 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Synthetic Data Generated by Deep Generative Models
Nov 06, 2024
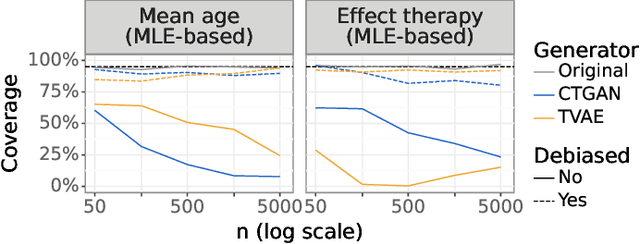
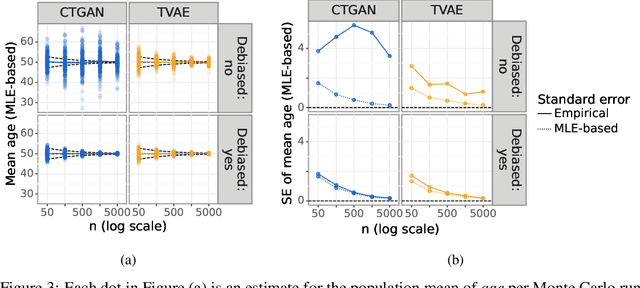
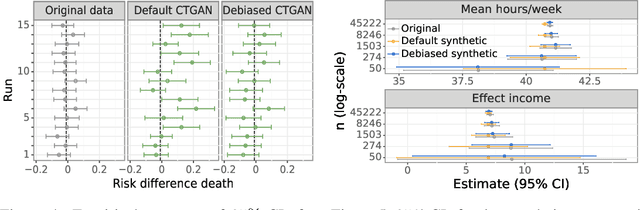
While synthetic data hold great promise for privacy protection, their statistical analysis poses significant challenges that necessitate innovative solutions. The use of deep generative models (DGMs) for synthetic data generation is known to induce considerable bias and imprecision into synthetic data analyses, compromising their inferential utility as opposed to original data analyses. This bias and uncertainty can be substantial enough to impede statistical convergence rates, even in seemingly straightforward analyses like mean calculation. The standard errors of such estimators then exhibit slower shrinkage with sample size than the typical 1 over root-$n$ rate. This complicates fundamental calculations like p-values and confidence intervals, with no straightforward remedy currently available. In response to these challenges, we propose a new strategy that targets synthetic data created by DGMs for specific data analyses. Drawing insights from debiased and targeted machine learning, our approach accounts for biases, enhances convergence rates, and facilitates the calculation of estimators with easily approximated large sample variances. We exemplify our proposal through a simulation study on toy data and two case studies on real-world data, highlighting the importance of tailoring DGMs for targeted data analysis. This debiasing strategy contributes to advancing the reliability and applicability of synthetic data in statistical inference.
Synthetic Data: Can We Trust Statistical Estimators?
Dec 13, 2023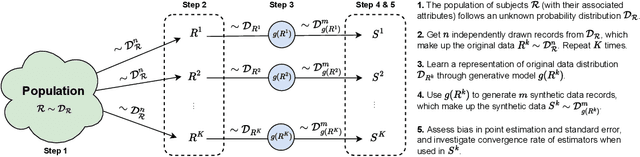

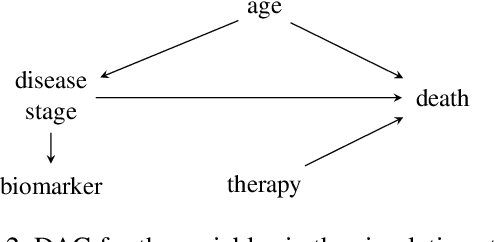
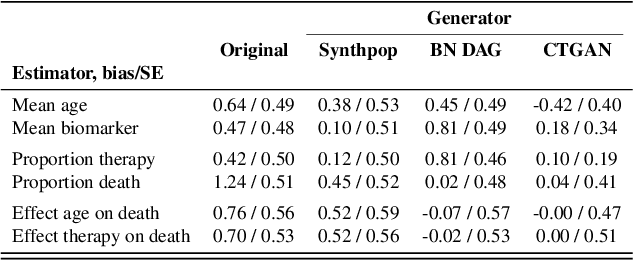
The increasing interest in data sharing makes synthetic data appealing. However, the analysis of synthetic data raises a unique set of methodological challenges. In this work, we highlight the importance of inferential utility and provide empirical evidence against naive inference from synthetic data (that handles these as if they were really observed). We argue that the rate of false-positive findings (type 1 error) will be unacceptably high, even when the estimates are unbiased. One of the reasons is the underestimation of the true standard error, which may even progressively increase with larger sample sizes due to slower convergence. This is especially problematic for deep generative models. Before publishing synthetic data, it is essential to develop statistical inference tools for such data.
Overly Optimistic Prediction Results on Imbalanced Data: Flaws and Benefits of Applying Over-sampling
Jan 15, 2020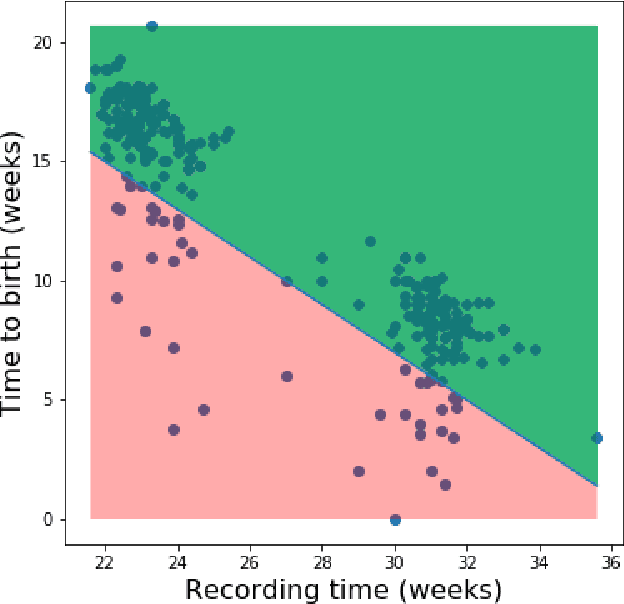
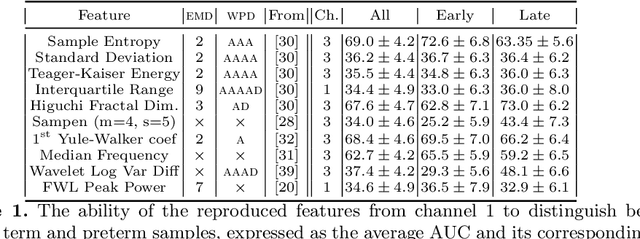
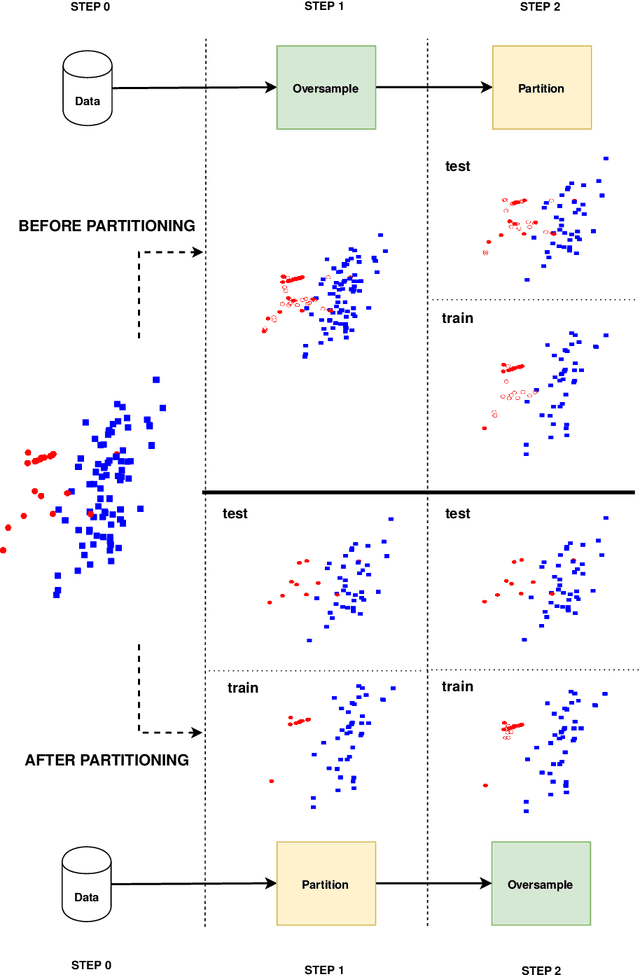
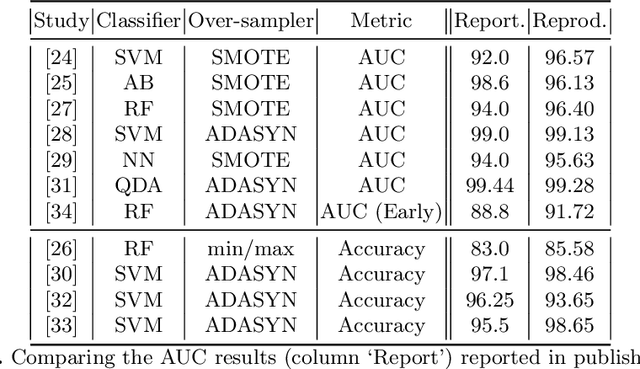
Information extracted from electrohysterography recordings could potentially prove to be an interesting additional source of information to estimate the risk on preterm birth. Recently, a large number of studies have reported near-perfect results to distinguish between recordings of patients that will deliver term or preterm using a public resource, called the Term/Preterm Electrohysterogram database. However, we argue that these results are overly optimistic due to a methodological flaw being made. In this work, we focus on one specific type of methodological flaw: applying over-sampling before partitioning the data into mutually exclusive training and testing sets. We show how this causes the results to be biased using two artificial datasets and reproduce results of studies in which this flaw was identified. Moreover, we evaluate the actual impact of over-sampling on predictive performance, when applied prior to data partitioning, using the same methodologies of related studies, to provide a realistic view of these methodologies' generalization capabilities. We make our research reproducible by providing all the code under an open license.
Positive blood culture detection in time series data using a BiLSTM network
Dec 03, 2016


The presence of bacteria or fungi in the bloodstream of patients is abnormal and can lead to life-threatening conditions. A computational model based on a bidirectional long short-term memory artificial neural network, is explored to assist doctors in the intensive care unit to predict whether examination of blood cultures of patients will return positive. As input it uses nine monitored clinical parameters, presented as time series data, collected from 2177 ICU admissions at the Ghent University Hospital. Our main goal is to determine if general machine learning methods and more specific, temporal models, can be used to create an early detection system. This preliminary research obtains an area of 71.95% under the precision recall curve, proving the potential of temporal neural networks in this context.