 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterials Transformers Language Models for Generative Materials Design: a benchmark study
Paper and Code
Jun 27, 2022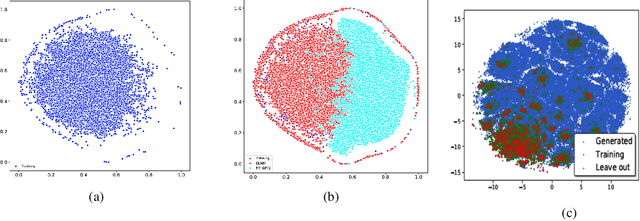
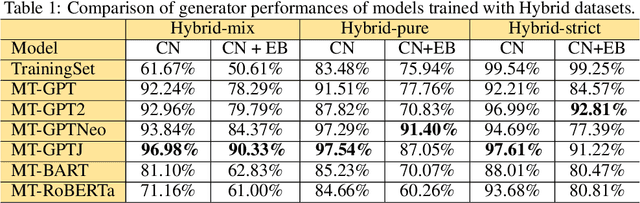
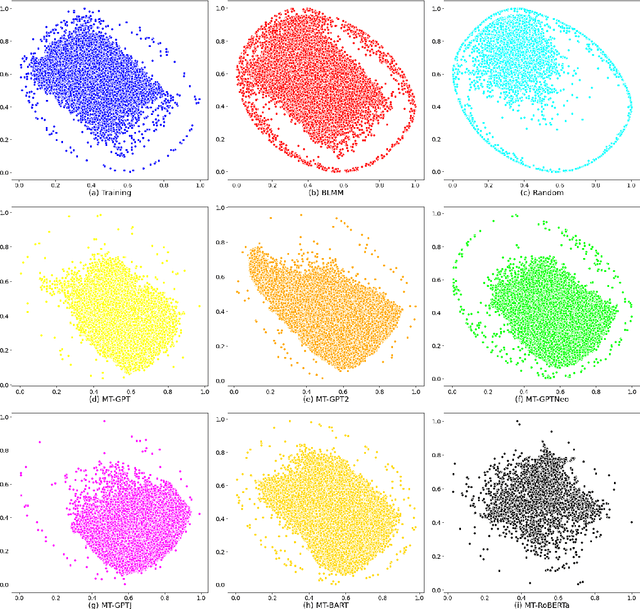
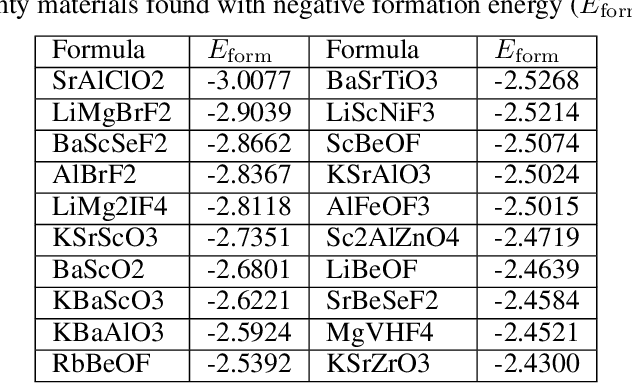
Pre-trained transformer language models on large unlabeled corpus have produced state-of-the-art results in natural language processing, organic molecule design, and protein sequence generation. However, no such models have been applied to learn the composition patterns of inorganic materials. Here we train a series of seven modern transformer language models (GPT, GPT-2, GPT-Neo, GPT-J, BLMM, BART, and RoBERTa) using the expanded formulas from material deposited in the ICSD, OQMD, and Materials Projects databases. Six different datasets with/out non-charge-neutral or balanced electronegativity samples are used to benchmark the performances and uncover the generation biases of modern transformer models for the generative design of materials compositions. Our extensive experiments showed that the causal language models based materials transformers can generate chemically valid materials compositions with as high as 97.54\% to be charge neutral and 91.40\% to be electronegativity balanced, which has more than 6 times higher enrichment compared to a baseline pseudo-random sampling algorithm. These models also demonstrate high novelty and their potential in new materials discovery has been proved by their capability to recover the leave-out materials. We also find that the properties of the generated samples can be tailored by training the models with selected training sets such as high-bandgap materials. Our experiments also showed that different models each have their own preference in terms of the properties of the generated samples and their running time complexity varies a lot. We have applied our materials transformer models to discover a set of new materials as validated using DFT calculations.