 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Tree Model of Meaningful Memory
Dec 02, 2024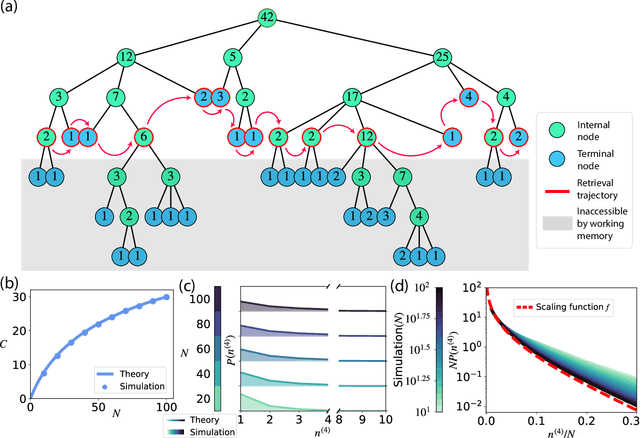
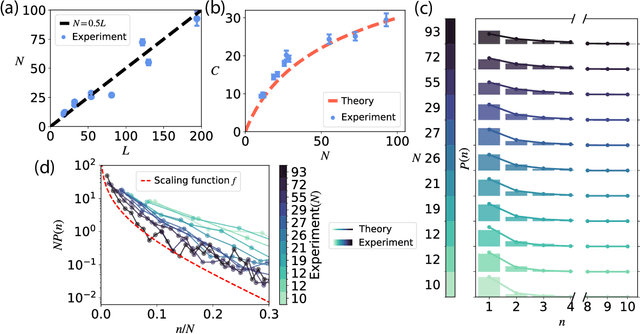
Traditional studies of memory for meaningful narratives focus on specific stories and their semantic structures but do not address common quantitative features of recall across different narratives. We introduce a statistical ensemble of random trees to represent narratives as hierarchies of key points, where each node is a compressed representation of its descendant leaves, which are the original narrative segments. Recall is modeled as constrained by working memory capacity from this hierarchical structure. Our analytical solution aligns with observations from large-scale narrative recall experiments. Specifically, our model explains that (1) average recall length increases sublinearly with narrative length, and (2) individuals summarize increasingly longer narrative segments in each recall sentence. Additionally, the theory predicts that for sufficiently long narratives, a universal, scale-invariant limit emerges, where the fraction of a narrative summarized by a single recall sentence follows a distribution independent of narrative length.
Label Sleuth: From Unlabeled Text to a Classifier in a Few Hours
Aug 02, 2022



Text classification can be useful in many real-world scenarios, saving a lot of time for end users. However, building a custom classifier typically requires coding skills and ML knowledge, which poses a significant barrier for many potential users. To lift this barrier, we introduce Label Sleuth, a free open source system for labeling and creating text classifiers. This system is unique for (a) being a no-code system, making NLP accessible to non-experts, (b) guiding users through the entire labeling process until they obtain a custom classifier, making the process efficient -- from cold start to classifier in a few hours, and (c) being open for configuration and extension by developers. By open sourcing Label Sleuth we hope to build a community of users and developers that will broaden the utilization of NLP models.
Quality Controlled Paraphrase Generation
Apr 01, 2022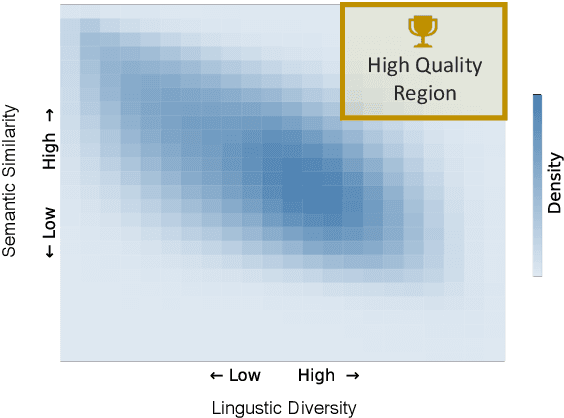

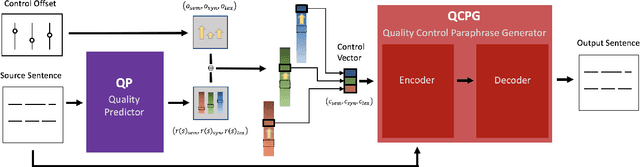
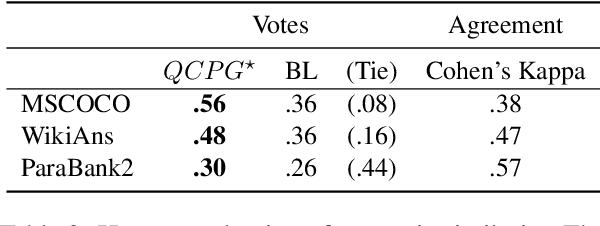
Paraphrase generation has been widely used in various downstream tasks. Most tasks benefit mainly from high quality paraphrases, namely those that are semantically similar to, yet linguistically diverse from, the original sentence. Generating high-quality paraphrases is challenging as it becomes increasingly hard to preserve meaning as linguistic diversity increases. Recent works achieve nice results by controlling specific aspects of the paraphrase, such as its syntactic tree. However, they do not allow to directly control the quality of the generated paraphrase, and suffer from low flexibility and scalability. Here we propose $QCPG$, a quality-guided controlled paraphrase generation model, that allows directly controlling the quality dimensions. Furthermore, we suggest a method that given a sentence, identifies points in the quality control space that are expected to yield optimal generated paraphrases. We show that our method is able to generate paraphrases which maintain the original meaning while achieving higher diversity than the uncontrolled baseline. The models, the code, and the data can be found in https://github.com/IBM/quality-controlled-paraphrase-generation.
Fortunately, Discourse Markers Can Enhance Language Models for Sentiment Analysis
Jan 06, 2022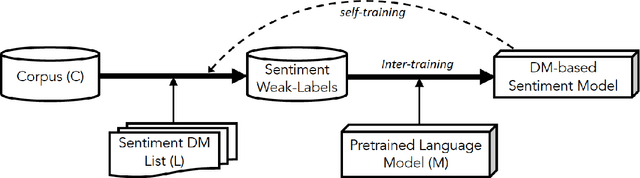

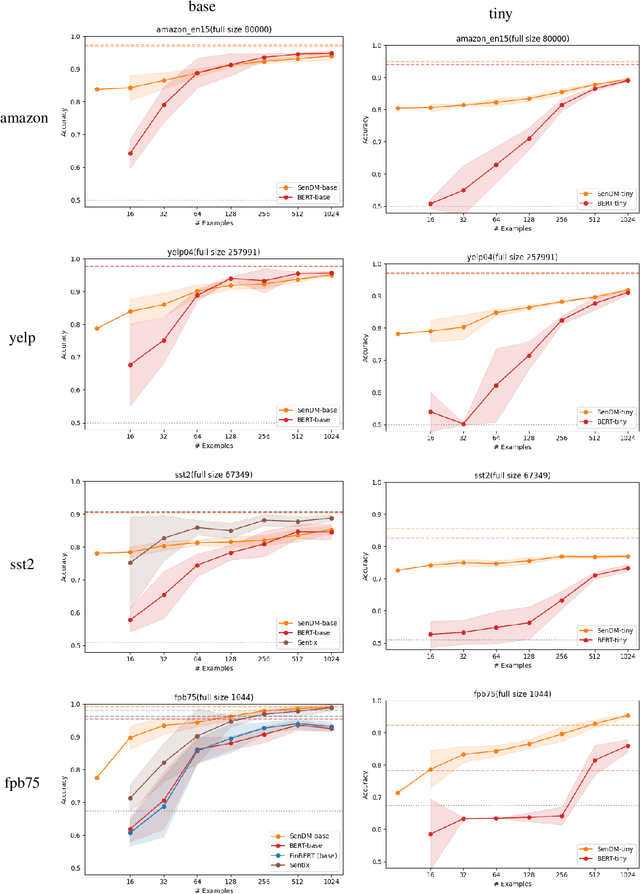
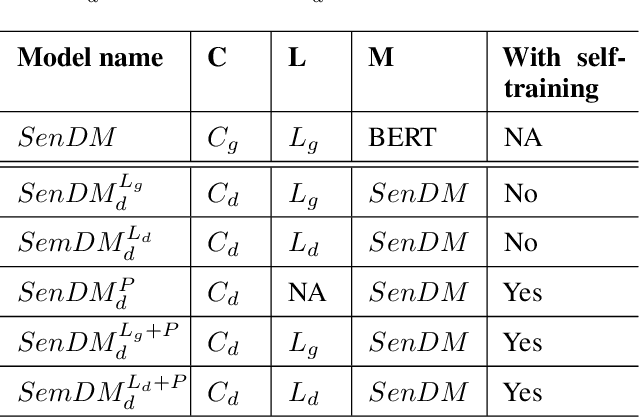
In recent years, pretrained language models have revolutionized the NLP world, while achieving state of the art performance in various downstream tasks. However, in many cases, these models do not perform well when labeled data is scarce and the model is expected to perform in the zero or few shot setting. Recently, several works have shown that continual pretraining or performing a second phase of pretraining (inter-training) which is better aligned with the downstream task, can lead to improved results, especially in the scarce data setting. Here, we propose to leverage sentiment-carrying discourse markers to generate large-scale weakly-labeled data, which in turn can be used to adapt language models for sentiment analysis. Extensive experimental results show the value of our approach on various benchmark datasets, including the finance domain. Code, models and data are available at https://github.com/ibm/tslm-discourse-markers.
Fast End-to-End Wikification
Aug 19, 2019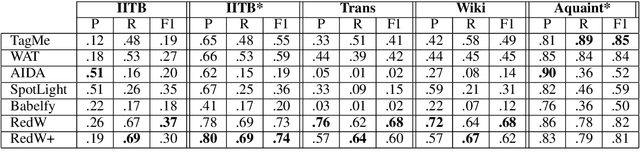
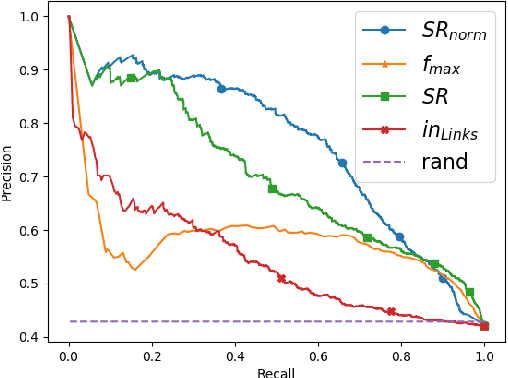
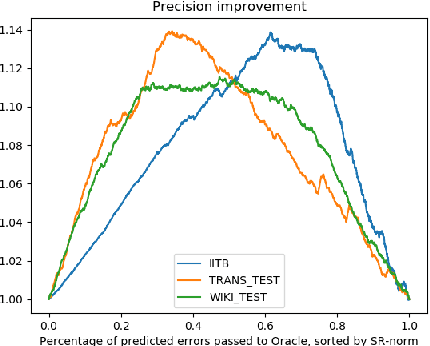

Wikification of large corpora is beneficial for various NLP applications. Existing methods focus on quality performance rather than run-time, and are therefore non-feasible for large data. Here, we introduce RedW, a run-time oriented Wikification solution, based on Wikipedia redirects, that can Wikify massive corpora with competitive performance. We further propose an efficient method for estimating RedW confidence, opening the door for applying more demanding methods only on top of RedW lower-confidence results. Our experimental results support the validity of the proposed approach.
Learning Concept Abstractness Using Weak Supervision
Sep 05, 2018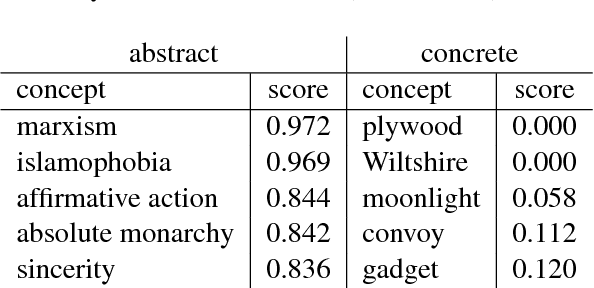
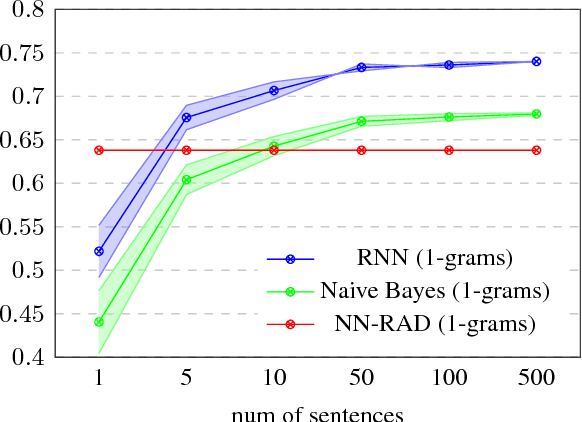
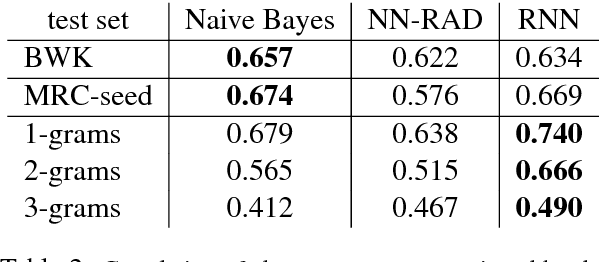
We introduce a weakly supervised approach for inferring the property of abstractness of words and expressions in the complete absence of labeled data. Exploiting only minimal linguistic clues and the contextual usage of a concept as manifested in textual data, we train sufficiently powerful classifiers, obtaining high correlation with human labels. The results imply the applicability of this approach to additional properties of concepts, additional languages, and resource-scarce scenarios.