 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere You Inject Diversity Matters: A Unified Framework for Diverse Generation
Jun 09, 2026Open-ended generation tasks often require a set of meaningfully different outputs, yet large language models often produce similar generations. Existing test-time diversity methods operate at different stages of generation with varying effectiveness, but it remains unclear what design choices lead to meaningful diversity in the output. We introduce a framework that characterizes test-time diverse generation methods by the diversity source introduced during generation and provide a transmission score for measuring how effectively variation in the source reaches the final output. Guided by this framework, we propose fully automated specification-level generation methods that first generate diverse intermediate specifications and then condition on them to produce final responses. Across five open-ended tasks and four backbone models, specification-level injection improves output diversity over test-time baselines while maintaining comparable quality. Our analysis shows that successful diversity injection depends on both the diversity of the sources and their transmission to the output, highlighting source design and source-to-output realization as two key levers for building more diverse generation systems.
EvoLM: Self-Evolving Language Models through Co-Evolved Discriminative Rubrics
May 05, 2026Language models encode substantial evaluative knowledge from pretraining, yet current post-training methods rely on external supervision (human annotations, proprietary models, or scalar reward models) to produce reward signals. Each imposes a ceiling. Human judgment cannot supervise capabilities beyond its own, proprietary APIs create dependencies, and verifiable rewards cover only domains with ground-truth answers. Self-improvement from a model's own evaluative capacity is a reward source that scales with the model itself, yet remains largely untapped by current methods. We introduce EVOLM, a post-training method that structures this capacity into explicit discriminative rubrics and uses them as training signal. EVOLM trains two capabilities within a single language model in alternation: (1) a rubric generator producing instance-specific evaluation criteria optimized for discriminative utility, which maximizes a small frozen judge's ability to distinguish preferred from dispreferred responses; and (2) a policy trained using those rubric-conditioned scores as reward. All preference signals are constructed from the policy's own outputs via temporal contrast with earlier checkpoints, requiring no human annotation or external supervision. EVOLM trains a Qwen3-8B model to generate rubrics that outperform GPT-4.1 on RewardBench-2 by 25.7%. The co-trained policy achieves 69.3% average on the OLMo3-Adapt suite, outperforming policies trained with GPT-4.1 prompted rubrics by 3.9% and with the state-of-the-art 8B reward model SkyWork-RM by 16%. Overall, EVOLM demonstrates that structuring a model's evaluative capacity into co-evolving discriminative rubrics enables self-improvement without external supervision.
Privasis: Synthesizing the Largest "Public" Private Dataset from Scratch
Feb 03, 2026Research involving privacy-sensitive data has always been constrained by data scarcity, standing in sharp contrast to other areas that have benefited from data scaling. This challenge is becoming increasingly urgent as modern AI agents--such as OpenClaw and Gemini Agent--are granted persistent access to highly sensitive personal information. To tackle this longstanding bottleneck and the rising risks, we present Privasis (i.e., privacy oasis), the first million-scale fully synthetic dataset entirely built from scratch--an expansive reservoir of texts with rich and diverse private information--designed to broaden and accelerate research in areas where processing sensitive social data is inevitable. Compared to existing datasets, Privasis, comprising 1.4 million records, offers orders-of-magnitude larger scale with quality, and far greater diversity across various document types, including medical history, legal documents, financial records, calendars, and text messages with a total of 55.1 million annotated attributes such as ethnicity, date of birth, workplace, etc. We leverage Privasis to construct a parallel corpus for text sanitization with our pipeline that decomposes texts and applies targeted sanitization. Our compact sanitization models (<=4B) trained on this dataset outperform state-of-the-art large language models, such as GPT-5 and Qwen-3 235B. We plan to release data, models, and code to accelerate future research on privacy-sensitive domains and agents.
Just-in-Time Catching Test Generation at Meta
Jan 30, 2026We report on Just-in-Time catching test generation at Meta, designed to prevent bugs in large scale backend systems of hundreds of millions of line of code. Unlike traditional hardening tests, which pass at generation time, catching tests are meant to fail, surfacing bugs before code lands. The primary challenge is to reduce development drag from false positive test failures. Analyzing 22,126 generated tests, we show code-change-aware methods improve candidate catch generation 4x over hardening tests and 20x over coincidentally failing tests. To address false positives, we use rule-based and LLM-based assessors. These assessors reduce human review load by 70%. Inferential statistical analysis showed that human-accepted code changes are assessed to have significantly more false positives, while human-rejected changes have significantly more true positives. We reported 41 candidate catches to engineers; 8 were confirmed to be true positives, 4 of which would have led to serious failures had they remained uncaught. Overall, our results show that Just-in-Time catching is scalable, industrially applicable, and that it prevents serious failures from reaching production.
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Spurious Rewards: Rethinking Training Signals in RLVR
Jun 12, 2025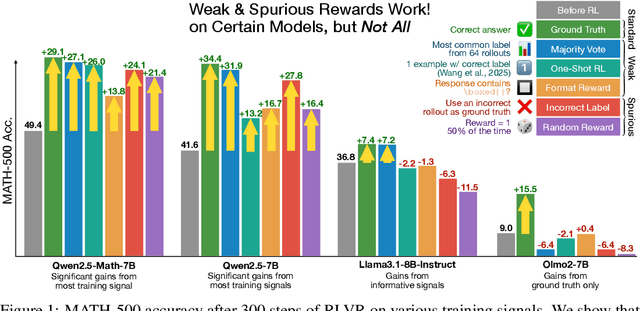
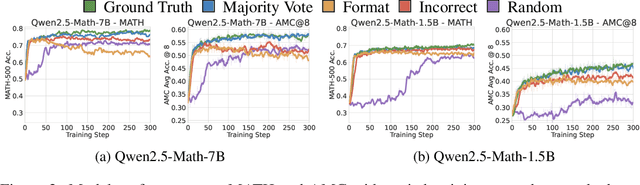
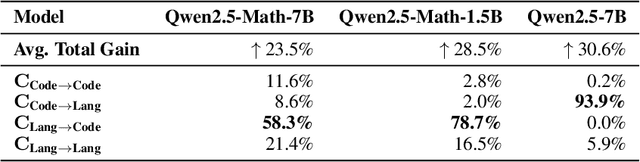
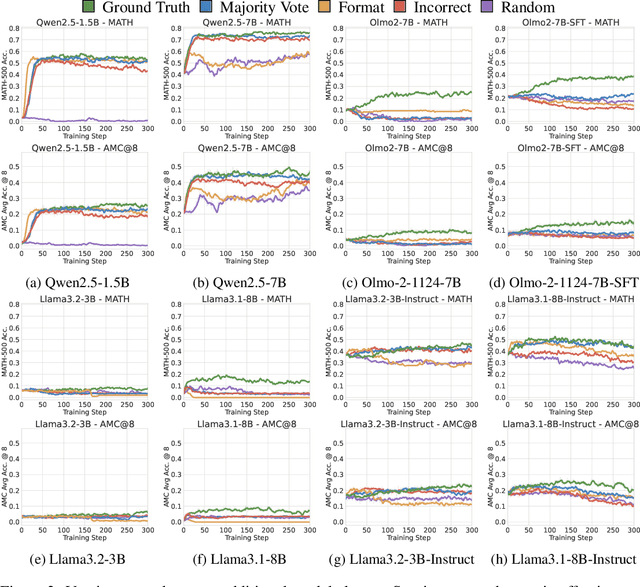
We show that reinforcement learning with verifiable rewards (RLVR) can elicit strong mathematical reasoning in certain models even with spurious rewards that have little, no, or even negative correlation with the correct answer. For example, RLVR improves MATH-500 performance for Qwen2.5-Math-7B in absolute points by 21.4% (random reward), 13.8% (format reward), 24.1% (incorrect label), 26.0% (1-shot RL), and 27.1% (majority voting) -- nearly matching the 29.1% gained with ground truth rewards. However, the spurious rewards that work for Qwen often fail to yield gains with other model families like Llama3 or OLMo2. In particular, we find code reasoning -- thinking in code without actual code execution -- to be a distinctive Qwen2.5-Math behavior that becomes significantly more frequent after RLVR, from 65% to over 90%, even with spurious rewards. Overall, we hypothesize that, given the lack of useful reward signal, RLVR must somehow be surfacing useful reasoning representations learned during pretraining, although the exact mechanism remains a topic for future work. We suggest that future RLVR research should possibly be validated on diverse models rather than a single de facto choice, as we show that it is easy to get significant performance gains on Qwen models even with completely spurious reward signals.
A False Sense of Privacy: Evaluating Textual Data Sanitization Beyond Surface-level Privacy Leakage
Apr 28, 2025Sanitizing sensitive text data typically involves removing personally identifiable information (PII) or generating synthetic data under the assumption that these methods adequately protect privacy; however, their effectiveness is often only assessed by measuring the leakage of explicit identifiers but ignoring nuanced textual markers that can lead to re-identification. We challenge the above illusion of privacy by proposing a new framework that evaluates re-identification attacks to quantify individual privacy risks upon data release. Our approach shows that seemingly innocuous auxiliary information -- such as routine social activities -- can be used to infer sensitive attributes like age or substance use history from sanitized data. For instance, we demonstrate that Azure's commercial PII removal tool fails to protect 74\% of information in the MedQA dataset. Although differential privacy mitigates these risks to some extent, it significantly reduces the utility of the sanitized text for downstream tasks. Our findings indicate that current sanitization techniques offer a \textit{false sense of privacy}, highlighting the need for more robust methods that protect against semantic-level information leakage.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Language models scale reliably with over-training and on downstream tasks
Mar 13, 2024



Scaling laws are useful guides for developing language models, but there are still gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., "Chinchilla optimal" regime); however, in practice, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but ultimately models are compared based on downstream task performance. In this paper, we address both shortcomings. To do so, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we investigate scaling in the over-trained regime. We fit scaling laws that extrapolate in both the number of model parameters and the ratio of training tokens to parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$\times$ over-trained) and a 6.9B parameter, 138B token run$\unicode{x2014}$each from experiments that take 300$\times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance via a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models using experiments that take 20$\times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
Optimal Sparse Survival Trees
Jan 27, 2024



Interpretability is crucial for doctors, hospitals, pharmaceutical companies and biotechnology corporations to analyze and make decisions for high stakes problems that involve human health. Tree-based methods have been widely adopted for \textit{survival analysis} due to their appealing interpretablility and their ability to capture complex relationships. However, most existing methods to produce survival trees rely on heuristic (or greedy) algorithms, which risk producing sub-optimal models. We present a dynamic-programming-with-bounds approach that finds provably-optimal sparse survival tree models, frequently in only a few seconds.