 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models
May 19, 2025Chart understanding presents a unique challenge for large vision-language models (LVLMs), as it requires the integration of sophisticated textual and visual reasoning capabilities. However, current LVLMs exhibit a notable imbalance between these skills, falling short on visual reasoning that is difficult to perform in text. We conduct a case study using a synthetic dataset solvable only through visual reasoning and show that model performance degrades significantly with increasing visual complexity, while human performance remains robust. We then introduce ChartMuseum, a new Chart Question Answering (QA) benchmark containing 1,162 expert-annotated questions spanning multiple reasoning types, curated from real-world charts across 184 sources, specifically built to evaluate complex visual and textual reasoning. Unlike prior chart understanding benchmarks -- where frontier models perform similarly and near saturation -- our benchmark exposes a substantial gap between model and human performance, while effectively differentiating model capabilities: although humans achieve 93% accuracy, the best-performing model Gemini-2.5-Pro attains only 63.0%, and the leading open-source LVLM Qwen2.5-VL-72B-Instruct achieves only 38.5%. Moreover, on questions requiring primarily visual reasoning, all models experience a 35%-55% performance drop from text-reasoning-heavy question performance. Lastly, our qualitative error analysis reveals specific categories of visual reasoning that are challenging for current LVLMs.
From Distributional to Overton Pluralism: Investigating Large Language Model Alignment
Jun 25, 2024



The alignment process changes several properties of a large language model's (LLM's) output distribution. We analyze two aspects of post-alignment distributional shift of LLM responses. First, we re-examine previously reported reductions in response diversity post-alignment. Our analysis suggests that an apparent drop in the diversity of responses is largely explained by quality control and information aggregation. Alignment suppresses irrelevant and unhelpful content while shifting the output distribution toward longer responses that cover information spanning several responses from the base LLM, essentially presenting diverse information in a single response. Finding little evidence that alignment suppresses useful information, it is natural to ask the opposite question: do aligned models surface information that cannot be recovered from base models? Our second investigation shows this is not the case and the behavior of aligned models is recoverable from base models without fine-tuning. A combination of in-context examples and lower-resolution semantic hints about response content can elicit responses from base LLMs that are as similar to alignment-tuned LLM responses as alignment-tuned LLM responses are to each other. Taken together, these results indicate that current alignment techniques capture but do not extend the useful subset of assistant-like base LLM behavior, providing further evidence for the Superficial Alignment Hypothesis. They also show that in-context alignment can go surprisingly far as a strategy for imitating aligned LLMs without fine-tuning. Our code and data is available at https://github.com/thomlake/investigating-alignment.
Distilling Large Language Models using Skill-Occupation Graph Context for HR-Related Tasks
Nov 10, 2023



Numerous HR applications are centered around resumes and job descriptions. While they can benefit from advancements in NLP, particularly large language models, their real-world adoption faces challenges due to absence of comprehensive benchmarks for various HR tasks, and lack of smaller models with competitive capabilities. In this paper, we aim to bridge this gap by introducing the Resume-Job Description Benchmark (RJDB). We meticulously craft this benchmark to cater to a wide array of HR tasks, including matching and explaining resumes to job descriptions, extracting skills and experiences from resumes, and editing resumes. To create this benchmark, we propose to distill domain-specific knowledge from a large language model (LLM). We rely on a curated skill-occupation graph to ensure diversity and provide context for LLMs generation. Our benchmark includes over 50 thousand triples of job descriptions, matched resumes and unmatched resumes. Using RJDB, we train multiple smaller student models. Our experiments reveal that the student models achieve near/better performance than the teacher model (GPT-4), affirming the effectiveness of the benchmark. Additionally, we explore the utility of RJDB on out-of-distribution data for skill extraction and resume-job description matching, in zero-shot and weak supervision manner. We release our datasets and code to foster further research and industry applications.
Large-scale Collaborative Filtering with Product Embeddings
Jan 11, 2019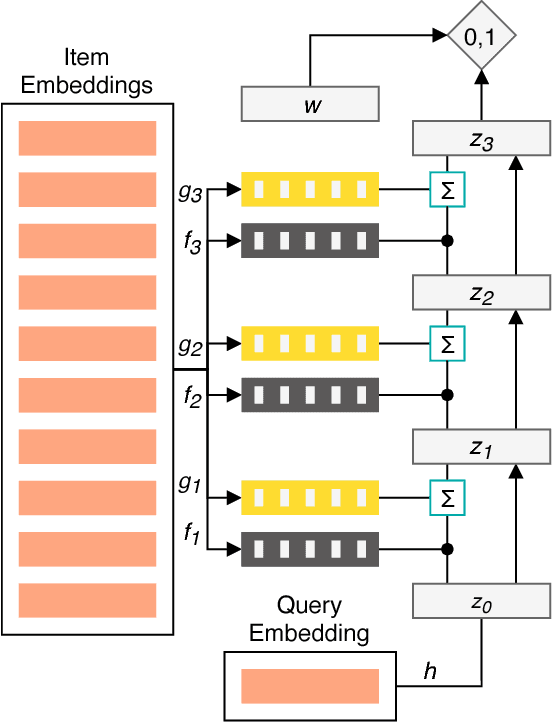

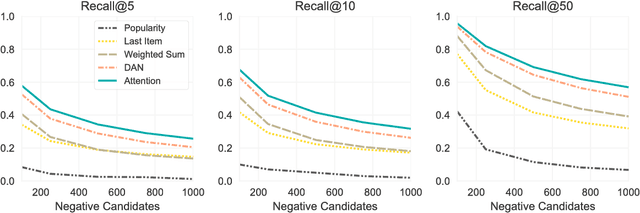
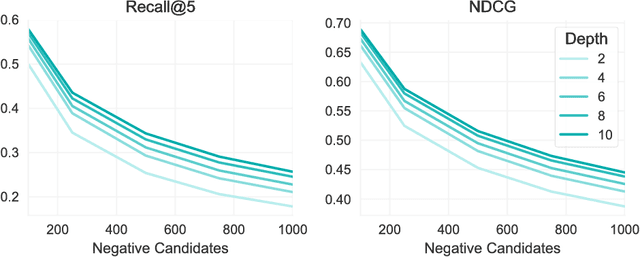
The application of machine learning techniques to large-scale personalized recommendation problems is a challenging task. Such systems must make sense of enormous amounts of implicit feedback in order to understand user preferences across numerous product categories. This paper presents a deep learning based solution to this problem within the collaborative filtering with implicit feedback framework. Our approach combines neural attention mechanisms, which allow for context dependent weighting of past behavioral signals, with representation learning techniques to produce models which obtain extremely high coverage, can easily incorporate new information as it becomes available, and are computationally efficient. Offline experiments demonstrate significant performance improvements when compared to several alternative methods from the literature. Results from an online setting show that the approach compares favorably with current production techniques used to produce personalized product recommendations.