 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnumerating the k-fold configurations in multi-class classification problems
Jan 24, 2024K-fold cross-validation is a widely used tool for assessing classifier performance. The reproducibility crisis faced by artificial intelligence partly results from the irreproducibility of reported k-fold cross-validation-based performance scores. Recently, we introduced numerical techniques to test the consistency of claimed performance scores and experimental setups. In a crucial use case, the method relies on the combinatorial enumeration of all k-fold configurations, for which we proposed an algorithm in the binary classification case.
mlscorecheck: Testing the consistency of reported performance scores and experiments in machine learning
Nov 13, 2023Addressing the reproducibility crisis in artificial intelligence through the validation of reported experimental results is a challenging task. It necessitates either the reimplementation of techniques or a meticulous assessment of papers for deviations from the scientific method and best statistical practices. To facilitate the validation of reported results, we have developed numerical techniques capable of identifying inconsistencies between reported performance scores and various experimental setups in machine learning problems, including binary/multiclass classification and regression. These consistency tests are integrated into the open-source package mlscorecheck, which also provides specific test bundles designed to detect systematically recurring flaws in various fields, such as retina image processing and synthetic minority oversampling.
Testing the Consistency of Performance Scores Reported for Binary Classification Problems
Oct 19, 2023Binary classification is a fundamental task in machine learning, with applications spanning various scientific domains. Whether scientists are conducting fundamental research or refining practical applications, they typically assess and rank classification techniques based on performance metrics such as accuracy, sensitivity, and specificity. However, reported performance scores may not always serve as a reliable basis for research ranking. This can be attributed to undisclosed or unconventional practices related to cross-validation, typographical errors, and other factors. In a given experimental setup, with a specific number of positive and negative test items, most performance scores can assume specific, interrelated values. In this paper, we introduce numerical techniques to assess the consistency of reported performance scores and the assumed experimental setup. Importantly, the proposed approach does not rely on statistical inference but uses numerical methods to identify inconsistencies with certainty. Through three different applications related to medicine, we demonstrate how the proposed techniques can effectively detect inconsistencies, thereby safeguarding the integrity of research fields. To benefit the scientific community, we have made the consistency tests available in an open-source Python package.
A new baseline for retinal vessel segmentation: Numerical identification and correction of methodological inconsistencies affecting 100+ papers
Nov 06, 2021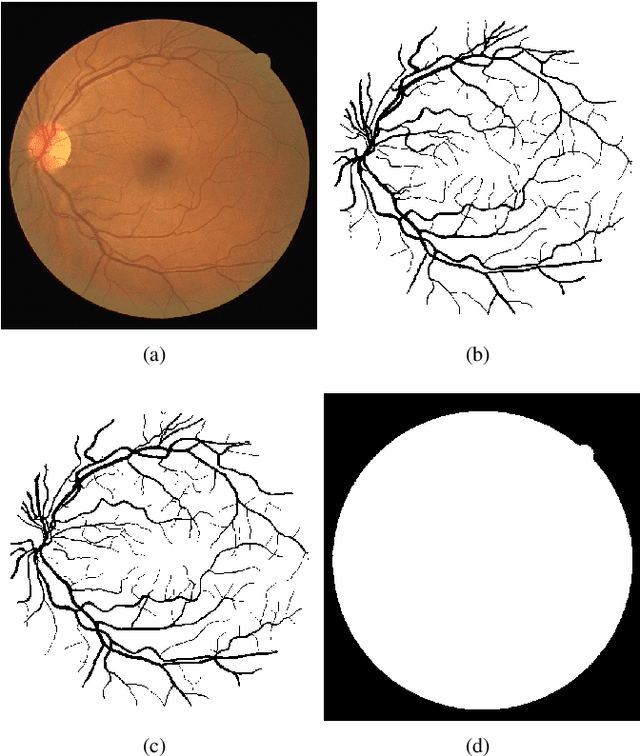
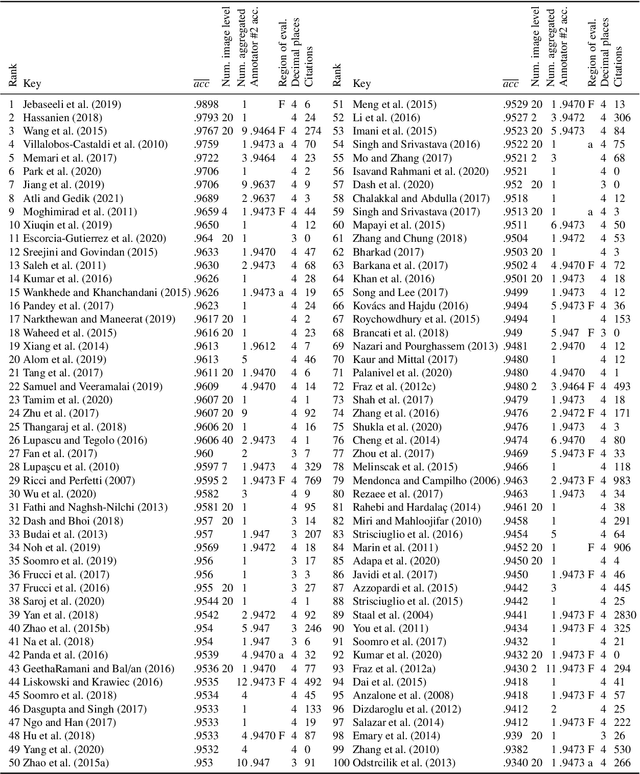
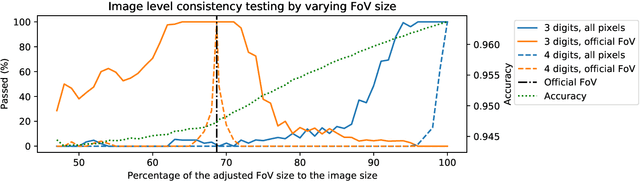
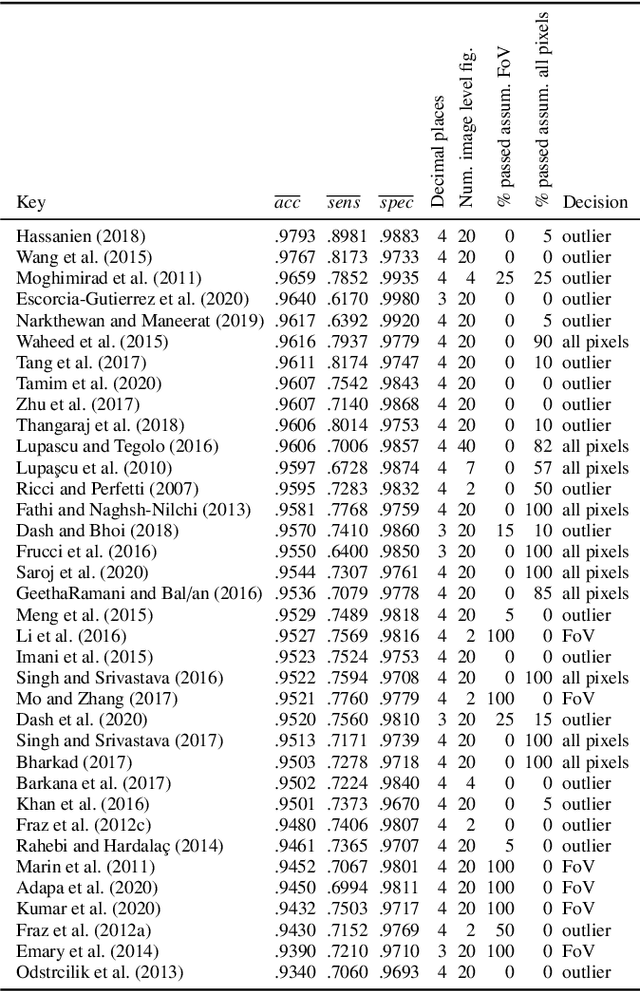
In the last 15 years, the segmentation of vessels in retinal images has become an intensively researched problem in medical imaging, with hundreds of algorithms published. One of the de facto benchmarking data sets of vessel segmentation techniques is the DRIVE data set. Since DRIVE contains a predefined split of training and test images, the published performance results of the various segmentation techniques should provide a reliable ranking of the algorithms. Including more than 100 papers in the study, we performed a detailed numerical analysis of the coherence of the published performance scores. We found inconsistencies in the reported scores related to the use of the field of view (FoV), which has a significant impact on the performance scores. We attempted to eliminate the biases using numerical techniques to provide a more realistic picture of the state of the art. Based on the results, we have formulated several findings, most notably: despite the well-defined test set of DRIVE, most rankings in published papers are based on non-comparable figures; in contrast to the near-perfect accuracy scores reported in the literature, the highest accuracy score achieved to date is 0.9582 in the FoV region, which is 1% higher than that of human annotators. The methods we have developed for identifying and eliminating the evaluation biases can be easily applied to other domains where similar problems may arise.
Approximately Optimal Binning for the Piecewise Constant Approximation of the Normalized Unexplained Variance (nUV) Dissimilarity Measure
Jul 24, 2020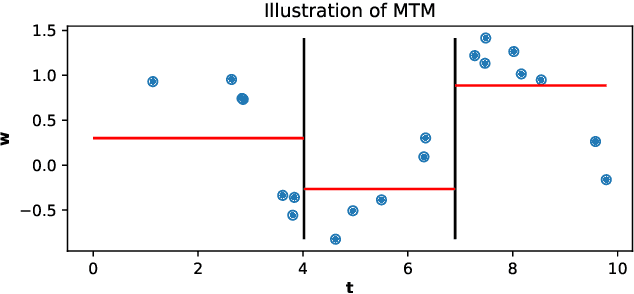
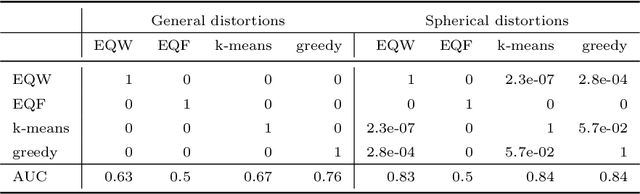
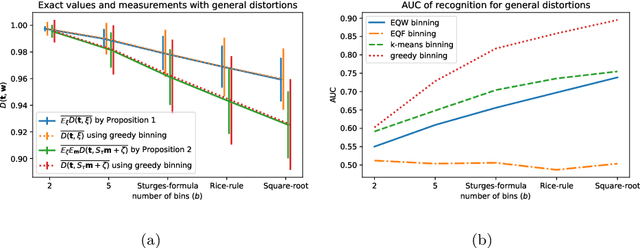
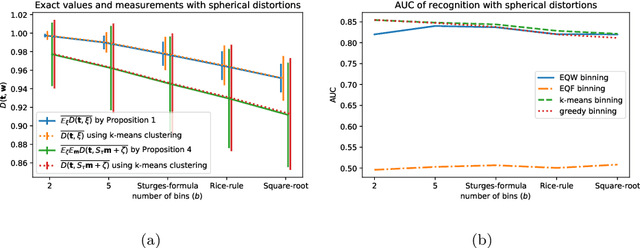
The recently introduced Matching by Tone Mapping (MTM) dissimilarity measure enables template matching under smooth non-linear distortions and also has a well-established mathematical background. MTM operates by binning the template, but the ideal binning for a particular problem is an open question. By pointing out an important analogy between the well known mutual information (MI) and MTM, we introduce the term "normalized unexplained variance" (nUV) for MTM to emphasize its relevance and applicability beyond image processing. Then, we provide theoretical results on the optimal binning technique for the nUV measure and propose algorithms to find approximate solutions. The theoretical findings are supported by numerical experiments. Using the proposed techniques for binning shows 4-13% increase in terms of AUC scores with statistical significance, enabling us to conclude that the proposed binning techniques have the potential to improve the performance of the nUV measure in real applications.