 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Conditioning Bias in Binary Decision Trees and Random Forests and Its Elimination
Dec 17, 2023Decision tree and random forest classification and regression are some of the most widely used in machine learning approaches. Binary decision tree implementations commonly use conditioning in the form 'feature $\leq$ (or $<$) threshold', with the threshold being the midpoint between two observed feature values. In this paper, we investigate the bias introduced by the choice of conditioning operator (an intrinsic property of implementations) in the presence of features with lattice characteristics. We propose techniques to eliminate this bias, requiring an additional prediction with decision trees and incurring no cost for random forests. Using 20 classification and 20 regression datasets, we demonstrate that the bias can lead to statistically significant differences in terms of AUC and $r^2$ scores. The proposed techniques successfully mitigate the bias, compared to the worst-case scenario, statistically significant improvements of up to 0.1-0.2 percentage points of AUC and $r^2$ scores were achieved and the improvement of 1.5 percentage points of $r^2$ score was measured in the most sensitive case of random forest regression. The implementation of the study is available on GitHub at the following repository: \url{https://github.com/gykovacs/conditioning_bias}.
Creating and Benchmarking a Synthetic Dataset for Cloud Optical Thickness Estimation
Nov 23, 2023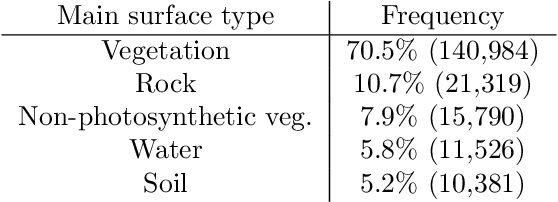
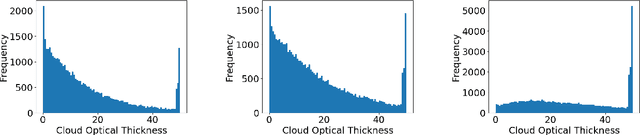
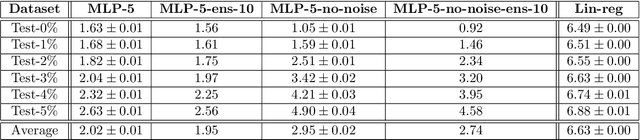
Cloud formations often obscure optical satellite-based monitoring of the Earth's surface, thus limiting Earth observation (EO) activities such as land cover mapping, ocean color analysis, and cropland monitoring. The integration of machine learning (ML) methods within the remote sensing domain has significantly improved performance on a wide range of EO tasks, including cloud detection and filtering, but there is still much room for improvement. A key bottleneck is that ML methods typically depend on large amounts of annotated data for training, which is often difficult to come by in EO contexts. This is especially true for the task of cloud optical thickness (COT) estimation. A reliable estimation of COT enables more fine-grained and application-dependent control compared to using pre-specified cloud categories, as is commonly done in practice. To alleviate the COT data scarcity problem, in this work we propose a novel synthetic dataset for COT estimation, where top-of-atmosphere radiances have been simulated for 12 of the spectral bands of the Multi-Spectral Instrument (MSI) sensor onboard Sentinel-2 platforms. These data points have been simulated under consideration of different cloud types, COTs, and ground surface and atmospheric profiles. Extensive experimentation of training several ML models to predict COT from the measured reflectivity of the spectral bands demonstrates the usefulness of our proposed dataset. Generalization to real data is also demonstrated on two satellite image datasets -- one that is publicly available, and one which we have collected and annotated. The synthetic data, the newly collected real dataset, code and models have been made publicly available at https://github.com/aleksispi/ml-cloud-opt-thick.
mlscorecheck: Testing the consistency of reported performance scores and experiments in machine learning
Nov 13, 2023Addressing the reproducibility crisis in artificial intelligence through the validation of reported experimental results is a challenging task. It necessitates either the reimplementation of techniques or a meticulous assessment of papers for deviations from the scientific method and best statistical practices. To facilitate the validation of reported results, we have developed numerical techniques capable of identifying inconsistencies between reported performance scores and various experimental setups in machine learning problems, including binary/multiclass classification and regression. These consistency tests are integrated into the open-source package mlscorecheck, which also provides specific test bundles designed to detect systematically recurring flaws in various fields, such as retina image processing and synthetic minority oversampling.
Testing the Consistency of Performance Scores Reported for Binary Classification Problems
Oct 19, 2023Binary classification is a fundamental task in machine learning, with applications spanning various scientific domains. Whether scientists are conducting fundamental research or refining practical applications, they typically assess and rank classification techniques based on performance metrics such as accuracy, sensitivity, and specificity. However, reported performance scores may not always serve as a reliable basis for research ranking. This can be attributed to undisclosed or unconventional practices related to cross-validation, typographical errors, and other factors. In a given experimental setup, with a specific number of positive and negative test items, most performance scores can assume specific, interrelated values. In this paper, we introduce numerical techniques to assess the consistency of reported performance scores and the assumed experimental setup. Importantly, the proposed approach does not rely on statistical inference but uses numerical methods to identify inconsistencies with certainty. Through three different applications related to medicine, we demonstrate how the proposed techniques can effectively detect inconsistencies, thereby safeguarding the integrity of research fields. To benefit the scientific community, we have made the consistency tests available in an open-source Python package.
NLP-LTU at SemEval-2023 Task 10: The Impact of Data Augmentation and Semi-Supervised Learning Techniques on Text Classification Performance on an Imbalanced Dataset
Apr 25, 2023



In this paper, we propose a methodology for task 10 of SemEval23, focusing on detecting and classifying online sexism in social media posts. The task is tackling a serious issue, as detecting harmful content on social media platforms is crucial for mitigating the harm of these posts on users. Our solution for this task is based on an ensemble of fine-tuned transformer-based models (BERTweet, RoBERTa, and DeBERTa). To alleviate problems related to class imbalance, and to improve the generalization capability of our model, we also experiment with data augmentation and semi-supervised learning. In particular, for data augmentation, we use back-translation, either on all classes, or on the underrepresented classes only. We analyze the impact of these strategies on the overall performance of the pipeline through extensive experiments. while for semi-supervised learning, we found that with a substantial amount of unlabelled, in-domain data available, semi-supervised learning can enhance the performance of certain models. Our proposed method (for which the source code is available on Github attains an F1-score of 0.8613 for sub-taskA, which ranked us 10th in the competition
A general technique for the estimation of farm animal body part weights from CT scans and its applications in a rabbit breeding program
Dec 30, 2021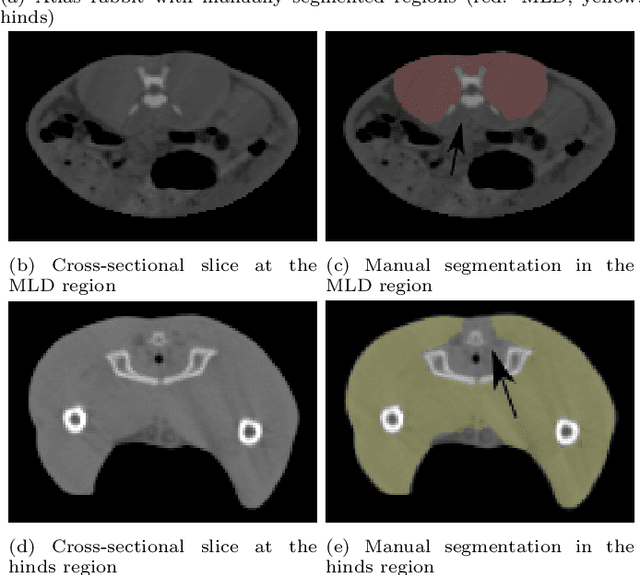
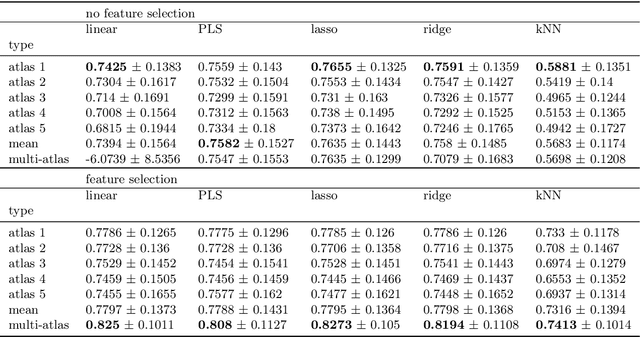
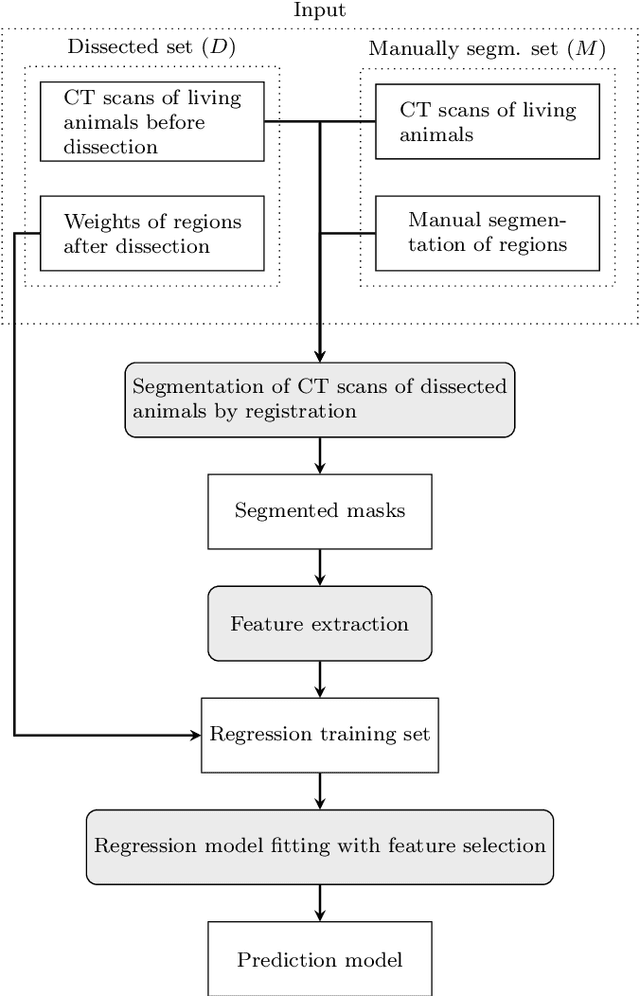
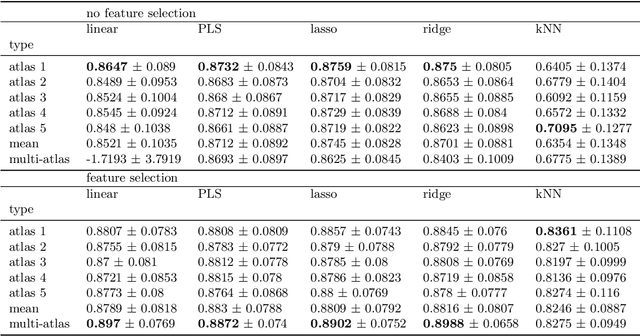
Various applications of farm animal imaging are based on the estimation of weights of certain body parts and cuts from the CT images of animals. In many cases, the complexity of the problem is increased by the enormous variability of postures in CT images due to the scanning of non-sedated, living animals. In this paper, we propose a general and robust approach for the estimation of the weights of cuts and body parts from the CT images of (possibly) living animals. We adapt multi-atlas based segmentation driven by elastic registration and joint feature and model selection for the regression component to cape with the large number of features and low number of samples. The proposed technique is evaluated and illustrated through real applications in rabbit breeding programs, showing r^2 scores 12% higher than previous techniques and methods that used to drive the selection so far. The proposed technique is easily adaptable to similar problems, consequently, it is shared in an open source software package for the benefit of the community.
A new baseline for retinal vessel segmentation: Numerical identification and correction of methodological inconsistencies affecting 100+ papers
Nov 06, 2021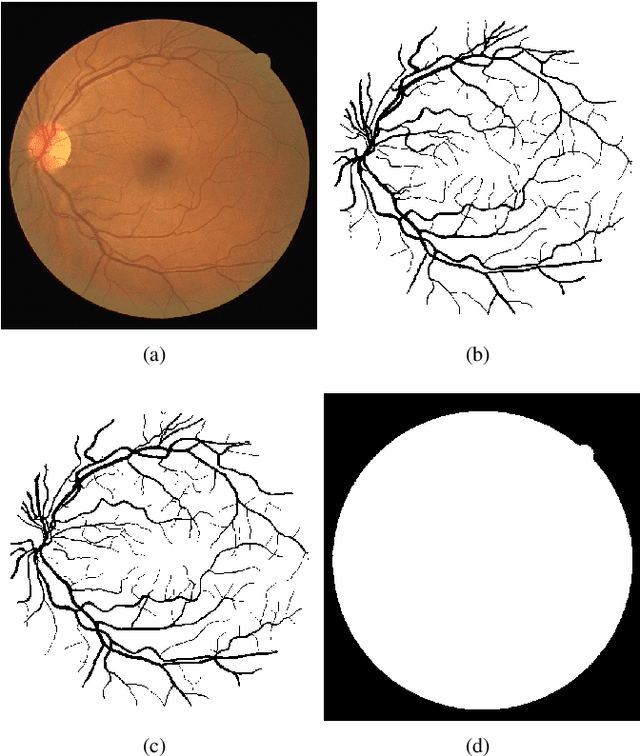
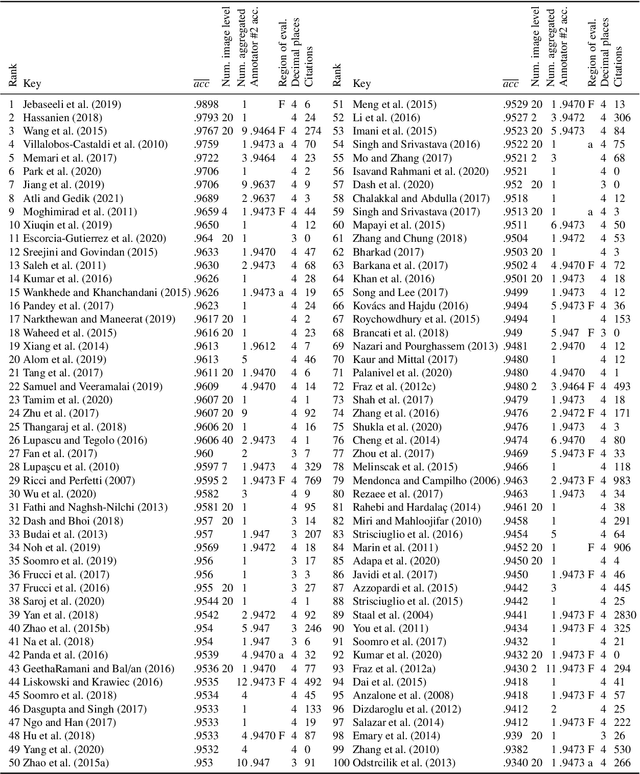
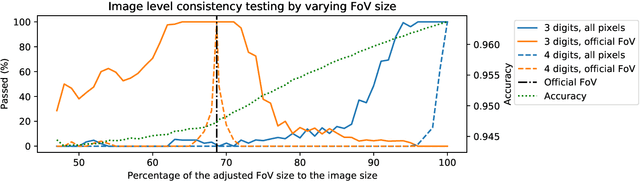
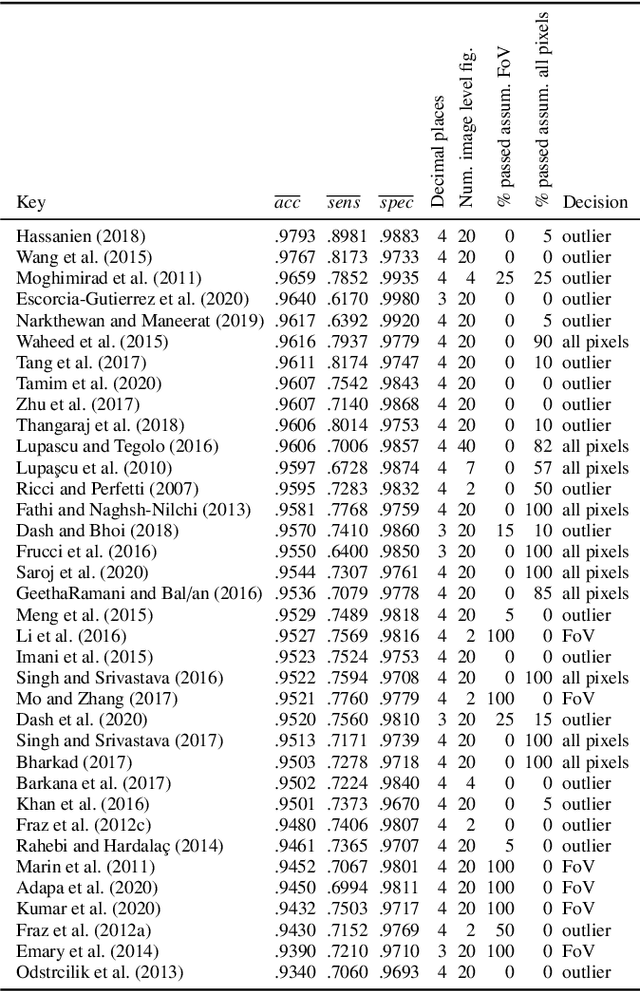
In the last 15 years, the segmentation of vessels in retinal images has become an intensively researched problem in medical imaging, with hundreds of algorithms published. One of the de facto benchmarking data sets of vessel segmentation techniques is the DRIVE data set. Since DRIVE contains a predefined split of training and test images, the published performance results of the various segmentation techniques should provide a reliable ranking of the algorithms. Including more than 100 papers in the study, we performed a detailed numerical analysis of the coherence of the published performance scores. We found inconsistencies in the reported scores related to the use of the field of view (FoV), which has a significant impact on the performance scores. We attempted to eliminate the biases using numerical techniques to provide a more realistic picture of the state of the art. Based on the results, we have formulated several findings, most notably: despite the well-defined test set of DRIVE, most rankings in published papers are based on non-comparable figures; in contrast to the near-perfect accuracy scores reported in the literature, the highest accuracy score achieved to date is 0.9582 in the FoV region, which is 1% higher than that of human annotators. The methods we have developed for identifying and eliminating the evaluation biases can be easily applied to other domains where similar problems may arise.
Approximately Optimal Binning for the Piecewise Constant Approximation of the Normalized Unexplained Variance (nUV) Dissimilarity Measure
Jul 24, 2020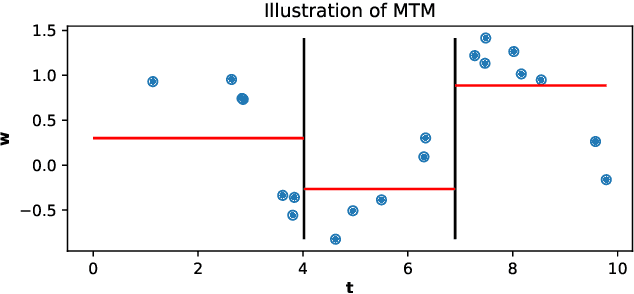
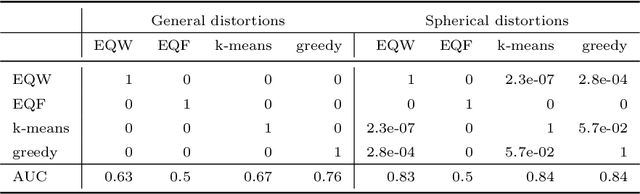
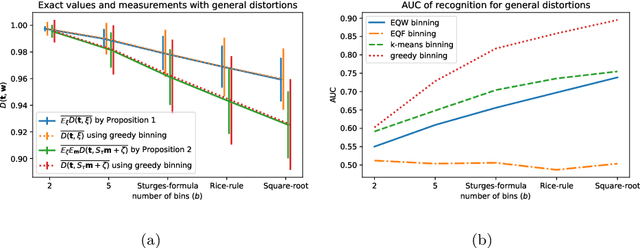
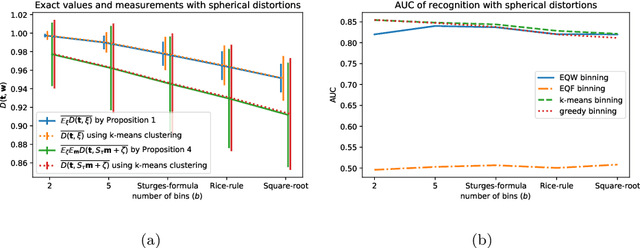
The recently introduced Matching by Tone Mapping (MTM) dissimilarity measure enables template matching under smooth non-linear distortions and also has a well-established mathematical background. MTM operates by binning the template, but the ideal binning for a particular problem is an open question. By pointing out an important analogy between the well known mutual information (MI) and MTM, we introduce the term "normalized unexplained variance" (nUV) for MTM to emphasize its relevance and applicability beyond image processing. Then, we provide theoretical results on the optimal binning technique for the nUV measure and propose algorithms to find approximate solutions. The theoretical findings are supported by numerical experiments. Using the proposed techniques for binning shows 4-13% increase in terms of AUC scores with statistical significance, enabling us to conclude that the proposed binning techniques have the potential to improve the performance of the nUV measure in real applications.
Overly Optimistic Prediction Results on Imbalanced Data: Flaws and Benefits of Applying Over-sampling
Jan 15, 2020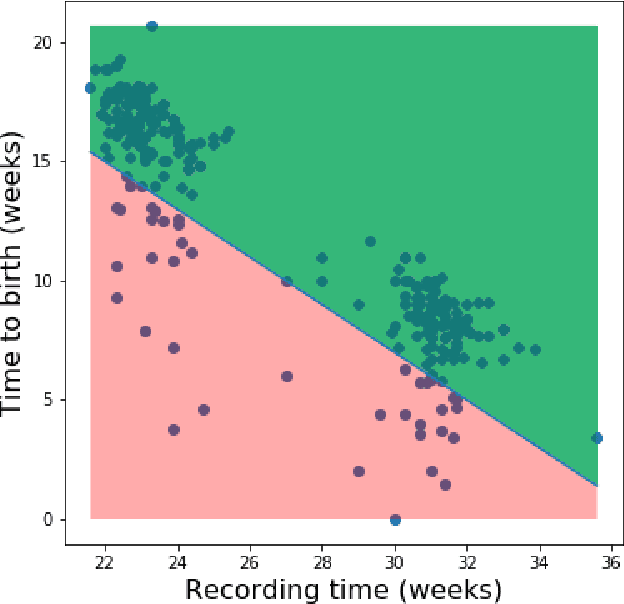
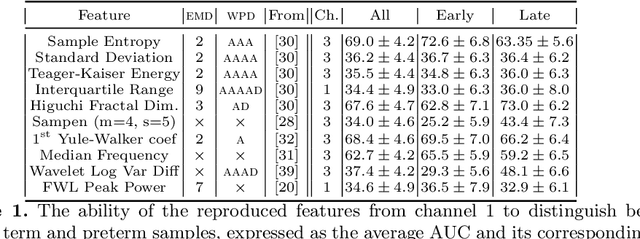
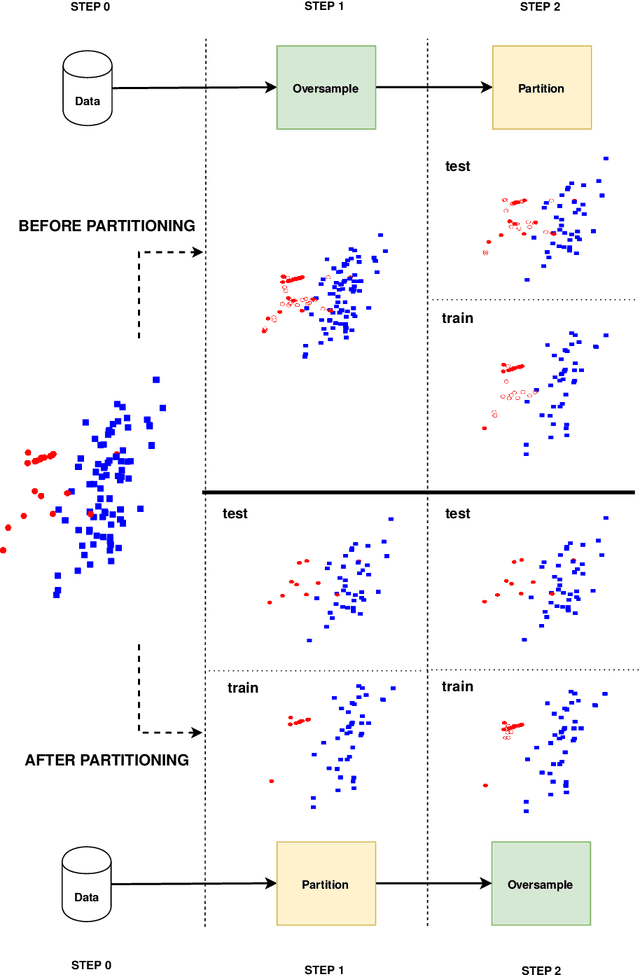
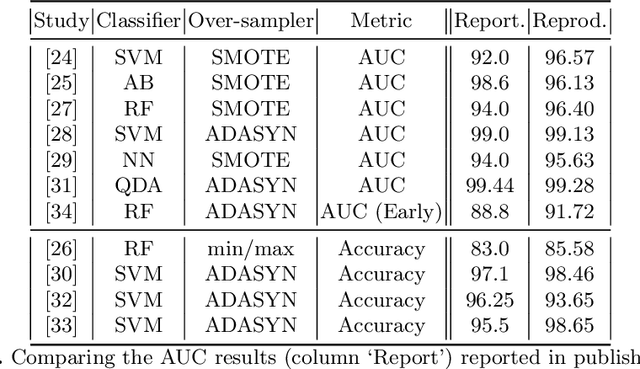
Information extracted from electrohysterography recordings could potentially prove to be an interesting additional source of information to estimate the risk on preterm birth. Recently, a large number of studies have reported near-perfect results to distinguish between recordings of patients that will deliver term or preterm using a public resource, called the Term/Preterm Electrohysterogram database. However, we argue that these results are overly optimistic due to a methodological flaw being made. In this work, we focus on one specific type of methodological flaw: applying over-sampling before partitioning the data into mutually exclusive training and testing sets. We show how this causes the results to be biased using two artificial datasets and reproduce results of studies in which this flaw was identified. Moreover, we evaluate the actual impact of over-sampling on predictive performance, when applied prior to data partitioning, using the same methodologies of related studies, to provide a realistic view of these methodologies' generalization capabilities. We make our research reproducible by providing all the code under an open license.