 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI-CAM-UV: Integrating Causal Graphs over Non-Identical Variable Sets Using Causal Additive Models with Unobserved Variables
Mar 03, 2026Causal discovery from observational data is a fundamental tool in various fields of science. While existing approaches are typically designed for a single dataset, we often need to handle multiple datasets with non-identical variable sets in practice. One straightforward approach is to estimate a causal graph from each dataset and construct a single causal graph by overlapping. However, this approach identifies limited causal relationships because unobserved variables in each dataset can be confounders, and some variable pairs may be unobserved in any dataset. To address this issue, we leverage Causal Additive Models with Unobserved Variables (CAM-UV) that provide causal graphs having information related to unobserved variables. We show that the ground truth causal graph has structural consistency with the information of CAM-UV on each dataset. As a result, we propose an approach named I-CAM-UV to integrate CAM-UV results by enumerating all consistent causal graphs. We also provide an efficient combinatorial search algorithm and demonstrate the usefulness of I-CAM-UV against existing methods.
Sparse Additive Model Pruning for Order-Based Causal Structure Learning
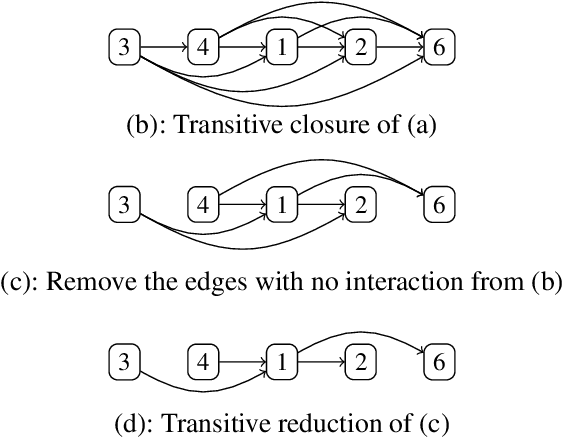
Feb 17, 2026Causal structure learning, also known as causal discovery, aims to estimate causal relationships between variables as a form of a causal directed acyclic graph (DAG) from observational data. One of the major frameworks is the order-based approach that first estimates a topological order of the underlying DAG and then prunes spurious edges from the fully-connected DAG induced by the estimated topological order. Previous studies often focus on the former ordering step because it can dramatically reduce the search space of DAGs. In practice, the latter pruning step is equally crucial for ensuring both computational efficiency and estimation accuracy. Most existing methods employ a pruning technique based on generalized additive models and hypothesis testing, commonly known as CAM-pruning. However, this approach can be a computational bottleneck as it requires repeatedly fitting additive models for all variables. Furthermore, it may harm estimation quality due to multiple testing. To address these issues, we introduce a new pruning method based on sparse additive models, which enables direct pruning of redundant edges without relying on hypothesis testing. We propose an efficient algorithm for learning sparse additive models by combining the randomized tree embedding technique with group-wise sparse regression. Experimental results on both synthetic and real datasets demonstrated that our method is significantly faster than existing pruning methods while maintaining comparable or superior accuracy.
Learning Decision Trees and Forests with Algorithmic Recourse
Jun 03, 2024
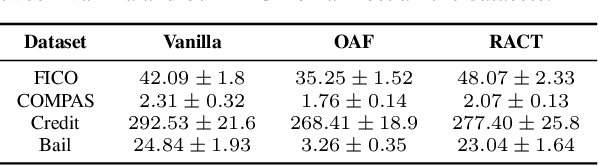
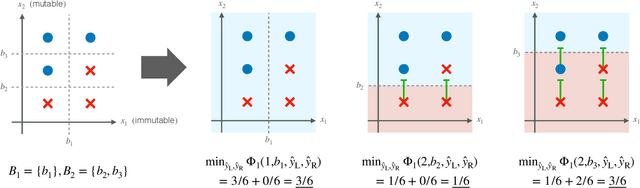
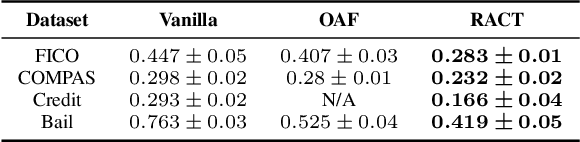
This paper proposes a new algorithm for learning accurate tree-based models while ensuring the existence of recourse actions. Algorithmic Recourse (AR) aims to provide a recourse action for altering the undesired prediction result given by a model. Typical AR methods provide a reasonable action by solving an optimization task of minimizing the required effort among executable actions. In practice, however, such actions do not always exist for models optimized only for predictive performance. To alleviate this issue, we formulate the task of learning an accurate classification tree under the constraint of ensuring the existence of reasonable actions for as many instances as possible. Then, we propose an efficient top-down greedy algorithm by leveraging the adversarial training techniques. We also show that our proposed algorithm can be applied to the random forest, which is known as a popular framework for learning tree ensembles. Experimental results demonstrated that our method successfully provided reasonable actions to more instances than the baselines without significantly degrading accuracy and computational efficiency.
Rule Mining for Correcting Classification Models
Oct 14, 2023Machine learning models need to be continually updated or corrected to ensure that the prediction accuracy remains consistently high. In this study, we consider scenarios where developers should be careful to change the prediction results by the model correction, such as when the model is part of a complex system or software. In such scenarios, the developers want to control the specification of the corrections. To achieve this, the developers need to understand which subpopulations of the inputs get inaccurate predictions by the model. Therefore, we propose correction rule mining to acquire a comprehensive list of rules that describe inaccurate subpopulations and how to correct them. We also develop an efficient correction rule mining algorithm that is a combination of frequent itemset mining and a unique pruning technique for correction rules. We observed that the proposed algorithm found various rules which help to collect data insufficiently learned, directly correct model outputs, and analyze concept drift.
Counterfactual Explanation with Missing Values
Apr 28, 2023
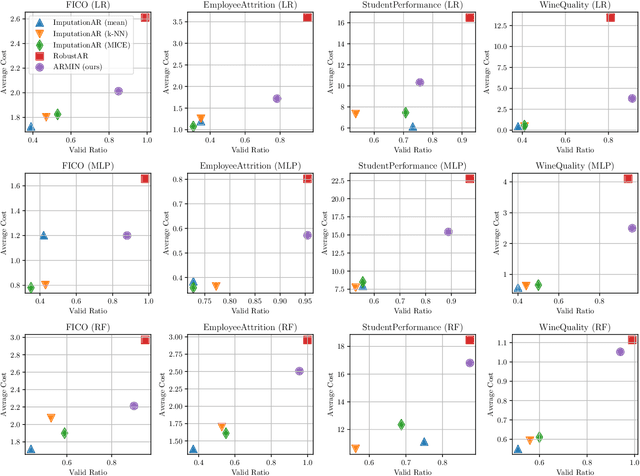
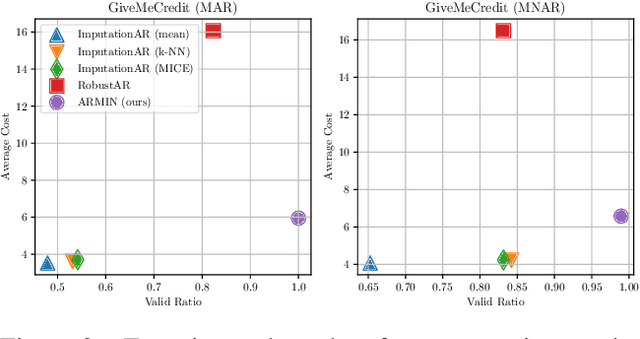
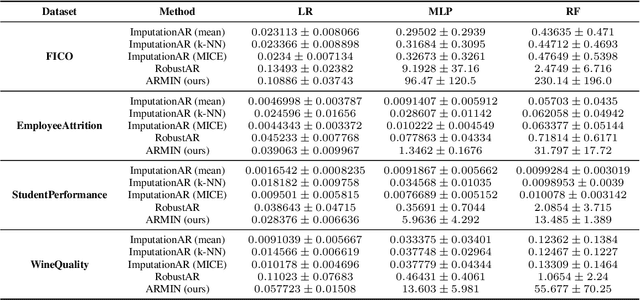
Counterfactual Explanation (CE) is a post-hoc explanation method that provides a perturbation for altering the prediction result of a classifier. Users can interpret the perturbation as an "action" to obtain their desired decision results. Existing CE methods require complete information on the features of an input instance. However, we often encounter missing values in a given instance, and the previous methods do not work in such a practical situation. In this paper, we first empirically and theoretically show the risk that missing value imputation methods affect the validity of an action, as well as the features that the action suggests changing. Then, we propose a new framework of CE, named Counterfactual Explanation by Pairs of Imputation and Action (CEPIA), that enables users to obtain valid actions even with missing values and clarifies how actions are affected by imputation of the missing values. Specifically, our CEPIA provides a representative set of pairs of an imputation candidate for a given incomplete instance and its optimal action. We formulate the problem of finding such a set as a submodular maximization problem, which can be solved by a simple greedy algorithm with an approximation guarantee. Experimental results demonstrated the efficacy of our CEPIA in comparison with the baselines in the presence of missing values.
TimberTrek: Exploring and Curating Sparse Decision Trees with Interactive Visualization
Sep 19, 2022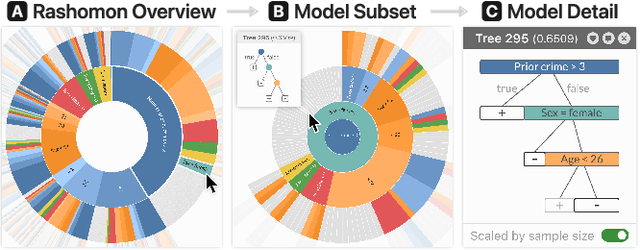
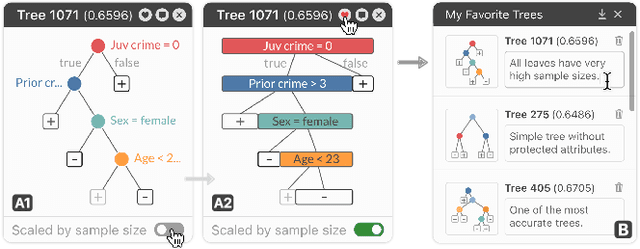
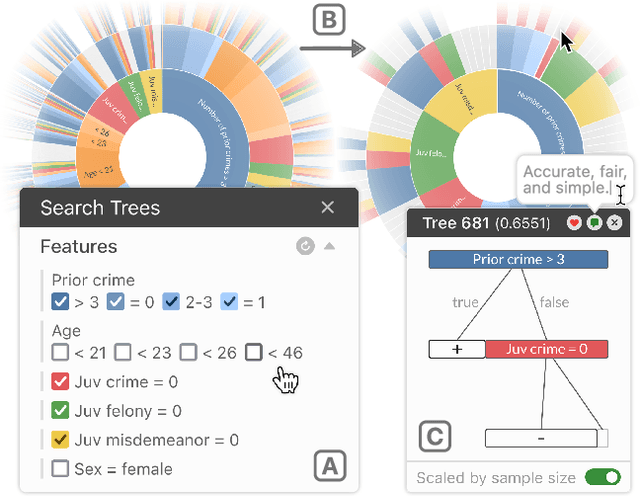
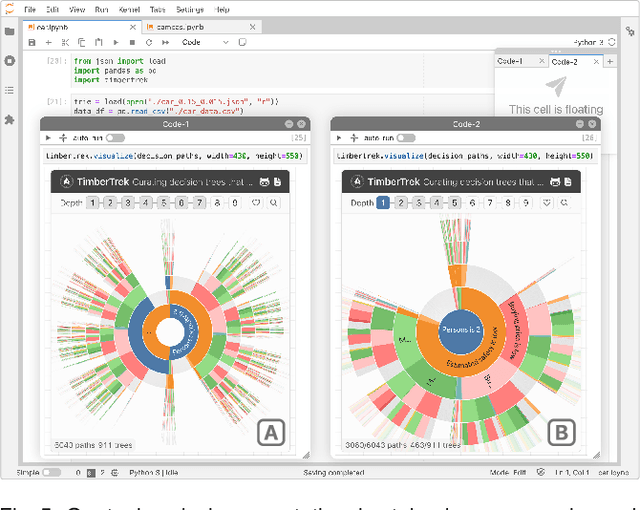
Given thousands of equally accurate machine learning (ML) models, how can users choose among them? A recent ML technique enables domain experts and data scientists to generate a complete Rashomon set for sparse decision trees--a huge set of almost-optimal interpretable ML models. To help ML practitioners identify models with desirable properties from this Rashomon set, we develop TimberTrek, the first interactive visualization system that summarizes thousands of sparse decision trees at scale. Two usage scenarios highlight how TimberTrek can empower users to easily explore, compare, and curate models that align with their domain knowledge and values. Our open-source tool runs directly in users' computational notebooks and web browsers, lowering the barrier to creating more responsible ML models. TimberTrek is available at the following public demo link: https://poloclub.github.io/timbertrek.
Exploring the Whole Rashomon Set of Sparse Decision Trees
Sep 16, 2022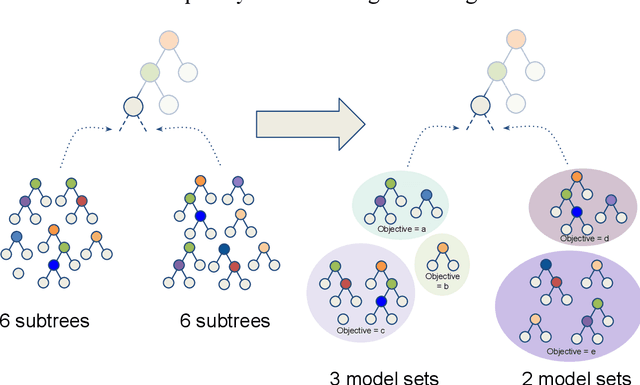
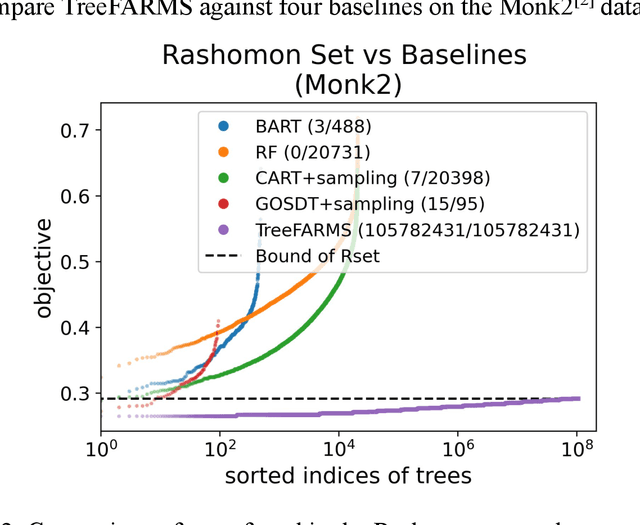
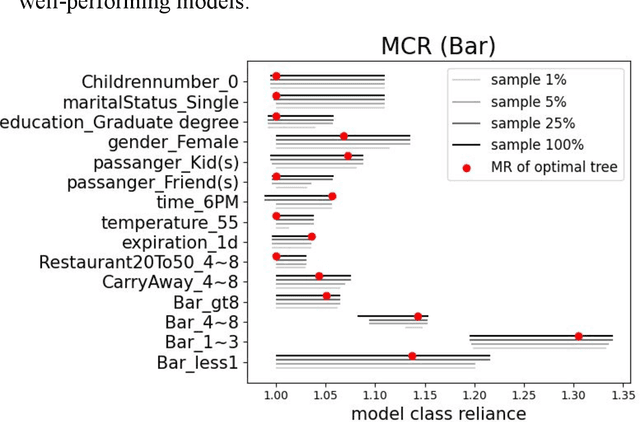
In any given machine learning problem, there may be many models that could explain the data almost equally well. However, most learning algorithms return only one of these models, leaving practitioners with no practical way to explore alternative models that might have desirable properties beyond what could be expressed within a loss function. The Rashomon set is the set of these all almost-optimal models. Rashomon sets can be extremely complicated, particularly for highly nonlinear function classes that allow complex interaction terms, such as decision trees. We provide the first technique for completely enumerating the Rashomon set for sparse decision trees; in fact, our work provides the first complete enumeration of any Rashomon set for a non-trivial problem with a highly nonlinear discrete function class. This allows the user an unprecedented level of control over model choice among all models that are approximately equally good. We represent the Rashomon set in a specialized data structure that supports efficient querying and sampling. We show three applications of the Rashomon set: 1) it can be used to study variable importance for the set of almost-optimal trees (as opposed to a single tree), 2) the Rashomon set for accuracy enables enumeration of the Rashomon sets for balanced accuracy and F1-score, and 3) the Rashomon set for a full dataset can be used to produce Rashomon sets constructed with only subsets of the data set. Thus, we are able to examine Rashomon sets across problems with a new lens, enabling users to choose models rather than be at the mercy of an algorithm that produces only a single model.
Ordered Counterfactual Explanation by Mixed-Integer Linear Optimization
Dec 22, 2020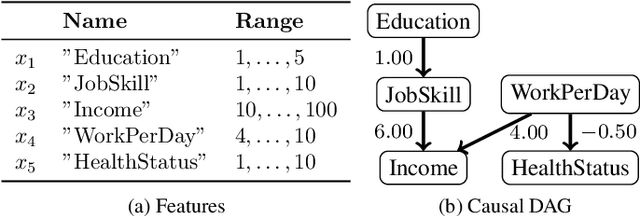

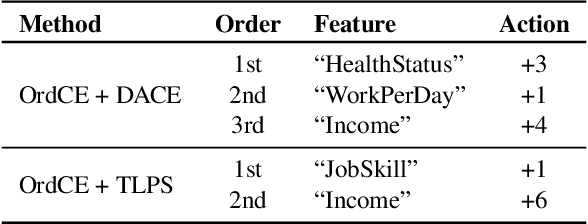
Post-hoc explanation methods for machine learning models have been widely used to support decision-making. One of the popular methods is Counterfactual Explanation (CE), which provides a user with a perturbation vector of features that alters the prediction result. Given a perturbation vector, a user can interpret it as an "action" for obtaining one's desired decision result. In practice, however, showing only a perturbation vector is often insufficient for users to execute the action. The reason is that if there is an asymmetric interaction among features, such as causality, the total cost of the action is expected to depend on the order of changing features. Therefore, practical CE methods are required to provide an appropriate order of changing features in addition to a perturbation vector. For this purpose, we propose a new framework called Ordered Counterfactual Explanation (OrdCE). We introduce a new objective function that evaluates a pair of an action and an order based on feature interaction. To extract an optimal pair, we propose a mixed-integer linear optimization approach with our objective function. Numerical experiments on real datasets demonstrated the effectiveness of our OrdCE in comparison with unordered CE methods.
Multi Instance Learning For Unbalanced Data
Dec 17, 2018
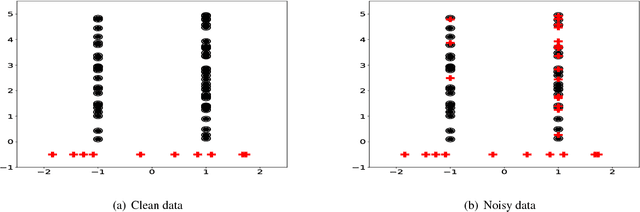
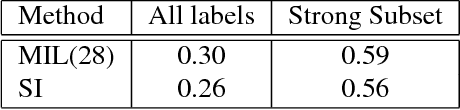
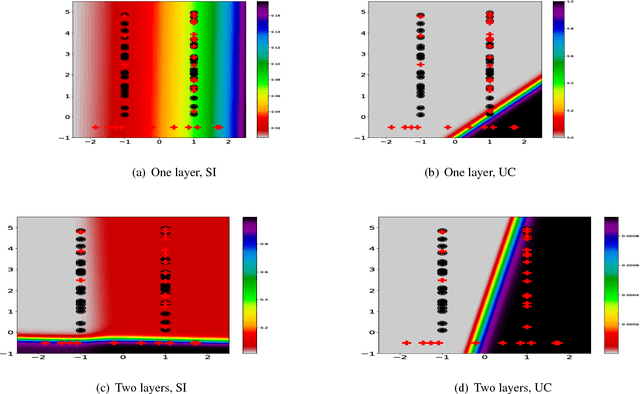
In the context of Multi Instance Learning, we analyze the Single Instance (SI) learning objective. We show that when the data is unbalanced and the family of classifiers is sufficiently rich, the SI method is a useful learning algorithm. In particular, we show that larger data imbalance, a quality that is typically perceived as negative, in fact implies a better resilience of the algorithm to the statistical dependencies of the objects in bags. In addition, our results shed new light on some known issues with the SI method in the setting of linear classifiers, and we show that these issues are significantly less likely to occur in the setting of neural networks. We demonstrate our results on a synthetic dataset, and on the COCO dataset for the problem of patch classification with weak image level labels derived from captions.