 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWEETSUMM -- A Dialog Summarization Dataset for Customer Service
Nov 23, 2021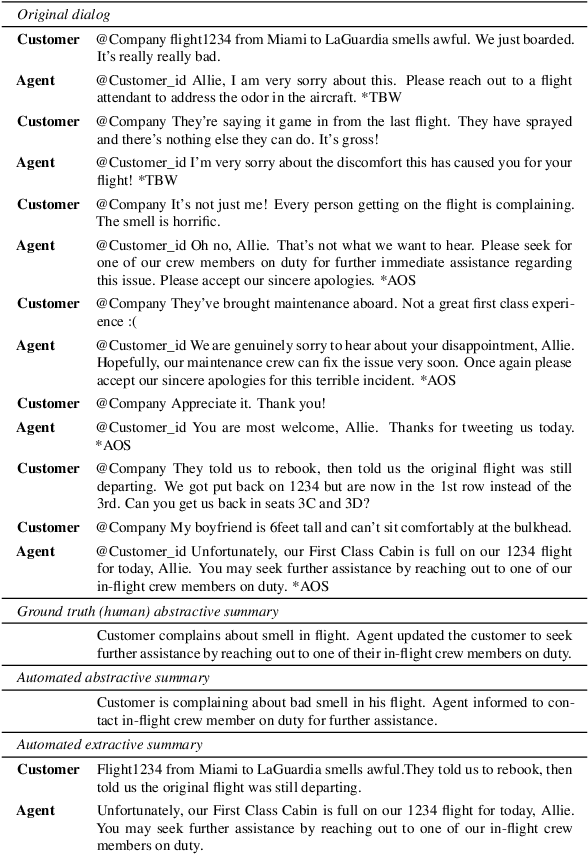


In a typical customer service chat scenario, customers contact a support center to ask for help or raise complaints, and human agents try to solve the issues. In most cases, at the end of the conversation, agents are asked to write a short summary emphasizing the problem and the proposed solution, usually for the benefit of other agents that may have to deal with the same customer or issue. The goal of the present article is advancing the automation of this task. We introduce the first large scale, high quality, customer care dialog summarization dataset with close to 6500 human annotated summaries. The data is based on real-world customer support dialogs and includes both extractive and abstractive summaries. We also introduce a new unsupervised, extractive summarization method specific to dialogs.
HowSumm: A Multi-Document Summarization Dataset Derived from WikiHow Articles
Oct 08, 2021



We present HowSumm, a novel large-scale dataset for the task of query-focused multi-document summarization (qMDS), which targets the use-case of generating actionable instructions from a set of sources. This use-case is different from the use-cases covered in existing multi-document summarization (MDS) datasets and is applicable to educational and industrial scenarios. We employed automatic methods, and leveraged statistics from existing human-crafted qMDS datasets, to create HowSumm from wikiHow website articles and the sources they cite. We describe the creation of the dataset and discuss the unique features that distinguish it from other summarization corpora. Automatic and human evaluations of both extractive and abstractive summarization models on the dataset reveal that there is room for improvement.
Summary Grounded Conversation Generation
Jun 07, 2021


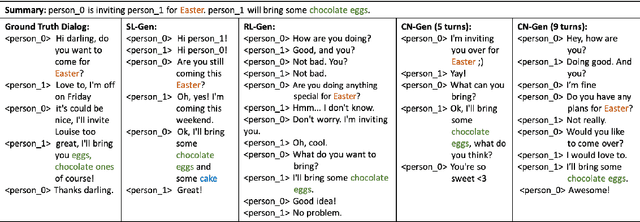
Many conversation datasets have been constructed in the recent years using crowdsourcing. However, the data collection process can be time consuming and presents many challenges to ensure data quality. Since language generation has improved immensely in recent years with the advancement of pre-trained language models, we investigate how such models can be utilized to generate entire conversations, given only a summary of a conversation as the input. We explore three approaches to generate summary grounded conversations, and evaluate the generated conversations using automatic measures and human judgements. We also show that the accuracy of conversation summarization can be improved by augmenting a conversation summarization dataset with generated conversations.
A Study of Human Summaries of Scientific Articles
Feb 10, 2020

Researchers and students face an explosion of newly published papers which may be relevant to their work. This led to a trend of sharing human summaries of scientific papers. We analyze the summaries shared in one of these platforms Shortscience.org. The goal is to characterize human summaries of scientific papers, and use some of the insights obtained to improve and adapt existing automatic summarization systems to the domain of scientific papers.
A Summarization System for Scientific Documents
Aug 29, 2019
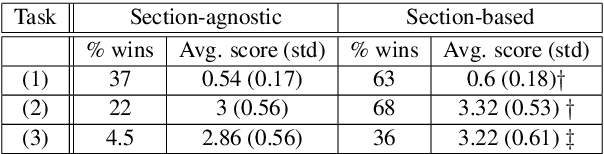

We present a novel system providing summaries for Computer Science publications. Through a qualitative user study, we identified the most valuable scenarios for discovery, exploration and understanding of scientific documents. Based on these findings, we built a system that retrieves and summarizes scientific documents for a given information need, either in form of a free-text query or by choosing categorized values such as scientific tasks, datasets and more. Our system ingested 270,000 papers, and its summarization module aims to generate concise yet detailed summaries. We validated our approach with human experts.
An Editorial Network for Enhanced Document Summarization
Feb 27, 2019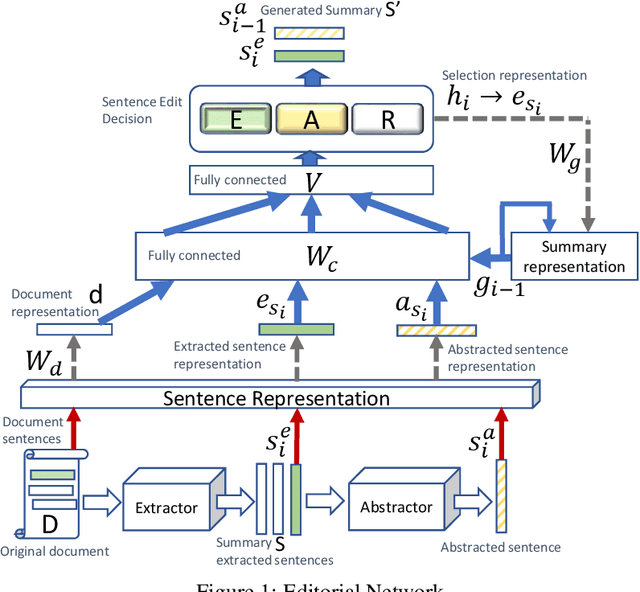
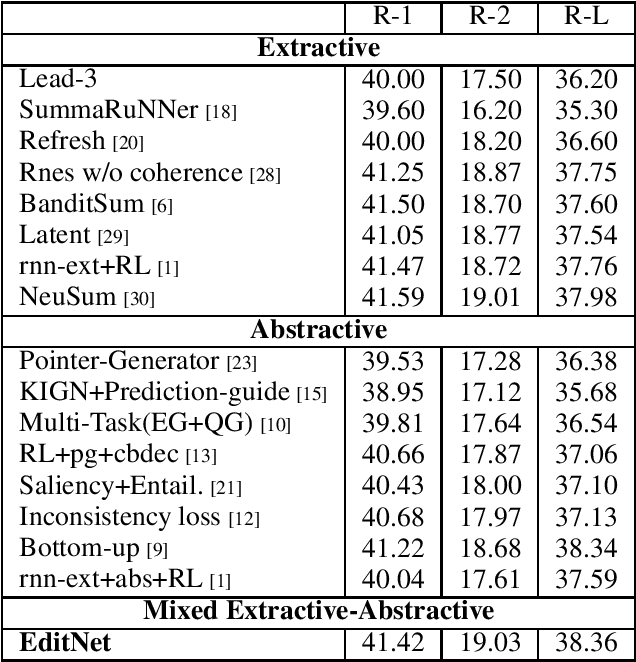

We suggest a new idea of Editorial Network - a mixed extractive-abstractive summarization approach, which is applied as a post-processing step over a given sequence of extracted sentences. Our network tries to imitate the decision process of a human editor during summarization. Within such a process, each extracted sentence may be either kept untouched, rephrased or completely rejected. We further suggest an effective way for training the "editor" based on a novel soft-labeling approach. Using the CNN/DailyMail dataset we demonstrate the effectiveness of our approach compared to state-of-the-art extractive-only or abstractive-only baseline methods.
Unsupervised Dual-Cascade Learning with Pseudo-Feedback Distillation for Query-based Extractive Summarization
Nov 01, 2018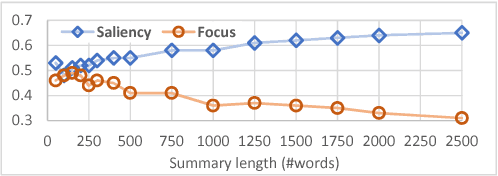
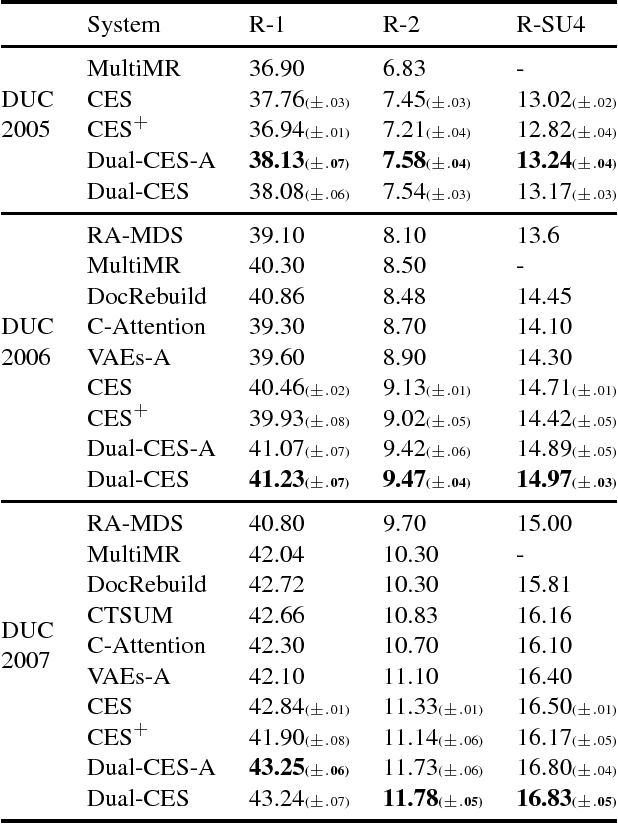
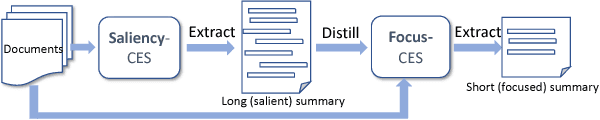
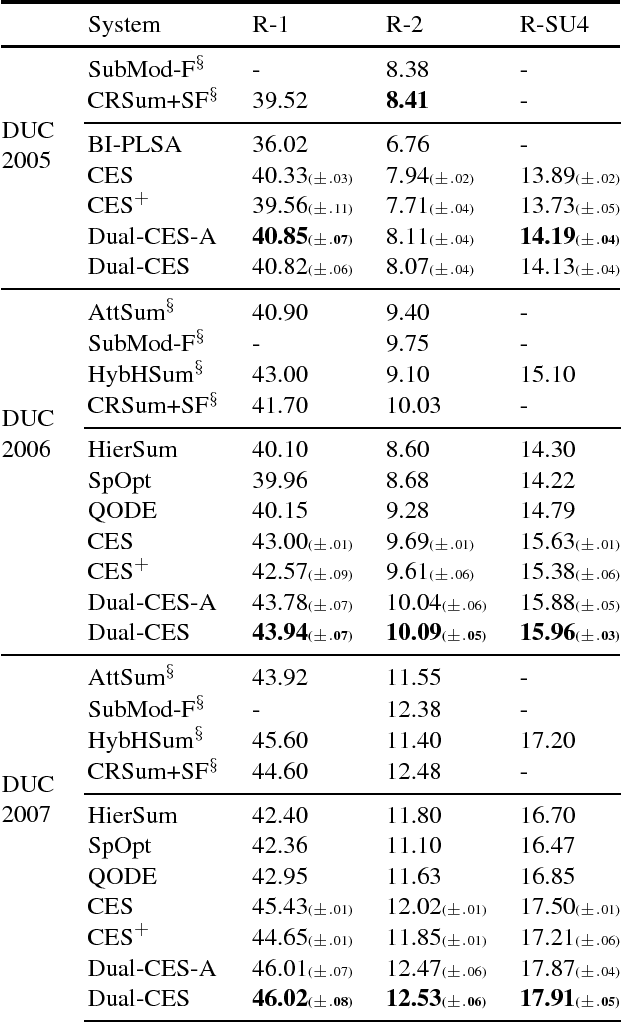
We propose Dual-CES -- a novel unsupervised, query-focused, multi-document extractive summarizer. Dual-CES is designed to better handle the tradeoff between saliency and focus in summarization. To this end, Dual-CES employs a two-step dual-cascade optimization approach with saliency-based pseudo-feedback distillation. Overall, Dual-CES significantly outperforms all other state-of-the-art unsupervised alternatives. Dual-CES is even shown to be able to outperform strong supervised summarizers.