 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Practices for Machine Learning Systems: An Industrial Framework for Analysis and Optimization
Jun 09, 2023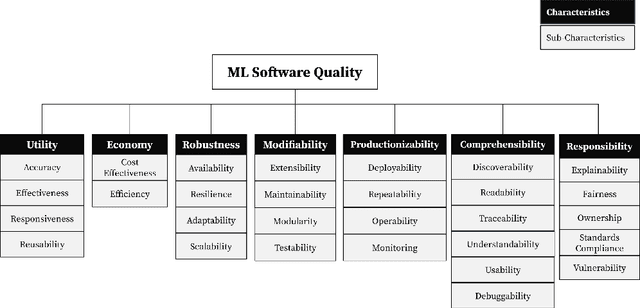

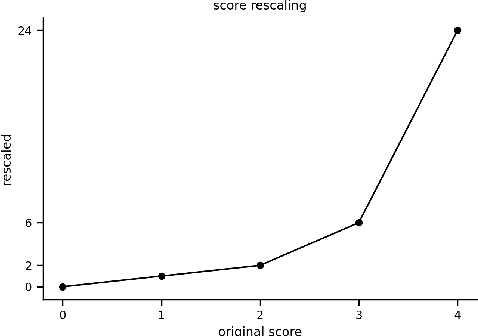
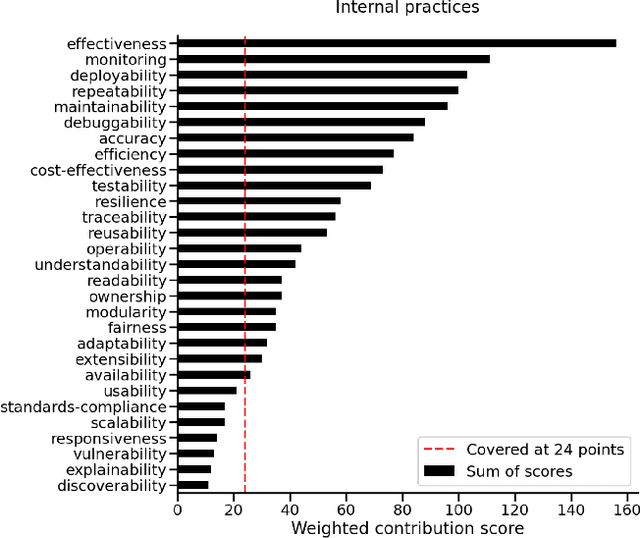
In the last few years, the Machine Learning (ML) and Artificial Intelligence community has developed an increasing interest in Software Engineering (SE) for ML Systems leading to a proliferation of best practices, rules, and guidelines aiming at improving the quality of the software of ML Systems. However, understanding their impact on the overall quality has received less attention. Practices are usually presented in a prescriptive manner, without an explicit connection to their overall contribution to software quality. Based on the observation that different practices influence different aspects of software-quality and that one single quality aspect might be addressed by several practices we propose a framework to analyse sets of best practices with focus on quality impact and prioritization of their implementation. We first introduce a hierarchical Software Quality Model (SQM) specifically tailored for ML Systems. Relying on expert knowledge, the connection between individual practices and software quality aspects is explicitly elicited for a large set of well-established practices. Applying set-function optimization techniques we can answer questions such as what is the set of practices that maximizes SQM coverage, what are the most important ones, which practices should be implemented in order to improve specific quality aspects, among others. We illustrate the usage of our framework by analyzing well-known sets of practices.
Conversational Search with Mixed-Initiative -- Asking Good Clarification Questions backed-up by Passage Retrieval
Dec 14, 2021
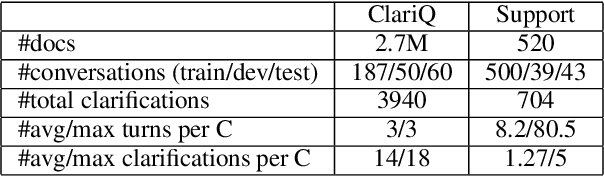
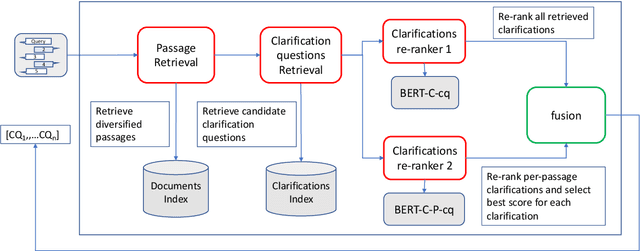
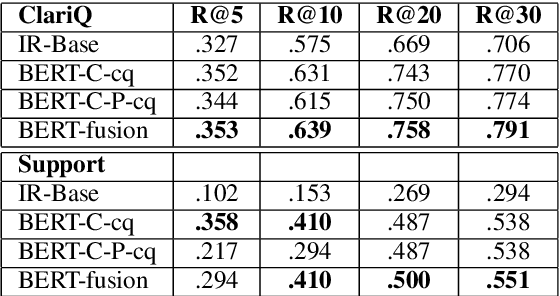
We deal with a scenario of conversational search with mixed-initiative: namely user-asks system-answers, as well as system-asks (clarification questions) and user-answers. We focus on the task of selecting the next clarification question, given conversation context. Our method leverages passage retrieval that is used both for an initial selection of relevant candidate clarification questions, as well as for fine-tuning two deep-learning models for re-ranking these candidates. We evaluated our method on two different use-cases. The first is an open domain conversational search in a large web collection. The second is a task-oriented customer-support setup. We show that our method performs well on both use-cases.
TWEETSUMM -- A Dialog Summarization Dataset for Customer Service
Nov 23, 2021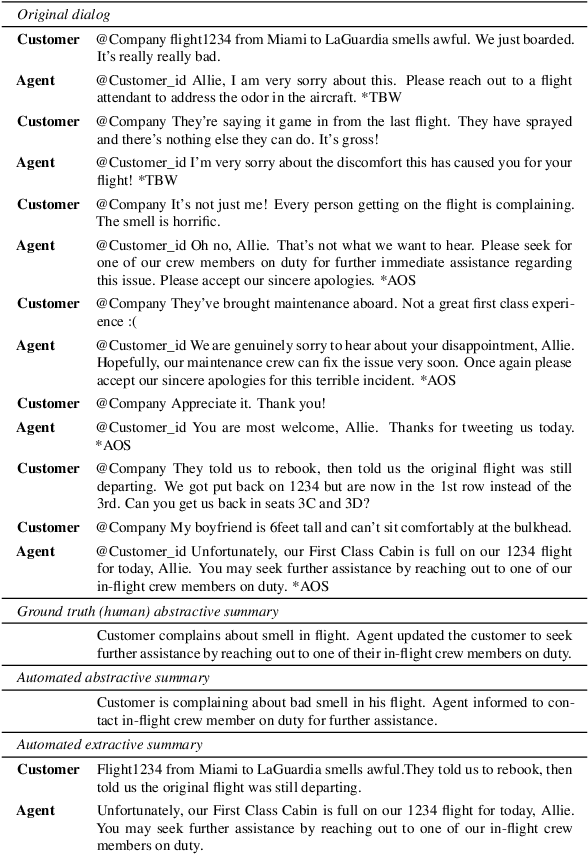
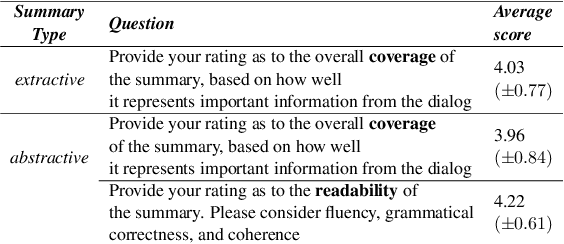


In a typical customer service chat scenario, customers contact a support center to ask for help or raise complaints, and human agents try to solve the issues. In most cases, at the end of the conversation, agents are asked to write a short summary emphasizing the problem and the proposed solution, usually for the benefit of other agents that may have to deal with the same customer or issue. The goal of the present article is advancing the automation of this task. We introduce the first large scale, high quality, customer care dialog summarization dataset with close to 6500 human annotated summaries. The data is based on real-world customer support dialogs and includes both extractive and abstractive summaries. We also introduce a new unsupervised, extractive summarization method specific to dialogs.
HowSumm: A Multi-Document Summarization Dataset Derived from WikiHow Articles
Oct 08, 2021



We present HowSumm, a novel large-scale dataset for the task of query-focused multi-document summarization (qMDS), which targets the use-case of generating actionable instructions from a set of sources. This use-case is different from the use-cases covered in existing multi-document summarization (MDS) datasets and is applicable to educational and industrial scenarios. We employed automatic methods, and leveraged statistics from existing human-crafted qMDS datasets, to create HowSumm from wikiHow website articles and the sources they cite. We describe the creation of the dataset and discuss the unique features that distinguish it from other summarization corpora. Automatic and human evaluations of both extractive and abstractive summarization models on the dataset reveal that there is room for improvement.
Summary Grounded Conversation Generation
Jun 07, 2021


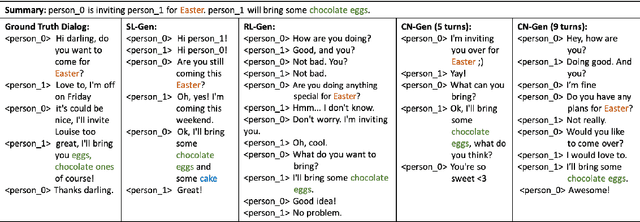
Many conversation datasets have been constructed in the recent years using crowdsourcing. However, the data collection process can be time consuming and presents many challenges to ensure data quality. Since language generation has improved immensely in recent years with the advancement of pre-trained language models, we investigate how such models can be utilized to generate entire conversations, given only a summary of a conversation as the input. We explore three approaches to generate summary grounded conversations, and evaluate the generated conversations using automatic measures and human judgements. We also show that the accuracy of conversation summarization can be improved by augmenting a conversation summarization dataset with generated conversations.
Conversational Document Prediction to Assist Customer Care Agents
Oct 05, 2020
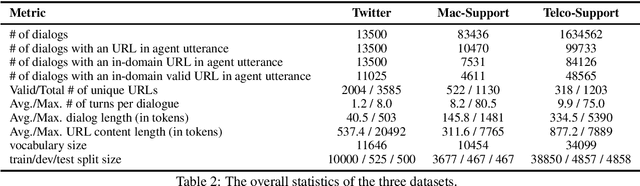

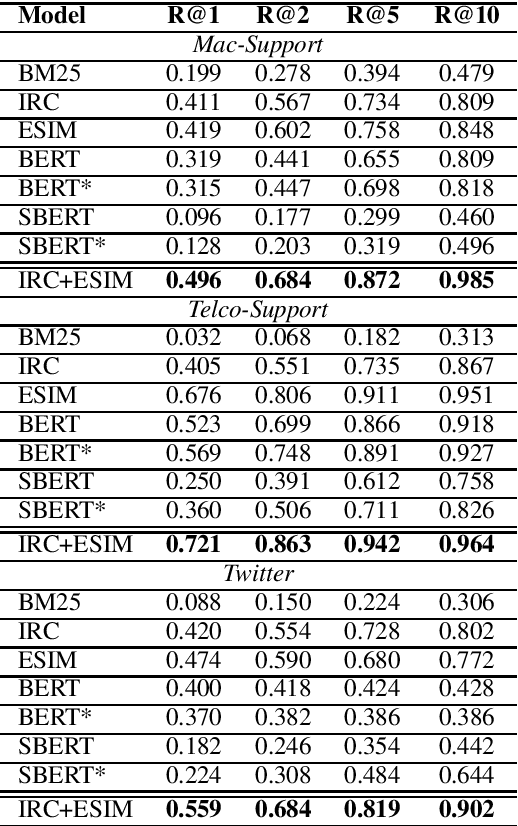
A frequent pattern in customer care conversations is the agents responding with appropriate webpage URLs that address users' needs. We study the task of predicting the documents that customer care agents can use to facilitate users' needs. We also introduce a new public dataset which supports the aforementioned problem. Using this dataset and two others, we investigate state-of-the art deep learning (DL) and information retrieval (IR) models for the task. Additionally, we analyze the practicality of such systems in terms of inference time complexity. Our show that an hybrid IR+DL approach provides the best of both worlds.
orgFAQ: A New Dataset and Analysis on Organizational FAQs and User Questions
Sep 03, 2020Frequently Asked Questions (FAQ) webpages are created by organizations for their users. FAQs are used in several scenarios, e.g., to answer user questions. On the other hand, the content of FAQs is affected by user questions by definition. In order to promote research in this field, several FAQ datasets exist. However, we claim that being collected from community websites, they do not correctly represent challenges associated with FAQs in an organizational context. Thus, we release orgFAQ, a new dataset composed of $6988$ user questions and $1579$ corresponding FAQs that were extracted from organizations' FAQ webpages in the Jobs domain. In this paper, we provide an analysis of the properties of such FAQs, and demonstrate the usefulness of our new dataset by utilizing it in a relevant task from the Jobs domain. We also show the value of the orgFAQ dataset in a task of a different domain - the COVID-19 pandemic.
A Study of Human Summaries of Scientific Articles
Feb 10, 2020

Researchers and students face an explosion of newly published papers which may be relevant to their work. This led to a trend of sharing human summaries of scientific papers. We analyze the summaries shared in one of these platforms Shortscience.org. The goal is to characterize human summaries of scientific papers, and use some of the insights obtained to improve and adapt existing automatic summarization systems to the domain of scientific papers.
A Summarization System for Scientific Documents
Aug 29, 2019
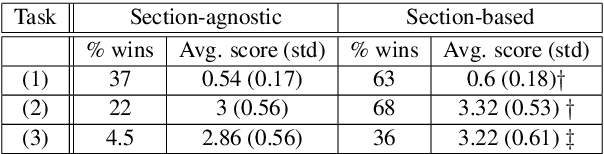

We present a novel system providing summaries for Computer Science publications. Through a qualitative user study, we identified the most valuable scenarios for discovery, exploration and understanding of scientific documents. Based on these findings, we built a system that retrieves and summarizes scientific documents for a given information need, either in form of a free-text query or by choosing categorized values such as scientific tasks, datasets and more. Our system ingested 270,000 papers, and its summarization module aims to generate concise yet detailed summaries. We validated our approach with human experts.
Controversy in Context
Aug 20, 2019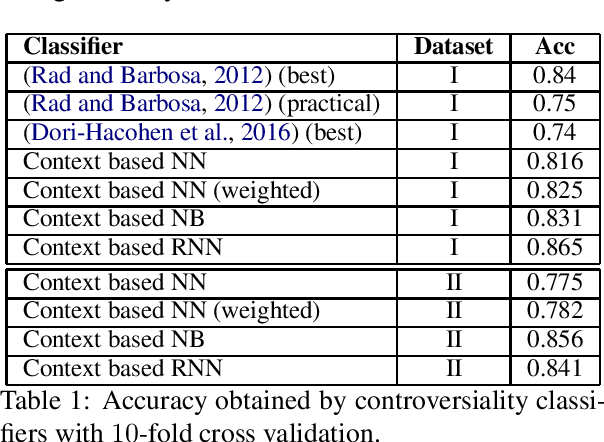
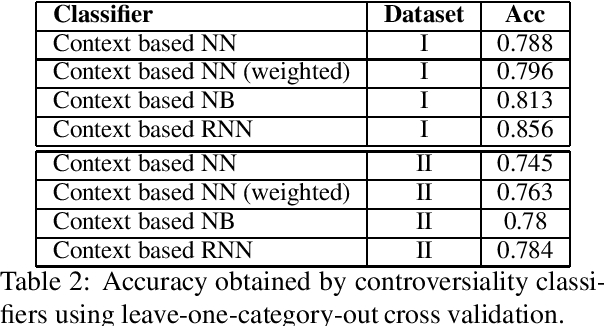
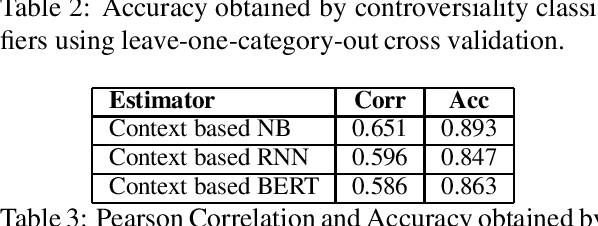
With the growing interest in social applications of Natural Language Processing and Computational Argumentation, a natural question is how controversial a given concept is. Prior works relied on Wikipedia's metadata and on content analysis of the articles pertaining to a concept in question. Here we show that the immediate textual context of a concept is strongly indicative of this property, and, using simple and language-independent machine-learning tools, we leverage this observation to achieve state-of-the-art results in controversiality prediction. In addition, we analyze and make available a new dataset of concepts labeled for controversiality. It is significantly larger than existing datasets, and grades concepts on a 0-10 scale, rather than treating controversiality as a binary label.