 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models
May 19, 2025Chart understanding presents a unique challenge for large vision-language models (LVLMs), as it requires the integration of sophisticated textual and visual reasoning capabilities. However, current LVLMs exhibit a notable imbalance between these skills, falling short on visual reasoning that is difficult to perform in text. We conduct a case study using a synthetic dataset solvable only through visual reasoning and show that model performance degrades significantly with increasing visual complexity, while human performance remains robust. We then introduce ChartMuseum, a new Chart Question Answering (QA) benchmark containing 1,162 expert-annotated questions spanning multiple reasoning types, curated from real-world charts across 184 sources, specifically built to evaluate complex visual and textual reasoning. Unlike prior chart understanding benchmarks -- where frontier models perform similarly and near saturation -- our benchmark exposes a substantial gap between model and human performance, while effectively differentiating model capabilities: although humans achieve 93% accuracy, the best-performing model Gemini-2.5-Pro attains only 63.0%, and the leading open-source LVLM Qwen2.5-VL-72B-Instruct achieves only 38.5%. Moreover, on questions requiring primarily visual reasoning, all models experience a 35%-55% performance drop from text-reasoning-heavy question performance. Lastly, our qualitative error analysis reveals specific categories of visual reasoning that are challenging for current LVLMs.
Assessing Robustness to Spurious Correlations in Post-Training Language Models
May 09, 2025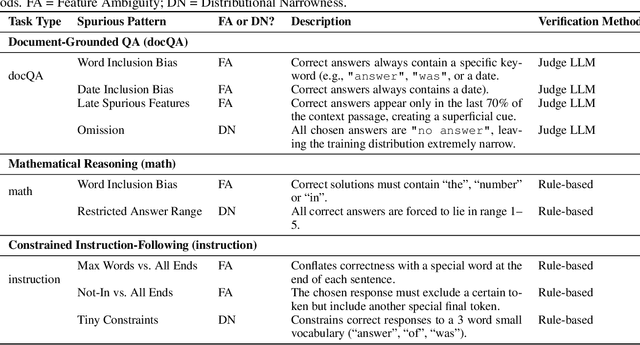
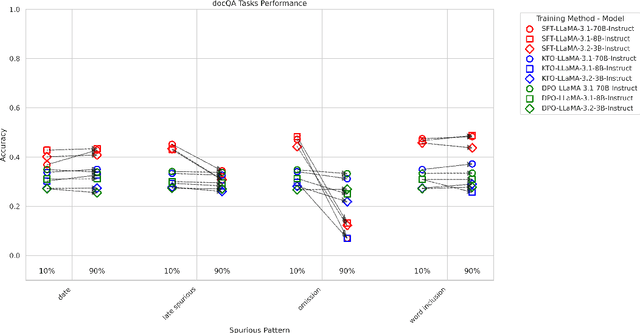
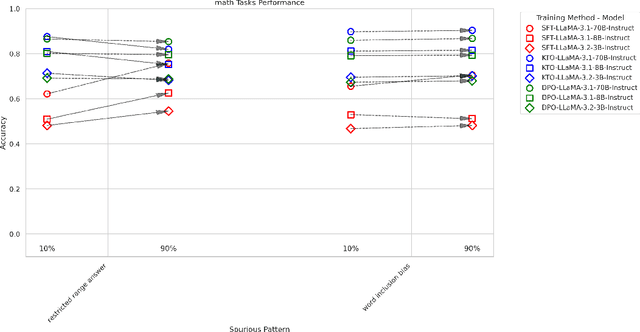
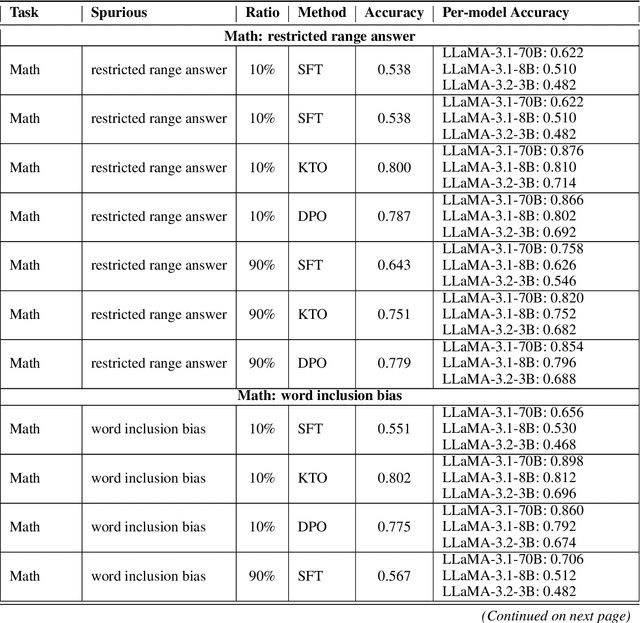
Supervised and preference-based fine-tuning techniques have become popular for aligning large language models (LLMs) with user intent and correctness criteria. However, real-world training data often exhibits spurious correlations -- arising from biases, dataset artifacts, or other "shortcut" features -- that can compromise a model's performance or generalization. In this paper, we systematically evaluate three post-training algorithms -- Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and KTO (Kahneman-Tversky Optimization) -- across a diverse set of synthetic tasks and spuriousness conditions. Our tasks span mathematical reasoning, constrained instruction-following, and document-grounded question answering. We vary the degree of spurious correlation (10% vs. 90%) and investigate two forms of artifacts: "Feature Ambiguity" and "Distributional Narrowness." Our results show that the models often but not always degrade under higher spuriousness. The preference-based methods (DPO/KTO) can demonstrate relative robustness in mathematical reasoning tasks. By contrast, SFT maintains stronger performance in complex, context-intensive tasks. These findings highlight that no single post-training strategy universally outperforms in all scenarios; the best choice depends on the type of target task and the nature of spurious correlations.
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning
Sep 18, 2024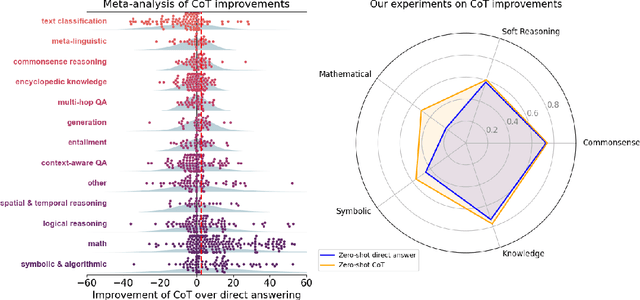


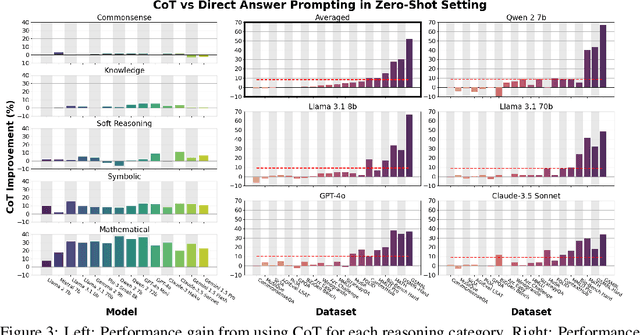
Chain-of-thought (CoT) via prompting is the de facto method for eliciting reasoning capabilities from large language models (LLMs). But for what kinds of tasks is this extra ``thinking'' really helpful? To analyze this, we conducted a quantitative meta-analysis covering over 100 papers using CoT and ran our own evaluations of 20 datasets across 14 models. Our results show that CoT gives strong performance benefits primarily on tasks involving math or logic, with much smaller gains on other types of tasks. On MMLU, directly generating the answer without CoT leads to almost identical accuracy as CoT unless the question or model's response contains an equals sign, indicating symbolic operations and reasoning. Following this finding, we analyze the behavior of CoT on these problems by separating planning and execution and comparing against tool-augmented LLMs. Much of CoT's gain comes from improving symbolic execution, but it underperforms relative to using a symbolic solver. Our results indicate that CoT can be applied selectively, maintaining performance while saving inference costs. Furthermore, they suggest a need to move beyond prompt-based CoT to new paradigms that better leverage intermediate computation across the whole range of LLM applications.
D2PO: Discriminator-Guided DPO with Response Evaluation Models
May 02, 2024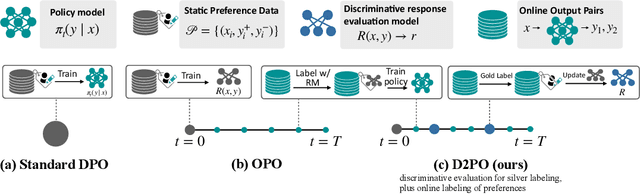
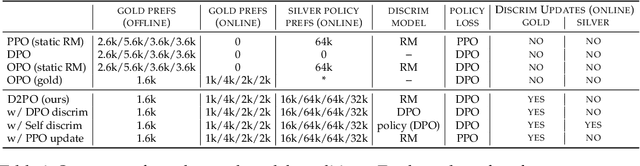
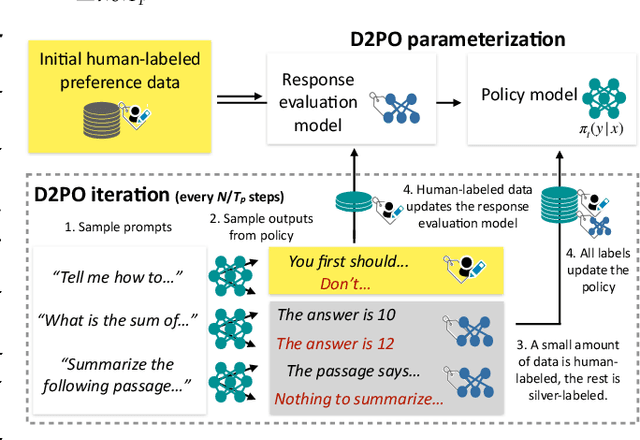
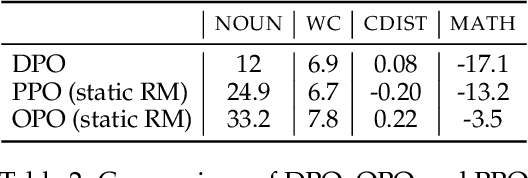
Varied approaches for aligning language models have been proposed, including supervised fine-tuning, RLHF, and direct optimization methods such as DPO. Although DPO has rapidly gained popularity due to its straightforward training process and competitive results, there is an open question of whether there remain practical advantages of using a discriminator, like a reward model, to evaluate responses. We propose D2PO, discriminator-guided DPO, an approach for the online setting where preferences are being collected throughout learning. As we collect gold preferences, we use these not only to train our policy, but to train a discriminative response evaluation model to silver-label even more synthetic data for policy training. We explore this approach across a set of diverse tasks, including a realistic chat setting, we find that our approach leads to higher-quality outputs compared to DPO with the same data budget, and greater efficiency in terms of preference data requirements. Furthermore, we show conditions under which silver labeling is most helpful: it is most effective when training the policy with DPO, outperforming traditional PPO, and benefits from maintaining a separate discriminator from the policy model.
A Long Way to Go: Investigating Length Correlations in RLHF
Oct 05, 2023



Great successes have been reported using Reinforcement Learning from Human Feedback (RLHF) to align large language models. Open-source preference datasets and reward models have enabled wider experimentation beyond generic chat settings, particularly to make systems more "helpful" for tasks like web question answering, summarization, and multi-turn dialogue. When optimizing for helpfulness, RLHF has been consistently observed to drive models to produce longer outputs. This paper demonstrates that optimizing for response length is a significant factor behind RLHF's reported improvements in these settings. First, we study the relationship between reward and length for reward models trained on three open-source preference datasets for helpfulness. Here, length correlates strongly with reward, and improvements in reward score are driven in large part by shifting the distribution over output lengths. We then explore interventions during both RL and reward model learning to see if we can achieve the same downstream improvements as RLHF without increasing length. While our interventions mitigate length increases, they aren't uniformly effective across settings. Furthermore, we find that even running RLHF with a reward based solely on length can reproduce most of the downstream improvements over the initial policy model, showing that reward models in these settings have a long way to go.
EEL: Efficiently Encoding Lattices for Reranking
Jun 01, 2023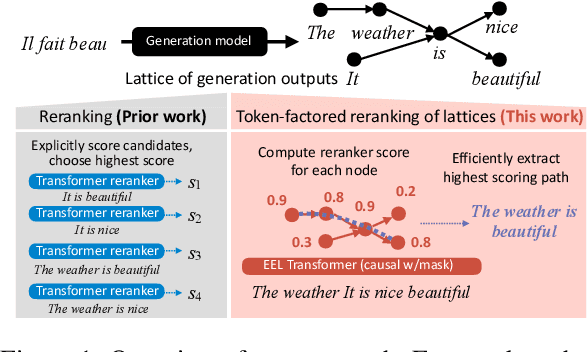
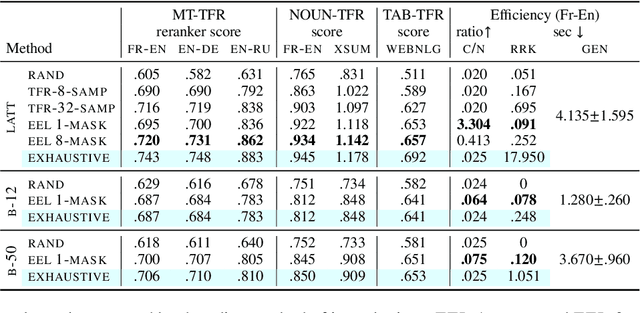
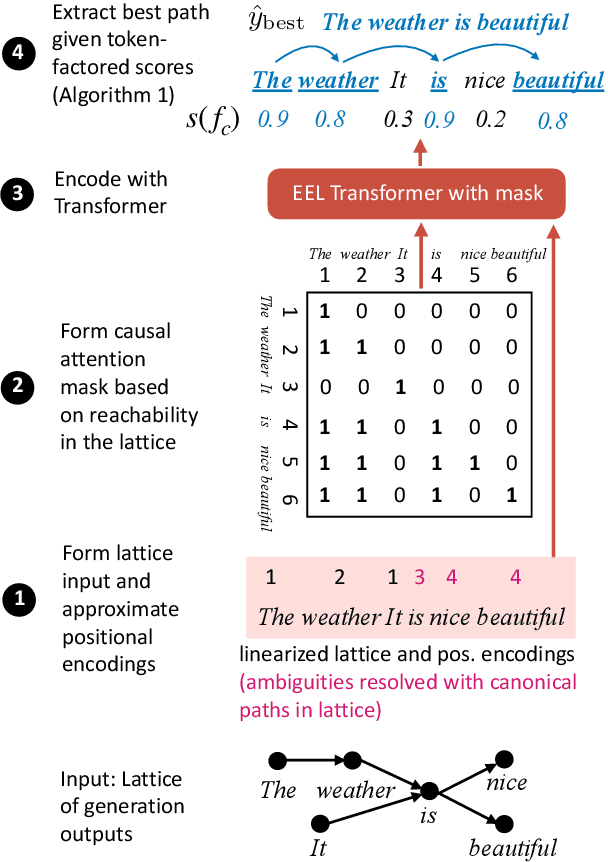
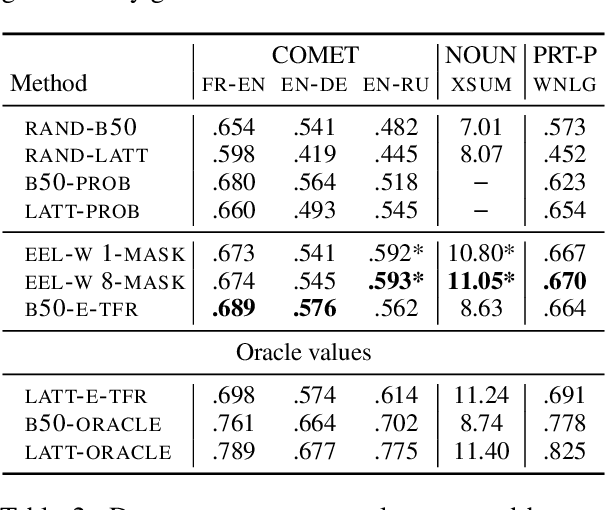
Standard decoding approaches for conditional text generation tasks typically search for an output hypothesis with high model probability, but this may not yield the best hypothesis according to human judgments of quality. Reranking to optimize for "downstream" metrics can better optimize for quality, but many metrics of interest are computed with pre-trained language models, which are slow to apply to large numbers of hypotheses. We explore an approach for reranking hypotheses by using Transformers to efficiently encode lattices of generated outputs, a method we call EEL. With a single Transformer pass over the entire lattice, we can approximately compute a contextualized representation of each token as if it were only part of a single hypothesis in isolation. We combine this approach with a new class of token-factored rerankers (TFRs) that allow for efficient extraction of high reranker-scoring hypotheses from the lattice. Empirically, our approach incurs minimal degradation error compared to the exponentially slower approach of encoding each hypothesis individually. When applying EEL with TFRs across three text generation tasks, our results show both substantial speedup compared to naive reranking and often better performance on downstream metrics than comparable approaches.
Assessing Out-of-Domain Language Model Performance from Few Examples
Oct 13, 2022
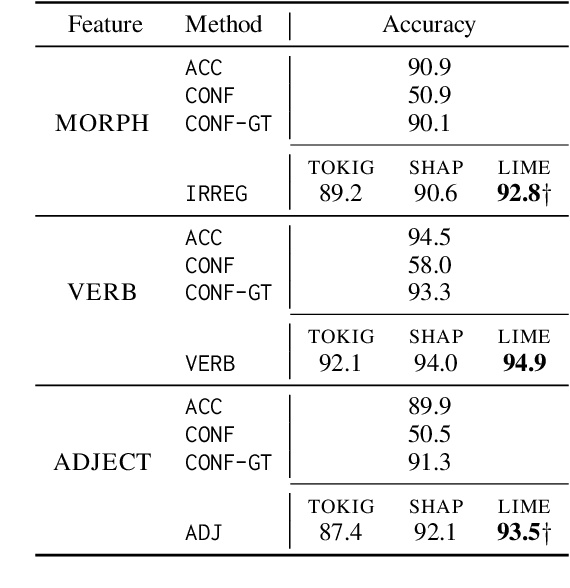

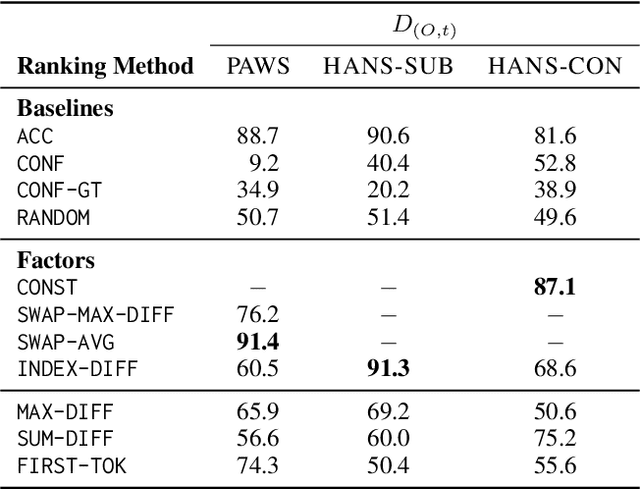
While pretrained language models have exhibited impressive generalization capabilities, they still behave unpredictably under certain domain shifts. In particular, a model may learn a reasoning process on in-domain training data that does not hold for out-of-domain test data. We address the task of predicting out-of-domain (OOD) performance in a few-shot fashion: given a few target-domain examples and a set of models with similar training performance, can we understand how these models will perform on OOD test data? We benchmark the performance on this task when looking at model accuracy on the few-shot examples, then investigate how to incorporate analysis of the models' behavior using feature attributions to better tackle this problem. Specifically, we explore a set of "factors" designed to reveal model agreement with certain pathological heuristics that may indicate worse generalization capabilities. On textual entailment, paraphrase recognition, and a synthetic classification task, we show that attribution-based factors can help rank relative model OOD performance. However, accuracy on a few-shot test set is a surprisingly strong baseline, particularly when the system designer does not have in-depth prior knowledge about the domain shift.