 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedeSEO: Physics-Aware Dataset Creation for High-Resolution Satellite Image Shadow Removal
May 05, 2026Shadows cast by terrain and tall structures remain a major obstacle for high-resolution satellite image analysis, degrading classification, detection, and 3D reconstruction performance. Public resources offering geometry-consistent paired shadow/shadow-free satellite imagery are essentially missing, and most Earth-observation datasets are designed for shadow detection or 3D modelling rather than removal. Existing deep shadow-removal datasets either target ground-level or aerial scenes or rely on unpaired and weakly supervised formulations rather than explicit satellite pairs. We address this gap with deSEO, a geometry-aware and physics-informed methodology that, to the best of our knowledge, is the first to derive paired supervision for satellite shadow removal from the S-EO shadow detection dataset through a fully replicable pipeline. For each tile, deSEO selects a minimally shadowed acquisition as a weak reference and pairs it with shadowed counterparts using temporal and geometric filtering, Jacobian-based orientation normalisation, and LoFTR-RANSAC registration. A per-pixel validity mask restricts learning to reliably aligned regions, enabling supervision despite residual off-nadir parallax. In addition to this paired dataset, we develop a DSM-aware deshadowing model that combines residual translation, perceptual objectives, and mask-constrained adversarial learning. In contrast, a direct adaptation of a UAV-based SRNet/pix2pix architecture fails to converge under satellite viewpoint variability. Our model consistently reduces the visual impact of cast shadows across diverse illumination and viewing conditions, achieving improved structural and perceptual fidelity on held-out scenes. deSEO therefore provides the first reproducible, geometry-aware paired dataset and baseline for shadow removal in satellite Earth observation.
Bringing Federated Learning to Space
Nov 18, 2025As Low Earth Orbit (LEO) satellite constellations rapidly expand to hundreds and thousands of spacecraft, the need for distributed on-board machine learning becomes critical to address downlink bandwidth limitations. Federated learning (FL) offers a promising framework to conduct collaborative model training across satellite networks. Realizing its benefits in space naturally requires addressing space-specific constraints, from intermittent connectivity to dynamics imposed by orbital motion. This work presents the first systematic feasibility analysis of adapting off-the-shelf FL algorithms for satellite constellation deployment. We introduce a comprehensive "space-ification" framework that adapts terrestrial algorithms (FedAvg, FedProx, FedBuff) to operate under orbital constraints, producing an orbital-ready suite of FL algorithms. We then evaluate these space-ified methods through extensive parameter sweeps across 768 constellation configurations that vary cluster sizes (1-10), satellites per cluster (1-10), and ground station networks (1-13). Our analysis demonstrates that space-adapted FL algorithms efficiently scale to constellations of up to 100 satellites, achieving performance close to the centralized ideal. Multi-month training cycles can be reduced to days, corresponding to a 9x speedup through orbital scheduling and local coordination within satellite clusters. These results provide actionable insights for future mission designers, enabling distributed on-board learning for more autonomous, resilient, and data-driven satellite operations.
Rapid Distributed Fine-tuning of a Segmentation Model Onboard Satellites
Nov 26, 2024Segmentation of Earth observation (EO) satellite data is critical for natural hazard analysis and disaster response. However, processing EO data at ground stations introduces delays due to data transmission bottlenecks and communication windows. Using segmentation models capable of near-real-time data analysis onboard satellites can therefore improve response times. This study presents a proof-of-concept using MobileSAM, a lightweight, pre-trained segmentation model, onboard Unibap iX10-100 satellite hardware. We demonstrate the segmentation of water bodies from Sentinel-2 satellite imagery and integrate MobileSAM with PASEOS, an open-source Python module that simulates satellite operations. This integration allows us to evaluate MobileSAM's performance under simulated conditions of a satellite constellation. Our research investigates the potential of fine-tuning MobileSAM in a decentralised way onboard multiple satellites in rapid response to a disaster. Our findings show that MobileSAM can be rapidly fine-tuned and benefits from decentralised learning, considering the constraints imposed by the simulated orbital environment. We observe improvements in segmentation performance with minimal training data and fast fine-tuning when satellites frequently communicate model updates. This study contributes to the field of onboard AI by emphasising the benefits of decentralised learning and fine-tuning pre-trained models for rapid response scenarios. Our work builds on recent related research at a critical time; as extreme weather events increase in frequency and magnitude, rapid response with onboard data analysis is essential.
Space for Improvement: Navigating the Design Space for Federated Learning in Satellite Constellations
Oct 31, 2024Space has emerged as an exciting new application area for machine learning, with several missions equipping deep learning capabilities on-board spacecraft. Pre-processing satellite data through on-board training is necessary to address the satellite downlink deficit, as not enough transmission opportunities are available to match the high rates of data generation. To scale this effort across entire constellations, collaborated training in orbit has been enabled through federated learning (FL). While current explorations of FL in this context have successfully adapted FL algorithms for scenario-specific constraints, these theoretical FL implementations face several limitations that prevent progress towards real-world deployment. To address this gap, we provide a holistic exploration of the FL in space domain on several fronts. 1) We develop a method for space-ification of existing FL algorithms, evaluated on 2) FLySTacK, our novel satellite constellation design and hardware aware testing platform where we perform rigorous algorithm evaluations. Finally we introduce 3) AutoFLSat, a generalized, hierarchical, autonomous FL algorithm for space that provides a 12.5% to 37.5% reduction in model training time than leading alternatives.
Attacks of fairness in Federated Learning
Nov 21, 2023Federated Learning is an important emerging distributed training paradigm that keeps data private on clients. It is now well understood that by controlling only a small subset of FL clients, it is possible to introduce a backdoor to a federated learning model, in the presence of certain attributes. In this paper, we present a new type of attack that compromises the fairness of the trained model. Fairness is understood to be the attribute-level performance distribution of a trained model. It is particularly salient in domains where, for example, skewed accuracy discrimination between subpopulations could have disastrous consequences. We find that by employing a threat model similar to that of a backdoor attack, an attacker is able to influence the aggregated model to have an unfair performance distribution between any given set of attributes. Furthermore, we find that this attack is possible by controlling only a single client. While combating naturally induced unfairness in FL has previously been discussed in depth, its artificially induced kind has been neglected. We show that defending against attacks on fairness should be a critical consideration in any situation where unfairness in a trained model could benefit a user who participated in its training.
FDAPT: Federated Domain-adaptive Pre-training for Language Models
Jul 12, 2023
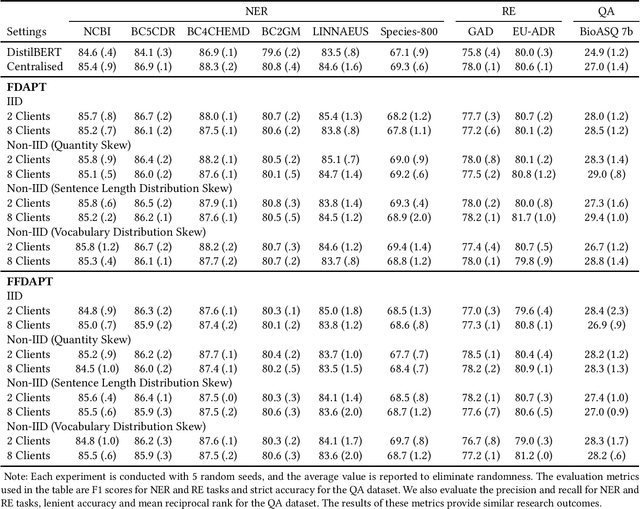
Combining Domain-adaptive Pre-training (DAPT) with Federated Learning (FL) can enhance model adaptation by leveraging more sensitive and distributed data while preserving data privacy. However, few studies have focused on this method. Therefore, we conduct the first comprehensive empirical study to evaluate the performance of Federated Domain-adaptive Pre-training (FDAPT). We demonstrate that FDAPT can maintain competitive downstream task performance to the centralized baseline in both IID and non-IID situations. Furthermore, we propose a novel algorithm, Frozen Federated Domain-adaptive Pre-training (FFDAPT). FFDAPT improves the computational efficiency by 12.1% on average and exhibits similar downstream task performance to standard FDAPT, with general performance fluctuations remaining less than 1%. Finally, through a critical evaluation of our work, we identify promising future research directions for this new research area.
A Federated Learning Benchmark for Drug-Target Interaction
Feb 15, 2023


Aggregating pharmaceutical data in the drug-target interaction (DTI) domain has the potential to deliver life-saving breakthroughs. It is, however, notoriously difficult due to regulatory constraints and commercial interests. This work proposes the application of federated learning, which we argue to be reconcilable with the industry's constraints, as it does not require sharing of any information that would reveal the entities' data or any other high-level summary of it. When used on a representative GraphDTA model and the KIBA dataset it achieves up to 15% improved performance relative to the best available non-privacy preserving alternative. Our extensive battery of experiments shows that, unlike in other domains, the non-IID data distribution in the DTI datasets does not deteriorate FL performance. Additionally, we identify a material trade-off between the benefits of adding new data, and the cost of adding more clients.