 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacks of fairness in Federated Learning
Nov 21, 2023Federated Learning is an important emerging distributed training paradigm that keeps data private on clients. It is now well understood that by controlling only a small subset of FL clients, it is possible to introduce a backdoor to a federated learning model, in the presence of certain attributes. In this paper, we present a new type of attack that compromises the fairness of the trained model. Fairness is understood to be the attribute-level performance distribution of a trained model. It is particularly salient in domains where, for example, skewed accuracy discrimination between subpopulations could have disastrous consequences. We find that by employing a threat model similar to that of a backdoor attack, an attacker is able to influence the aggregated model to have an unfair performance distribution between any given set of attributes. Furthermore, we find that this attack is possible by controlling only a single client. While combating naturally induced unfairness in FL has previously been discussed in depth, its artificially induced kind has been neglected. We show that defending against attacks on fairness should be a critical consideration in any situation where unfairness in a trained model could benefit a user who participated in its training.
Augmentation Backdoors
Sep 29, 2022
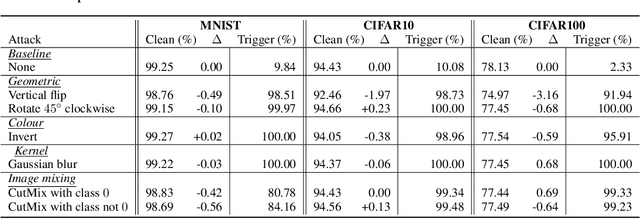
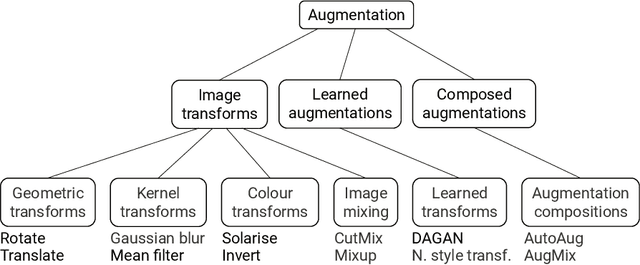

Data augmentation is used extensively to improve model generalisation. However, reliance on external libraries to implement augmentation methods introduces a vulnerability into the machine learning pipeline. It is well known that backdoors can be inserted into machine learning models through serving a modified dataset to train on. Augmentation therefore presents a perfect opportunity to perform this modification without requiring an initially backdoored dataset. In this paper we present three backdoor attacks that can be covertly inserted into data augmentation. Our attacks each insert a backdoor using a different type of computer vision augmentation transform, covering simple image transforms, GAN-based augmentation, and composition-based augmentation. By inserting the backdoor using these augmentation transforms, we make our backdoors difficult to detect, while still supporting arbitrary backdoor functionality. We evaluate our attacks on a range of computer vision benchmarks and demonstrate that an attacker is able to introduce backdoors through just a malicious augmentation routine.