 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Bringing Federated Learning to Space
Nov 18, 2025As Low Earth Orbit (LEO) satellite constellations rapidly expand to hundreds and thousands of spacecraft, the need for distributed on-board machine learning becomes critical to address downlink bandwidth limitations. Federated learning (FL) offers a promising framework to conduct collaborative model training across satellite networks. Realizing its benefits in space naturally requires addressing space-specific constraints, from intermittent connectivity to dynamics imposed by orbital motion. This work presents the first systematic feasibility analysis of adapting off-the-shelf FL algorithms for satellite constellation deployment. We introduce a comprehensive "space-ification" framework that adapts terrestrial algorithms (FedAvg, FedProx, FedBuff) to operate under orbital constraints, producing an orbital-ready suite of FL algorithms. We then evaluate these space-ified methods through extensive parameter sweeps across 768 constellation configurations that vary cluster sizes (1-10), satellites per cluster (1-10), and ground station networks (1-13). Our analysis demonstrates that space-adapted FL algorithms efficiently scale to constellations of up to 100 satellites, achieving performance close to the centralized ideal. Multi-month training cycles can be reduced to days, corresponding to a 9x speedup through orbital scheduling and local coordination within satellite clusters. These results provide actionable insights for future mission designers, enabling distributed on-board learning for more autonomous, resilient, and data-driven satellite operations.
GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks
Oct 05, 2025



We introduce GDPval, a benchmark evaluating AI model capabilities on real-world economically valuable tasks. GDPval covers the majority of U.S. Bureau of Labor Statistics Work Activities for 44 occupations across the top 9 sectors contributing to U.S. GDP (Gross Domestic Product). Tasks are constructed from the representative work of industry professionals with an average of 14 years of experience. We find that frontier model performance on GDPval is improving roughly linearly over time, and that the current best frontier models are approaching industry experts in deliverable quality. We analyze the potential for frontier models, when paired with human oversight, to perform GDPval tasks cheaper and faster than unaided experts. We also demonstrate that increased reasoning effort, increased task context, and increased scaffolding improves model performance on GDPval. Finally, we open-source a gold subset of 220 tasks and provide a public automated grading service at evals.openai.com to facilitate future research in understanding real-world model capabilities.
ChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models
May 19, 2025Chart understanding presents a unique challenge for large vision-language models (LVLMs), as it requires the integration of sophisticated textual and visual reasoning capabilities. However, current LVLMs exhibit a notable imbalance between these skills, falling short on visual reasoning that is difficult to perform in text. We conduct a case study using a synthetic dataset solvable only through visual reasoning and show that model performance degrades significantly with increasing visual complexity, while human performance remains robust. We then introduce ChartMuseum, a new Chart Question Answering (QA) benchmark containing 1,162 expert-annotated questions spanning multiple reasoning types, curated from real-world charts across 184 sources, specifically built to evaluate complex visual and textual reasoning. Unlike prior chart understanding benchmarks -- where frontier models perform similarly and near saturation -- our benchmark exposes a substantial gap between model and human performance, while effectively differentiating model capabilities: although humans achieve 93% accuracy, the best-performing model Gemini-2.5-Pro attains only 63.0%, and the leading open-source LVLM Qwen2.5-VL-72B-Instruct achieves only 38.5%. Moreover, on questions requiring primarily visual reasoning, all models experience a 35%-55% performance drop from text-reasoning-heavy question performance. Lastly, our qualitative error analysis reveals specific categories of visual reasoning that are challenging for current LVLMs.
Is the Top Still Spinning? Evaluating Subjectivity in Narrative Understanding
Apr 01, 2025

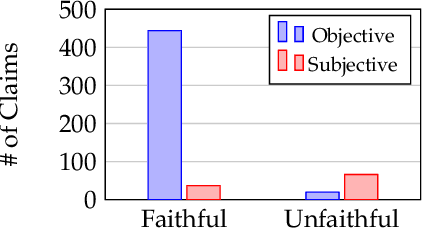
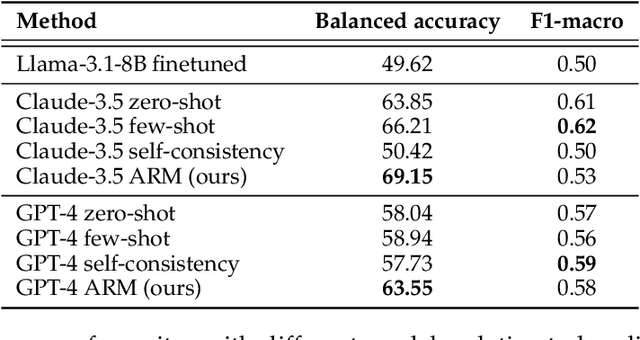
Determining faithfulness of a claim to a source document is an important problem across many domains. This task is generally treated as a binary judgment of whether the claim is supported or unsupported in relation to the source. In many cases, though, whether a claim is supported can be ambiguous. For instance, it may depend on making inferences from given evidence, and different people can reasonably interpret the claim as either supported or unsupported based on their agreement with those inferences. Forcing binary labels upon such claims lowers the reliability of evaluation. In this work, we reframe the task to manage the subjectivity involved with factuality judgments of ambiguous claims. We introduce LLM-generated edits of summaries as a method of providing a nuanced evaluation of claims: how much does a summary need to be edited to be unambiguous? Whether a claim gets rewritten and how much it changes can be used as an automatic evaluation metric, the Ambiguity Rewrite Metric (ARM), with a much richer feedback signal than a binary judgment of faithfulness. We focus on the area of narrative summarization as it is particularly rife with ambiguity and subjective interpretation. We show that ARM produces a 21% absolute improvement in annotator agreement on claim faithfulness, indicating that subjectivity is reduced.
Space for Improvement: Navigating the Design Space for Federated Learning in Satellite Constellations
Oct 31, 2024Space has emerged as an exciting new application area for machine learning, with several missions equipping deep learning capabilities on-board spacecraft. Pre-processing satellite data through on-board training is necessary to address the satellite downlink deficit, as not enough transmission opportunities are available to match the high rates of data generation. To scale this effort across entire constellations, collaborated training in orbit has been enabled through federated learning (FL). While current explorations of FL in this context have successfully adapted FL algorithms for scenario-specific constraints, these theoretical FL implementations face several limitations that prevent progress towards real-world deployment. To address this gap, we provide a holistic exploration of the FL in space domain on several fronts. 1) We develop a method for space-ification of existing FL algorithms, evaluated on 2) FLySTacK, our novel satellite constellation design and hardware aware testing platform where we perform rigorous algorithm evaluations. Finally we introduce 3) AutoFLSat, a generalized, hierarchical, autonomous FL algorithm for space that provides a 12.5% to 37.5% reduction in model training time than leading alternatives.
Complex Claim Verification with Evidence Retrieved in the Wild
May 19, 2023Evidence retrieval is a core part of automatic fact-checking. Prior work makes simplifying assumptions in retrieval that depart from real-world use cases: either no access to evidence, access to evidence curated by a human fact-checker, or access to evidence available long after the claim has been made. In this work, we present the first fully automated pipeline to check real-world claims by retrieving raw evidence from the web. We restrict our retriever to only search documents available prior to the claim's making, modeling the realistic scenario where an emerging claim needs to be checked. Our pipeline includes five components: claim decomposition, raw document retrieval, fine-grained evidence retrieval, claim-focused summarization, and veracity judgment. We conduct experiments on complex political claims in the ClaimDecomp dataset and show that the aggregated evidence produced by our pipeline improves veracity judgments. Human evaluation finds the evidence summary produced by our system is reliable (it does not hallucinate information) and relevant to answering key questions about a claim, suggesting that it can assist fact-checkers even when it cannot surface a complete evidence set.