 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFortunately, Discourse Markers Can Enhance Language Models for Sentiment Analysis
Paper and Code
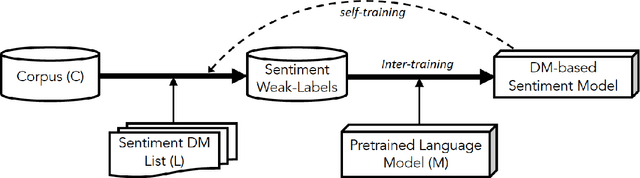

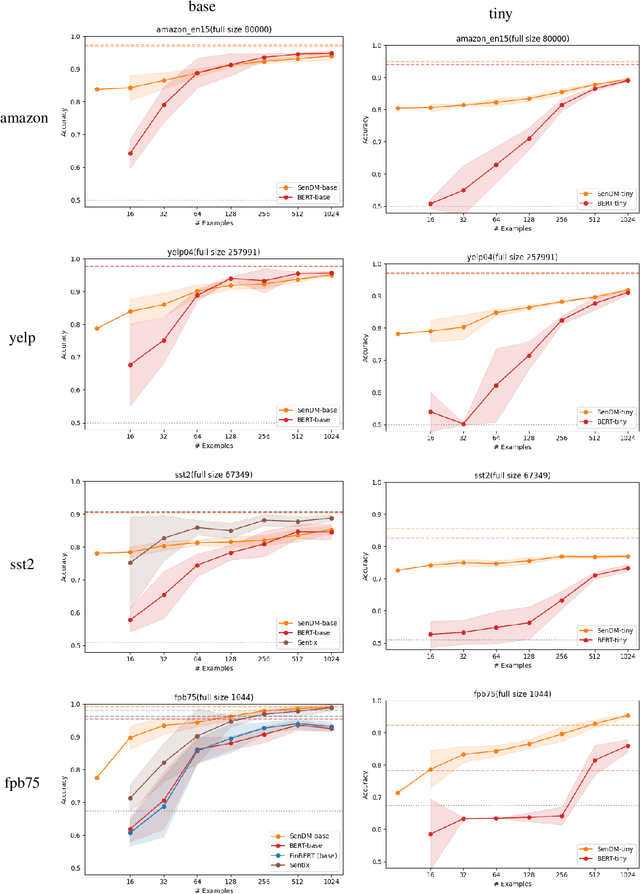
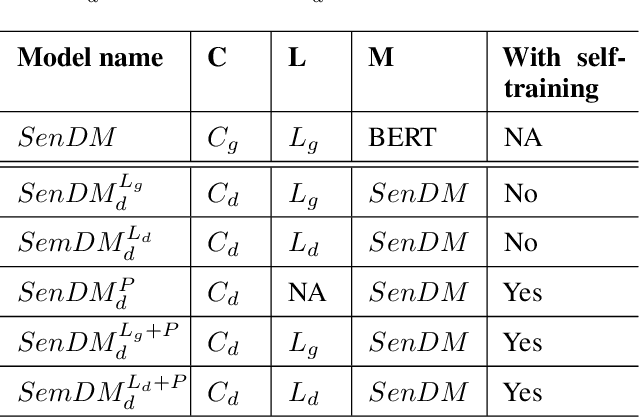
In recent years, pretrained language models have revolutionized the NLP world, while achieving state of the art performance in various downstream tasks. However, in many cases, these models do not perform well when labeled data is scarce and the model is expected to perform in the zero or few shot setting. Recently, several works have shown that continual pretraining or performing a second phase of pretraining (inter-training) which is better aligned with the downstream task, can lead to improved results, especially in the scarce data setting. Here, we propose to leverage sentiment-carrying discourse markers to generate large-scale weakly-labeled data, which in turn can be used to adapt language models for sentiment analysis. Extensive experimental results show the value of our approach on various benchmark datasets, including the finance domain. Code, models and data are available at https://github.com/ibm/tslm-discourse-markers.