 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Generalizing Verifiable Instruction Following
Jul 03, 2025A crucial factor for successful human and AI interaction is the ability of language models or chatbots to follow human instructions precisely. A common feature of instructions are output constraints like ``only answer with yes or no" or ``mention the word `abrakadabra' at least 3 times" that the user adds to craft a more useful answer. Even today's strongest models struggle with fulfilling such constraints. We find that most models strongly overfit on a small set of verifiable constraints from the benchmarks that test these abilities, a skill called precise instruction following, and are not able to generalize well to unseen output constraints. We introduce a new benchmark, IFBench, to evaluate precise instruction following generalization on 58 new, diverse, and challenging verifiable out-of-domain constraints. In addition, we perform an extensive analysis of how and on what data models can be trained to improve precise instruction following generalization. Specifically, we carefully design constraint verification modules and show that reinforcement learning with verifiable rewards (RLVR) significantly improves instruction following. In addition to IFBench, we release 29 additional new hand-annotated training constraints and verification functions, RLVR training prompts, and code.
Spurious Rewards: Rethinking Training Signals in RLVR
Jun 12, 2025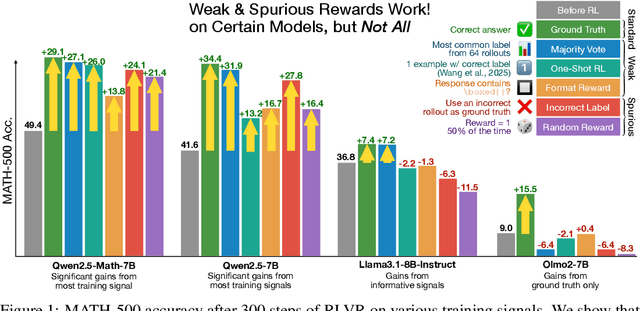
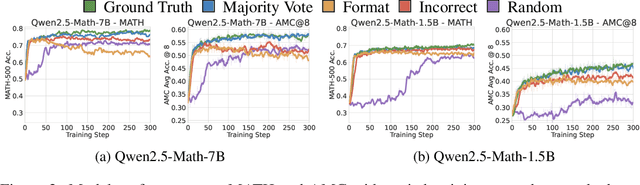
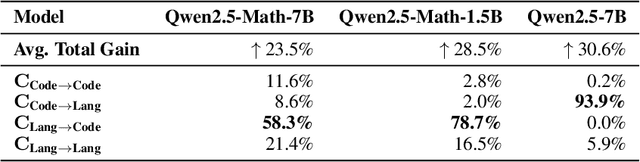
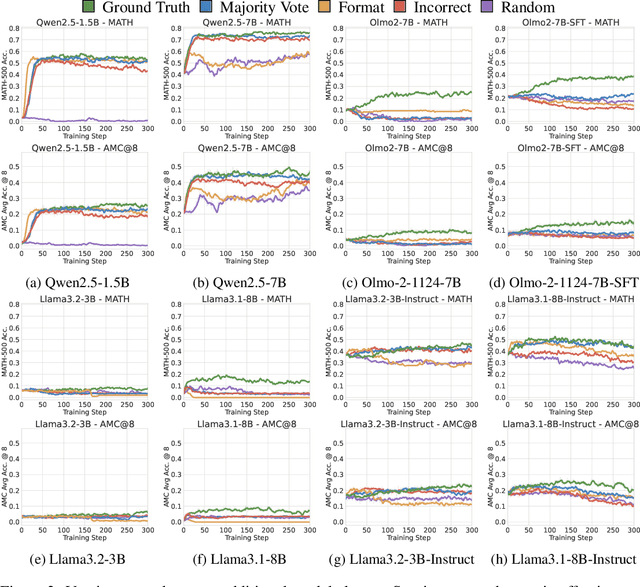
We show that reinforcement learning with verifiable rewards (RLVR) can elicit strong mathematical reasoning in certain models even with spurious rewards that have little, no, or even negative correlation with the correct answer. For example, RLVR improves MATH-500 performance for Qwen2.5-Math-7B in absolute points by 21.4% (random reward), 13.8% (format reward), 24.1% (incorrect label), 26.0% (1-shot RL), and 27.1% (majority voting) -- nearly matching the 29.1% gained with ground truth rewards. However, the spurious rewards that work for Qwen often fail to yield gains with other model families like Llama3 or OLMo2. In particular, we find code reasoning -- thinking in code without actual code execution -- to be a distinctive Qwen2.5-Math behavior that becomes significantly more frequent after RLVR, from 65% to over 90%, even with spurious rewards. Overall, we hypothesize that, given the lack of useful reward signal, RLVR must somehow be surfacing useful reasoning representations learned during pretraining, although the exact mechanism remains a topic for future work. We suggest that future RLVR research should possibly be validated on diverse models rather than a single de facto choice, as we show that it is easy to get significant performance gains on Qwen models even with completely spurious reward signals.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
Nov 22, 2024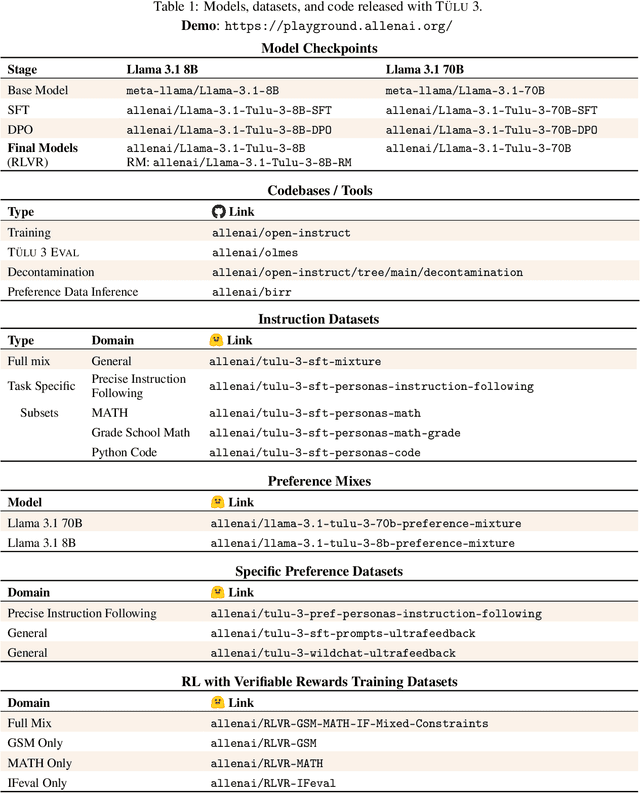



Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce T\"ULU 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. T\"ULU 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With T\"ULU 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the T\"ULU 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the T\"ULU 3 approach to more domains.
M-RewardBench: Evaluating Reward Models in Multilingual Settings
Oct 20, 2024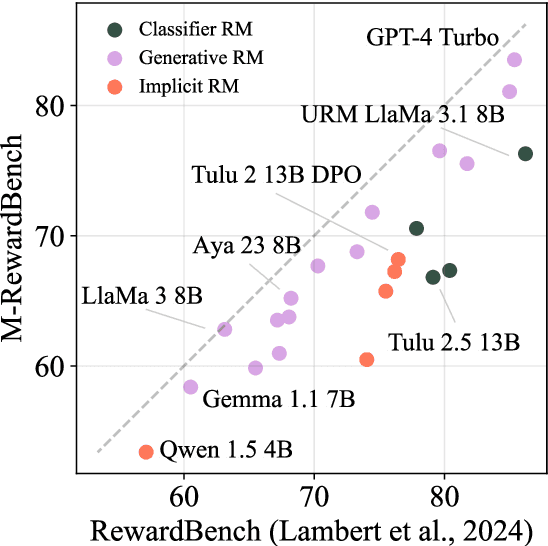



Reward models (RMs) have driven the state-of-the-art performance of LLMs today by enabling the integration of human feedback into the language modeling process. However, RMs are primarily trained and evaluated in English, and their capabilities in multilingual settings remain largely understudied. In this work, we conduct a systematic evaluation of several reward models in multilingual settings. We first construct the first-of-its-kind multilingual RM evaluation benchmark, M-RewardBench, consisting of 2.87k preference instances for 23 typologically diverse languages, that tests the chat, safety, reasoning, and translation capabilities of RMs. We then rigorously evaluate a wide range of reward models on M-RewardBench, offering fresh insights into their performance across diverse languages. We identify a significant gap in RMs' performances between English and non-English languages and show that RM preferences can change substantially from one language to another. We also present several findings on how different multilingual aspects impact RM performance. Specifically, we show that the performance of RMs is improved with improved translation quality. Similarly, we demonstrate that the models exhibit better performance for high-resource languages. We release M-RewardBench dataset and the codebase in this study to facilitate a better understanding of RM evaluation in multilingual settings.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
OLMoE: Open Mixture-of-Experts Language Models
Sep 03, 2024



We introduce OLMoE, a fully open, state-of-the-art language model leveraging sparse Mixture-of-Experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token. We pretrain it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B. We present various experiments on MoE training, analyze routing in our model showing high specialization, and open-source all aspects of our work: model weights, training data, code, and logs.
Self-Directed Synthetic Dialogues and Revisions Technical Report
Jul 25, 2024Synthetic data has become an important tool in the fine-tuning of language models to follow instructions and solve complex problems. Nevertheless, the majority of open data to date is often lacking multi-turn data and collected on closed models, limiting progress on advancing open fine-tuning methods. We introduce Self Directed Synthetic Dialogues (SDSD), an experimental dataset consisting of guided conversations of language models talking to themselves. The dataset consists of multi-turn conversations generated with DBRX, Llama 2 70B, and Mistral Large, all instructed to follow a conversation plan generated prior to the conversation. We also explore including principles from Constitutional AI and other related works to create synthetic preference data via revisions to the final conversation turn. We hope this work encourages further exploration in multi-turn data and the use of open models for expanding the impact of synthetic data.
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs
Jun 26, 2024



We introduce WildGuard -- an open, light-weight moderation tool for LLM safety that achieves three goals: (1) identifying malicious intent in user prompts, (2) detecting safety risks of model responses, and (3) determining model refusal rate. Together, WildGuard serves the increasing needs for automatic safety moderation and evaluation of LLM interactions, providing a one-stop tool with enhanced accuracy and broad coverage across 13 risk categories. While existing open moderation tools such as Llama-Guard2 score reasonably well in classifying straightforward model interactions, they lag far behind a prompted GPT-4, especially in identifying adversarial jailbreaks and in evaluating models' refusals, a key measure for evaluating safety behaviors in model responses. To address these challenges, we construct WildGuardMix, a large-scale and carefully balanced multi-task safety moderation dataset with 92K labeled examples that cover vanilla (direct) prompts and adversarial jailbreaks, paired with various refusal and compliance responses. WildGuardMix is a combination of WildGuardTrain, the training data of WildGuard, and WildGuardTest, a high-quality human-annotated moderation test set with 5K labeled items covering broad risk scenarios. Through extensive evaluations on WildGuardTest and ten existing public benchmarks, we show that WildGuard establishes state-of-the-art performance in open-source safety moderation across all the three tasks compared to ten strong existing open-source moderation models (e.g., up to 26.4% improvement on refusal detection). Importantly, WildGuard matches and sometimes exceeds GPT-4 performance (e.g., up to 3.9% improvement on prompt harmfulness identification). WildGuard serves as a highly effective safety moderator in an LLM interface, reducing the success rate of jailbreak attacks from 79.8% to 2.4%.