 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Distributed Fine-tuning of a Segmentation Model Onboard Satellites
Nov 26, 2024Segmentation of Earth observation (EO) satellite data is critical for natural hazard analysis and disaster response. However, processing EO data at ground stations introduces delays due to data transmission bottlenecks and communication windows. Using segmentation models capable of near-real-time data analysis onboard satellites can therefore improve response times. This study presents a proof-of-concept using MobileSAM, a lightweight, pre-trained segmentation model, onboard Unibap iX10-100 satellite hardware. We demonstrate the segmentation of water bodies from Sentinel-2 satellite imagery and integrate MobileSAM with PASEOS, an open-source Python module that simulates satellite operations. This integration allows us to evaluate MobileSAM's performance under simulated conditions of a satellite constellation. Our research investigates the potential of fine-tuning MobileSAM in a decentralised way onboard multiple satellites in rapid response to a disaster. Our findings show that MobileSAM can be rapidly fine-tuned and benefits from decentralised learning, considering the constraints imposed by the simulated orbital environment. We observe improvements in segmentation performance with minimal training data and fast fine-tuning when satellites frequently communicate model updates. This study contributes to the field of onboard AI by emphasising the benefits of decentralised learning and fine-tuning pre-trained models for rapid response scenarios. Our work builds on recent related research at a critical time; as extreme weather events increase in frequency and magnitude, rapid response with onboard data analysis is essential.
Towards Holistic Disease Risk Prediction using Small Language Models
Aug 13, 2024Data in the healthcare domain arise from a variety of sources and modalities, such as x-ray images, continuous measurements, and clinical notes. Medical practitioners integrate these diverse data types daily to make informed and accurate decisions. With recent advancements in language models capable of handling multimodal data, it is a logical progression to apply these models to the healthcare sector. In this work, we introduce a framework that connects small language models to multiple data sources, aiming to predict the risk of various diseases simultaneously. Our experiments encompass 12 different tasks within a multitask learning setup. Although our approach does not surpass state-of-the-art methods specialized for single tasks, it demonstrates competitive performance and underscores the potential of small language models for multimodal reasoning in healthcare.
Creating and Benchmarking a Synthetic Dataset for Cloud Optical Thickness Estimation
Nov 23, 2023
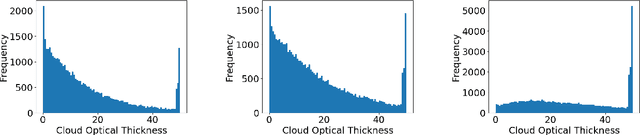
Cloud formations often obscure optical satellite-based monitoring of the Earth's surface, thus limiting Earth observation (EO) activities such as land cover mapping, ocean color analysis, and cropland monitoring. The integration of machine learning (ML) methods within the remote sensing domain has significantly improved performance on a wide range of EO tasks, including cloud detection and filtering, but there is still much room for improvement. A key bottleneck is that ML methods typically depend on large amounts of annotated data for training, which is often difficult to come by in EO contexts. This is especially true for the task of cloud optical thickness (COT) estimation. A reliable estimation of COT enables more fine-grained and application-dependent control compared to using pre-specified cloud categories, as is commonly done in practice. To alleviate the COT data scarcity problem, in this work we propose a novel synthetic dataset for COT estimation, where top-of-atmosphere radiances have been simulated for 12 of the spectral bands of the Multi-Spectral Instrument (MSI) sensor onboard Sentinel-2 platforms. These data points have been simulated under consideration of different cloud types, COTs, and ground surface and atmospheric profiles. Extensive experimentation of training several ML models to predict COT from the measured reflectivity of the spectral bands demonstrates the usefulness of our proposed dataset. Generalization to real data is also demonstrated on two satellite image datasets -- one that is publicly available, and one which we have collected and annotated. The synthetic data, the newly collected real dataset, code and models have been made publicly available at https://github.com/aleksispi/ml-cloud-opt-thick.