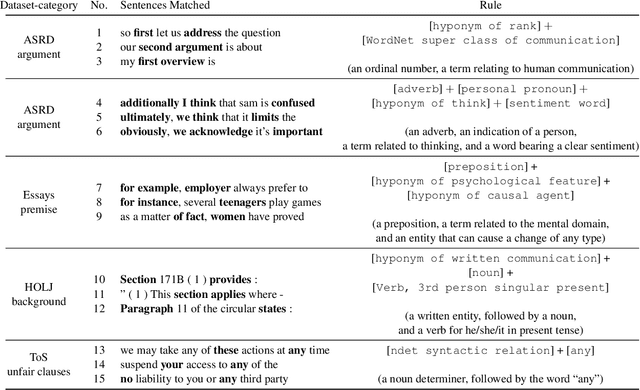
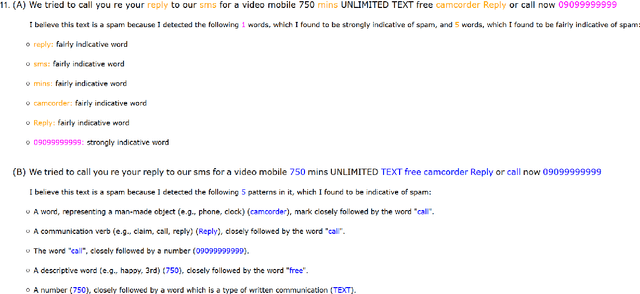
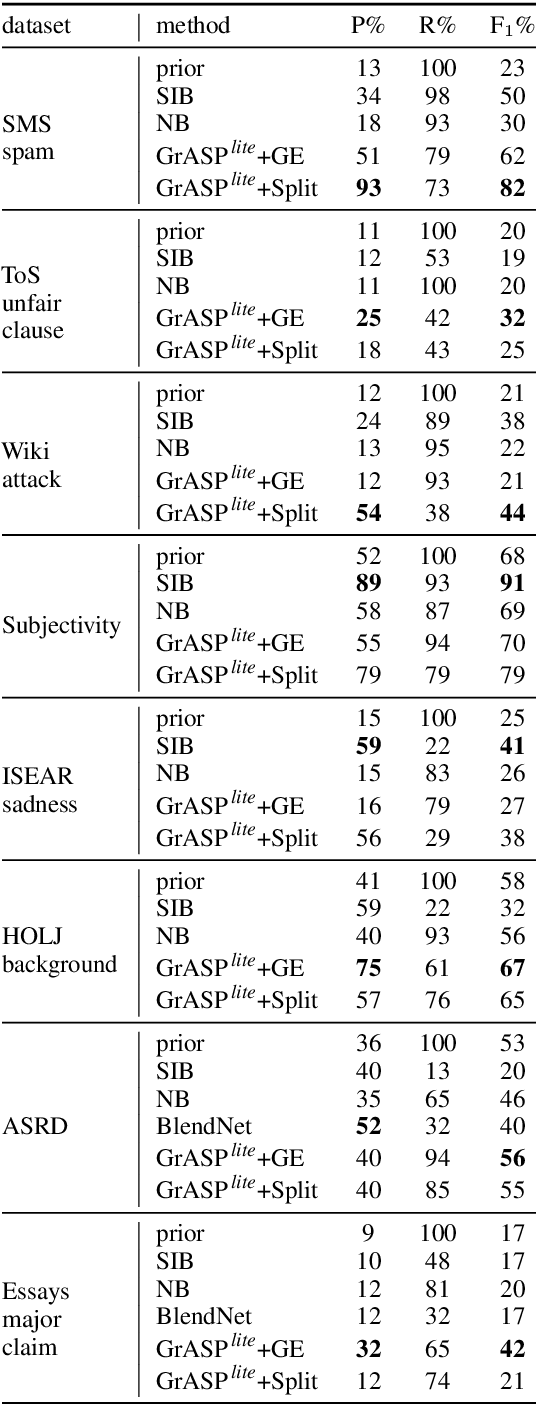
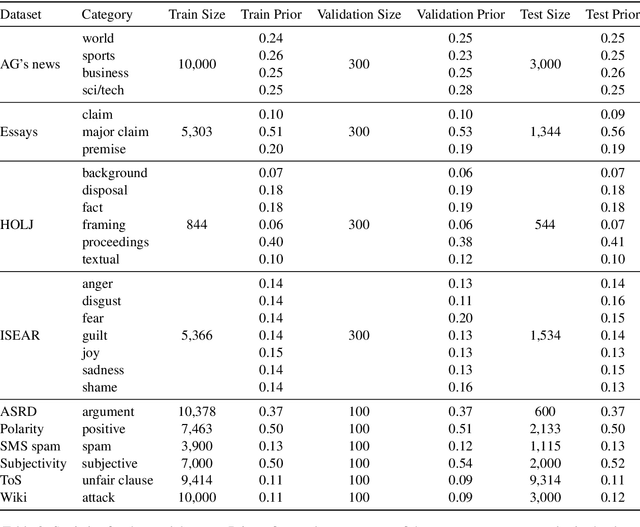
Approaching new data can be quite deterrent; you do not know how your categories of interest are realized in it, commonly, there is no labeled data at hand, and the performance of domain adaptation methods is unsatisfactory. Aiming to assist domain experts in their first steps into a new task over a new corpus, we present an unsupervised approach to reveal complex rules which cluster the unexplored corpus by its prominent categories (or facets). These rules are human-readable, thus providing an important ingredient which has become in short supply lately - explainability. Each rule provides an explanation for the commonality of all the texts it clusters together. We present an extensive evaluation of the usefulness of these rules in identifying target categories, as well as a user study which assesses their interpretability.
A Survey of the State of Explainable AI for Natural Language Processing
Oct 01, 2020

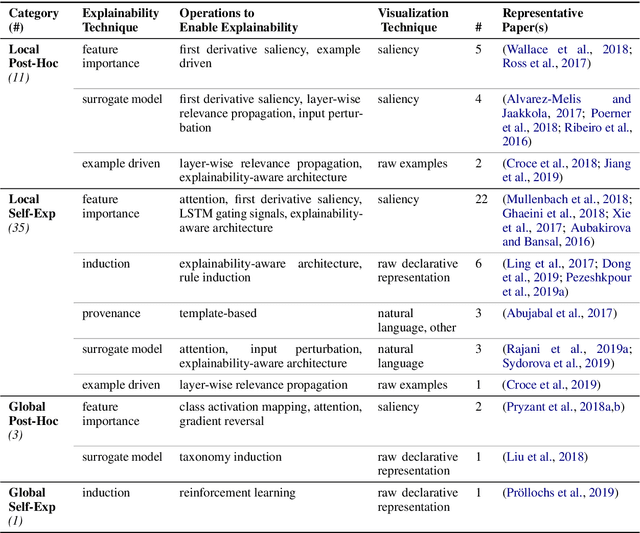

Recent years have seen important advances in the quality of state-of-the-art models, but this has come at the expense of models becoming less interpretable. This survey presents an overview of the current state of Explainable AI (XAI), considered within the domain of Natural Language Processing (NLP). We discuss the main categorization of explanations, as well as the various ways explanations can be arrived at and visualized. We detail the operations and explainability techniques currently available for generating explanations for NLP model predictions, to serve as a resource for model developers in the community. Finally, we point out the current gaps and encourage directions for future work in this important research area.