 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Causal Framework for Mitigating Data Shifts in Healthcare
Mar 13, 2026Developing predictive models that perform reliably across diverse patient populations and heterogeneous environments is a core aim of medical research. However, generalization is only possible if the learned model is robust to statistical differences between data used for training and data seen at the time and place of deployment. Domain generalization methods provide strategies to address data shifts, but each method comes with its own set of assumptions and trade-offs. To apply these methods in healthcare, we must understand how domain shifts arise, what assumptions we prefer to make, and what our design constraints are. This article proposes a causal framework for the design of predictive models to improve generalization. Causality provides a powerful language to characterize and understand diverse domain shifts, regardless of data modality. This allows us to pinpoint why models fail to generalize, leading to more principled strategies to prepare for and adapt to shifts. We recommend general mitigation strategies, discussing trade-offs and highlighting existing work. Our causality-based perspective offers a critical foundation for developing robust, interpretable, and clinically relevant AI solutions in healthcare, paving the way for reliable real-world deployment.
Optimal L2 Regularization in High-dimensional Continual Linear Regression
Jan 20, 2026We study generalization in an overparameterized continual linear regression setting, where a model is trained with L2 (isotropic) regularization across a sequence of tasks. We derive a closed-form expression for the expected generalization loss in the high-dimensional regime that holds for arbitrary linear teachers. We demonstrate that isotropic regularization mitigates label noise under both single-teacher and multiple i.i.d. teacher settings, whereas prior work accommodating multiple teachers either did not employ regularization or used memory-demanding methods. Furthermore, we prove that the optimal fixed regularization strength scales nearly linearly with the number of tasks $T$, specifically as $T/\ln T$. To our knowledge, this is the first such result in theoretical continual learning. Finally, we validate our theoretical findings through experiments on linear regression and neural networks, illustrating how this scaling law affects generalization and offering a practical recipe for the design of continual learning systems.
CRCE: Coreference-Retention Concept Erasure in Text-to-Image Diffusion Models
Mar 18, 2025Text-to-Image diffusion models can produce undesirable content that necessitates concept erasure techniques. However, existing methods struggle with under-erasure, leaving residual traces of targeted concepts, or over-erasure, mistakenly eliminating unrelated but visually similar concepts. To address these limitations, we introduce CRCE, a novel concept erasure framework that leverages Large Language Models to identify both semantically related concepts that should be erased alongside the target and distinct concepts that should be preserved. By explicitly modeling coreferential and retained concepts semantically, CRCE enables more precise concept removal, without unintended erasure. Experiments demonstrate that CRCE outperforms existing methods on diverse erasure tasks.
Continual Learning in Linear Classification on Separable Data
Jun 06, 2023We analyze continual learning on a sequence of separable linear classification tasks with binary labels. We show theoretically that learning with weak regularization reduces to solving a sequential max-margin problem, corresponding to a special case of the Projection Onto Convex Sets (POCS) framework. We then develop upper bounds on the forgetting and other quantities of interest under various settings with recurring tasks, including cyclic and random orderings of tasks. We discuss several practical implications to popular training practices like regularization scheduling and weighting. We point out several theoretical differences between our continual classification setting and a recently studied continual regression setting.
How catastrophic can catastrophic forgetting be in linear regression?
May 25, 2022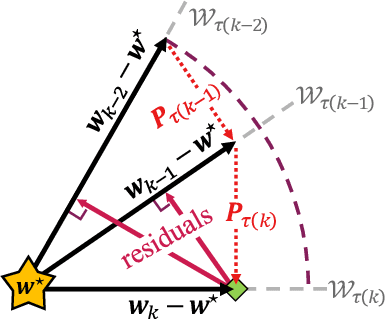
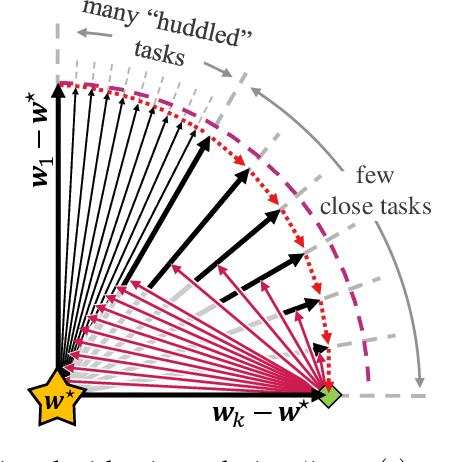
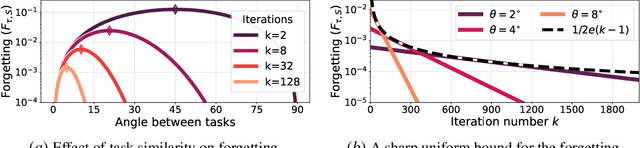
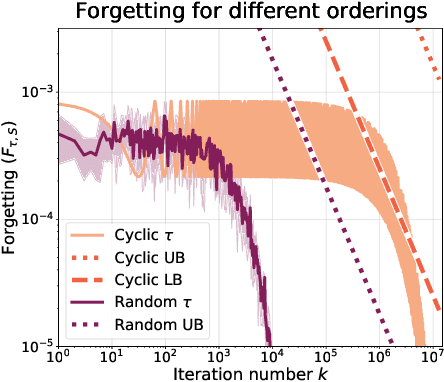
To better understand catastrophic forgetting, we study fitting an overparameterized linear model to a sequence of tasks with different input distributions. We analyze how much the model forgets the true labels of earlier tasks after training on subsequent tasks, obtaining exact expressions and bounds. We establish connections between continual learning in the linear setting and two other research areas: alternating projections and the Kaczmarz method. In specific settings, we highlight differences between forgetting and convergence to the offline solution as studied in those areas. In particular, when T tasks in d dimensions are presented cyclically for k iterations, we prove an upper bound of T^2 * min{1/sqrt(k), d/k} on the forgetting. This stands in contrast to the convergence to the offline solution, which can be arbitrarily slow according to existing alternating projection results. We further show that the T^2 factor can be lifted when tasks are presented in a random ordering.
On the Implicit Bias of Initialization Shape: Beyond Infinitesimal Mirror Descent
Feb 19, 2021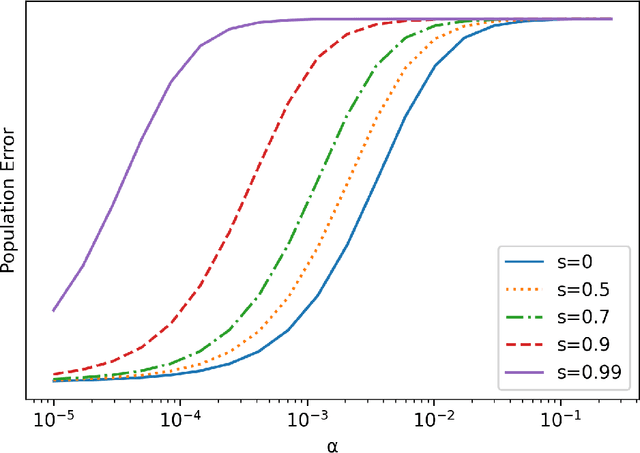
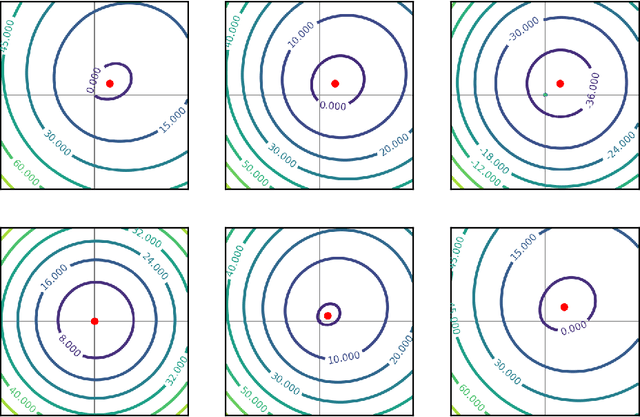
Recent work has highlighted the role of initialization scale in determining the structure of the solutions that gradient methods converge to. In particular, it was shown that large initialization leads to the neural tangent kernel regime solution, whereas small initialization leads to so called "rich regimes". However, the initialization structure is richer than the overall scale alone and involves relative magnitudes of different weights and layers in the network. Here we show that these relative scales, which we refer to as initialization shape, play an important role in determining the learned model. We develop a novel technique for deriving the inductive bias of gradient-flow and use it to obtain closed-form implicit regularizers for multiple cases of interest.
Implicit Bias in Deep Linear Classification: Initialization Scale vs Training Accuracy
Jul 13, 2020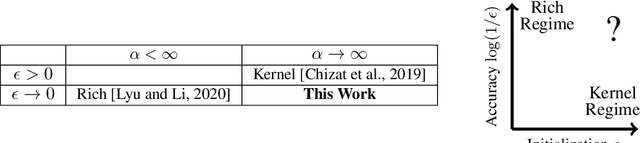

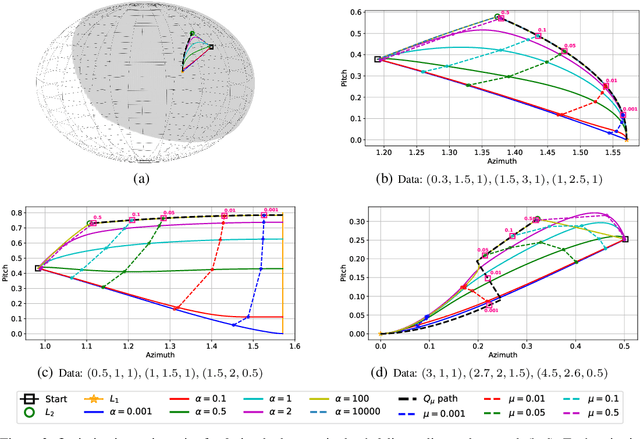
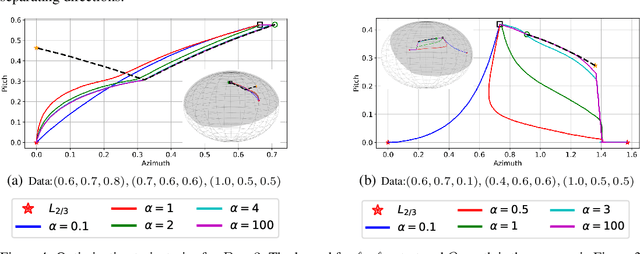
We provide a detailed asymptotic study of gradient flow trajectories and their implicit optimization bias when minimizing the exponential loss over "diagonal linear networks". This is the simplest model displaying a transition between "kernel" and non-kernel ("rich" or "active") regimes. We show how the transition is controlled by the relationship between the initialization scale and how accurately we minimize the training loss. Our results indicate that some limit behaviors of gradient descent only kick in at ridiculous training accuracies (well beyond $10^{-100}$). Moreover, the implicit bias at reasonable initialization scales and training accuracies is more complex and not captured by these limits.
Kernel and Rich Regimes in Overparametrized Models
Feb 24, 2020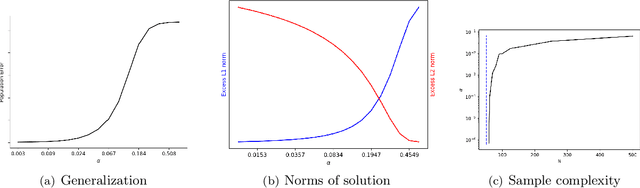
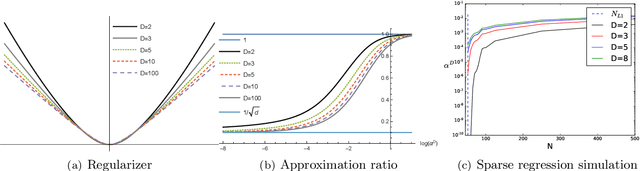
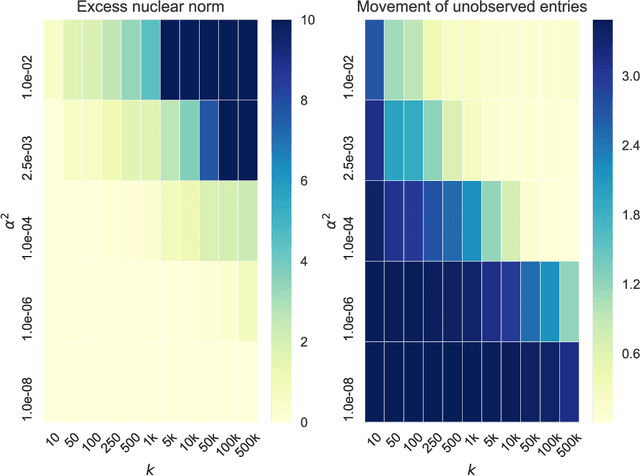
A recent line of work studies overparametrized neural networks in the "kernel regime," i.e. when the network behaves during training as a kernelized linear predictor, and thus training with gradient descent has the effect of finding the minimum RKHS norm solution. This stands in contrast to other studies which demonstrate how gradient descent on overparametrized multilayer networks can induce rich implicit biases that are not RKHS norms. Building on an observation by Chizat and Bach, we show how the scale of the initialization controls the transition between the "kernel" (aka lazy) and "rich" (aka active) regimes and affects generalization properties in multilayer homogeneous models. We also highlight an interesting role for the width of a model in the case that the predictor is not identically zero at initialization. We provide a complete and detailed analysis for a family of simple depth-$D$ models that already exhibit an interesting and meaningful transition between the kernel and rich regimes, and we also demonstrate this transition empirically for more complex matrix factorization models and multilayer non-linear networks.
Variance Estimation For Online Regression via Spectrum Thresholding
Jun 13, 2019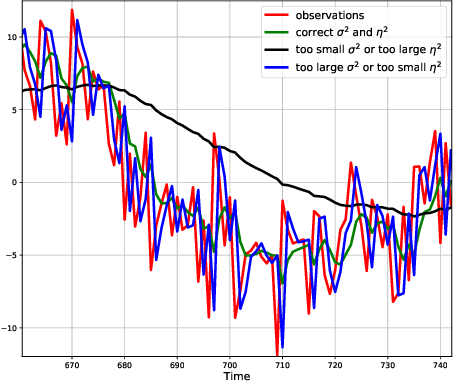
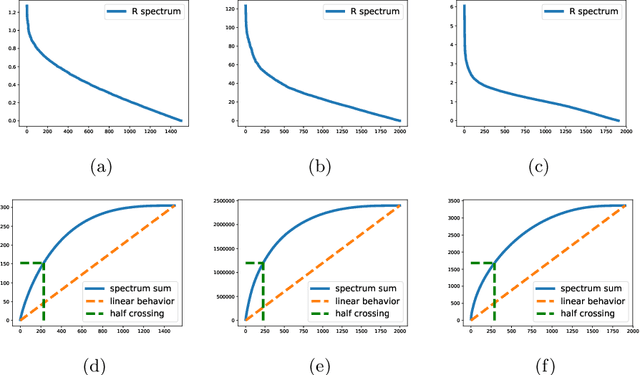
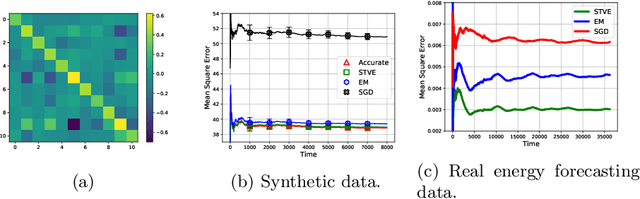
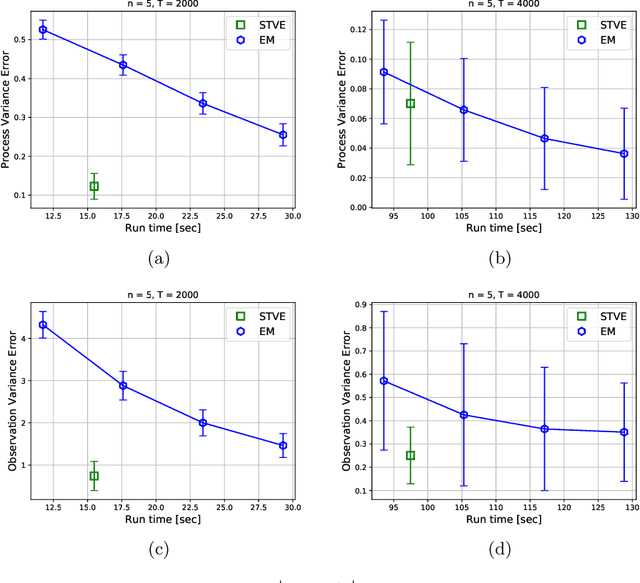
We consider the online linear regression problem, where the predictor vector may vary with time. This problem can be modelled as a linear dynamical system, where the parameters that need to be learned are the variance of both the process noise and the observation noise. The classical approach to learning the variance is via the maximum likelihood estimator -- a non-convex optimization problem prone to local minima and with no finite sample complexity bounds. In this paper we study the global system operator: the operator that maps the noises vectors to the output. In particular, we obtain estimates on its spectrum, and as a result derive the first known variance estimators with sample complexity guarantees for online regression problems. We demonstrate the approach on a number of synthetic and real-world benchmarks.
An Editorial Network for Enhanced Document Summarization
Feb 27, 2019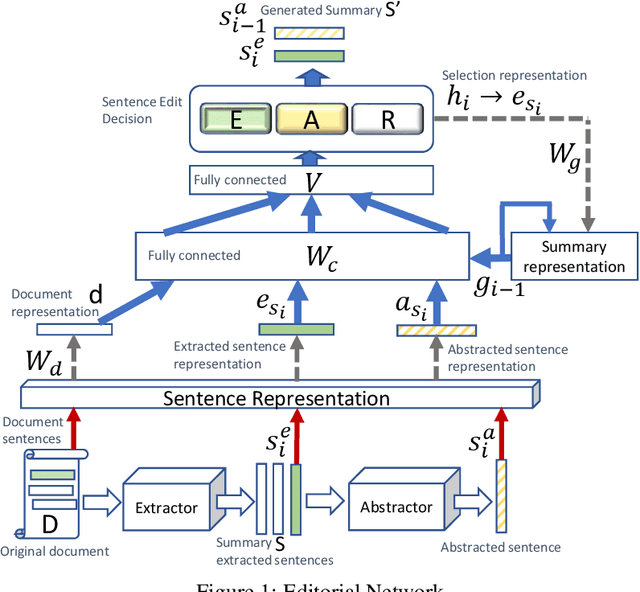
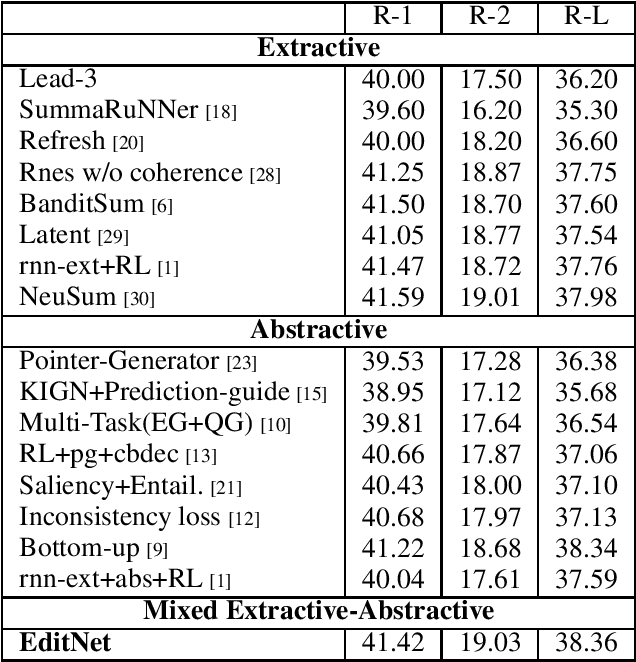

We suggest a new idea of Editorial Network - a mixed extractive-abstractive summarization approach, which is applied as a post-processing step over a given sequence of extracted sentences. Our network tries to imitate the decision process of a human editor during summarization. Within such a process, each extracted sentence may be either kept untouched, rephrased or completely rejected. We further suggest an effective way for training the "editor" based on a novel soft-labeling approach. Using the CNN/DailyMail dataset we demonstrate the effectiveness of our approach compared to state-of-the-art extractive-only or abstractive-only baseline methods.