 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data: Can We Trust Statistical Estimators?
Paper and Code
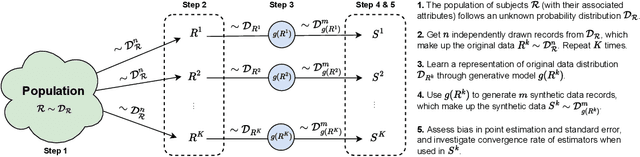

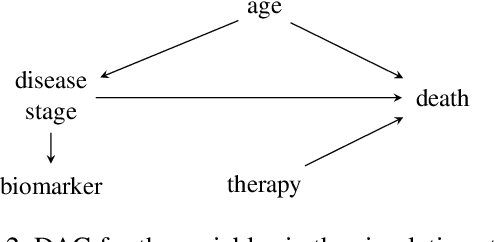
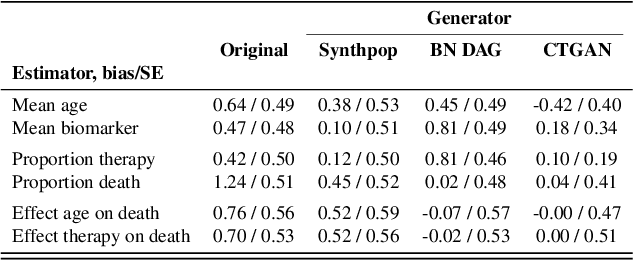
The increasing interest in data sharing makes synthetic data appealing. However, the analysis of synthetic data raises a unique set of methodological challenges. In this work, we highlight the importance of inferential utility and provide empirical evidence against naive inference from synthetic data (that handles these as if they were really observed). We argue that the rate of false-positive findings (type 1 error) will be unacceptably high, even when the estimates are unbiased. One of the reasons is the underestimation of the true standard error, which may even progressively increase with larger sample sizes due to slower convergence. This is especially problematic for deep generative models. Before publishing synthetic data, it is essential to develop statistical inference tools for such data.