 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new baseline for retinal vessel segmentation: Numerical identification and correction of methodological inconsistencies affecting 100+ papers
Paper and Code
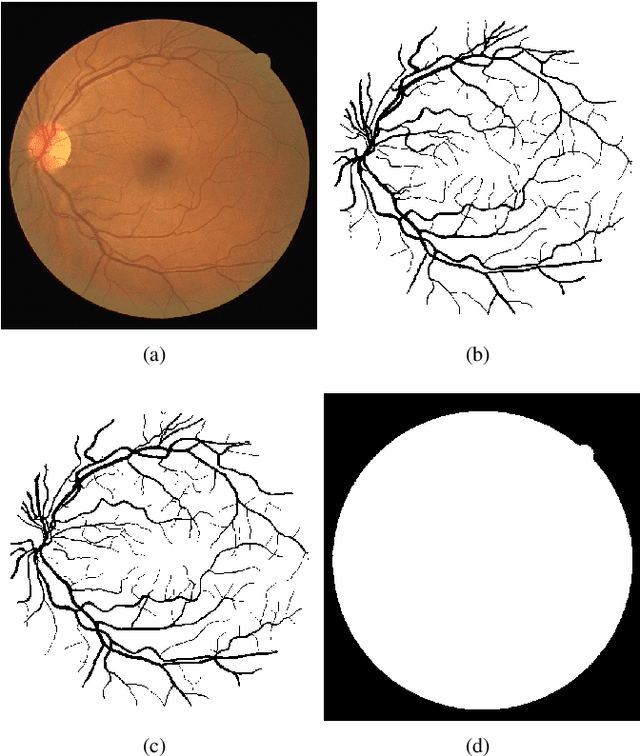
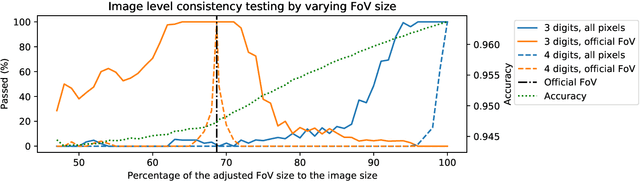
In the last 15 years, the segmentation of vessels in retinal images has become an intensively researched problem in medical imaging, with hundreds of algorithms published. One of the de facto benchmarking data sets of vessel segmentation techniques is the DRIVE data set. Since DRIVE contains a predefined split of training and test images, the published performance results of the various segmentation techniques should provide a reliable ranking of the algorithms. Including more than 100 papers in the study, we performed a detailed numerical analysis of the coherence of the published performance scores. We found inconsistencies in the reported scores related to the use of the field of view (FoV), which has a significant impact on the performance scores. We attempted to eliminate the biases using numerical techniques to provide a more realistic picture of the state of the art. Based on the results, we have formulated several findings, most notably: despite the well-defined test set of DRIVE, most rankings in published papers are based on non-comparable figures; in contrast to the near-perfect accuracy scores reported in the literature, the highest accuracy score achieved to date is 0.9582 in the FoV region, which is 1% higher than that of human annotators. The methods we have developed for identifying and eliminating the evaluation biases can be easily applied to other domains where similar problems may arise.