 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models
May 19, 2025Chart understanding presents a unique challenge for large vision-language models (LVLMs), as it requires the integration of sophisticated textual and visual reasoning capabilities. However, current LVLMs exhibit a notable imbalance between these skills, falling short on visual reasoning that is difficult to perform in text. We conduct a case study using a synthetic dataset solvable only through visual reasoning and show that model performance degrades significantly with increasing visual complexity, while human performance remains robust. We then introduce ChartMuseum, a new Chart Question Answering (QA) benchmark containing 1,162 expert-annotated questions spanning multiple reasoning types, curated from real-world charts across 184 sources, specifically built to evaluate complex visual and textual reasoning. Unlike prior chart understanding benchmarks -- where frontier models perform similarly and near saturation -- our benchmark exposes a substantial gap between model and human performance, while effectively differentiating model capabilities: although humans achieve 93% accuracy, the best-performing model Gemini-2.5-Pro attains only 63.0%, and the leading open-source LVLM Qwen2.5-VL-72B-Instruct achieves only 38.5%. Moreover, on questions requiring primarily visual reasoning, all models experience a 35%-55% performance drop from text-reasoning-heavy question performance. Lastly, our qualitative error analysis reveals specific categories of visual reasoning that are challenging for current LVLMs.
EvalAgent: Discovering Implicit Evaluation Criteria from the Web
Apr 21, 2025Evaluation of language model outputs on structured writing tasks is typically conducted with a number of desirable criteria presented to human evaluators or large language models (LLMs). For instance, on a prompt like "Help me draft an academic talk on coffee intake vs research productivity", a model response may be evaluated for criteria like accuracy and coherence. However, high-quality responses should do more than just satisfy basic task requirements. An effective response to this query should include quintessential features of an academic talk, such as a compelling opening, clear research questions, and a takeaway. To help identify these implicit criteria, we introduce EvalAgent, a novel framework designed to automatically uncover nuanced and task-specific criteria. EvalAgent first mines expert-authored online guidance. It then uses this evidence to propose diverse, long-tail evaluation criteria that are grounded in reliable external sources. Our experiments demonstrate that the grounded criteria produced by EvalAgent are often implicit (not directly stated in the user's prompt), yet specific (high degree of lexical precision). Further, EvalAgent criteria are often not satisfied by initial responses but they are actionable, such that responses can be refined to satisfy them. Finally, we show that combining LLM-generated and EvalAgent criteria uncovers more human-valued criteria than using LLMs alone.
Pairwise or Pointwise? Evaluating Feedback Protocols for Bias in LLM-Based Evaluation
Apr 20, 2025

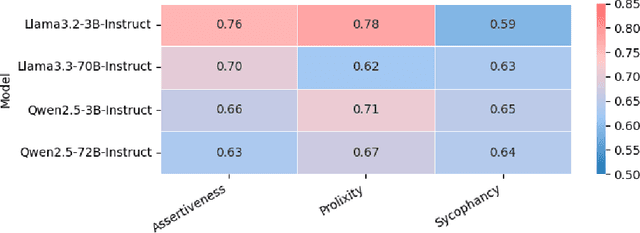

Large Language Models (LLMs) are widely used as proxies for human labelers in both training (Reinforcement Learning from AI Feedback) and large-scale response evaluation (LLM-as-a-judge). Alignment and evaluation are critical components in the development of reliable LLMs, and the choice of feedback protocol plays a central role in both but remains understudied. In this work, we show that the choice of feedback protocol (absolute scores versus relative preferences) can significantly affect evaluation reliability and induce systematic biases. In particular, we show that pairwise evaluation protocols are more vulnerable to distracted evaluation. Generator models can exploit spurious attributes (or distractor features) favored by the LLM judge, resulting in inflated scores for lower-quality outputs and misleading training signals. We find that absolute scoring is more robust to such manipulation, producing judgments that better reflect response quality and are less influenced by distractor features. Our results demonstrate that generator models can flip preferences by embedding distractor features, skewing LLM-as-a-judge comparisons and leading to inaccurate conclusions about model quality in benchmark evaluations. Pairwise preferences flip in about 35% of the cases, compared to only 9% for absolute scores. We offer recommendations for choosing feedback protocols based on dataset characteristics and evaluation objectives.
QUDsim: Quantifying Discourse Similarities in LLM-Generated Text
Apr 12, 2025



As large language models become increasingly capable at various writing tasks, their weakness at generating unique and creative content becomes a major liability. Although LLMs have the ability to generate text covering diverse topics, there is an overall sense of repetitiveness across texts that we aim to formalize and quantify via a similarity metric. The familiarity between documents arises from the persistence of underlying discourse structures. However, existing similarity metrics dependent on lexical overlap and syntactic patterns largely capture $\textit{content}$ overlap, thus making them unsuitable for detecting $\textit{structural}$ similarities. We introduce an abstraction based on linguistic theories in Questions Under Discussion (QUD) and question semantics to help quantify differences in discourse progression. We then use this framework to build $\textbf{QUDsim}$, a similarity metric that can detect discursive parallels between documents. Using QUDsim, we find that LLMs often reuse discourse structures (more so than humans) across samples, even when content differs. Furthermore, LLMs are not only repetitive and structurally uniform, but are also divergent from human authors in the types of structures they use.
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning
Sep 18, 2024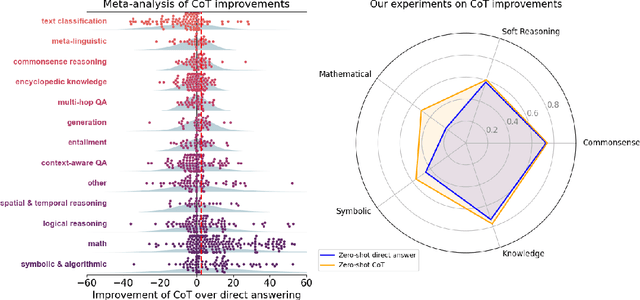


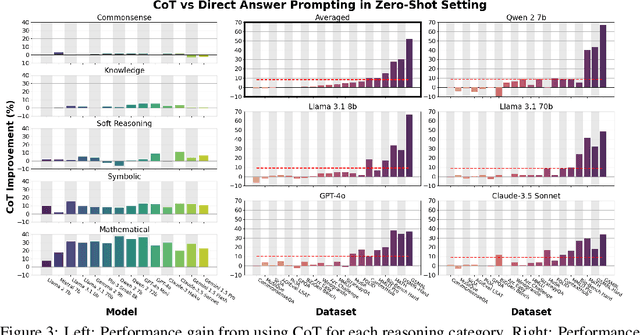
Chain-of-thought (CoT) via prompting is the de facto method for eliciting reasoning capabilities from large language models (LLMs). But for what kinds of tasks is this extra ``thinking'' really helpful? To analyze this, we conducted a quantitative meta-analysis covering over 100 papers using CoT and ran our own evaluations of 20 datasets across 14 models. Our results show that CoT gives strong performance benefits primarily on tasks involving math or logic, with much smaller gains on other types of tasks. On MMLU, directly generating the answer without CoT leads to almost identical accuracy as CoT unless the question or model's response contains an equals sign, indicating symbolic operations and reasoning. Following this finding, we analyze the behavior of CoT on these problems by separating planning and execution and comparing against tool-augmented LLMs. Much of CoT's gain comes from improving symbolic execution, but it underperforms relative to using a symbolic solver. Our results indicate that CoT can be applied selectively, maintaining performance while saving inference costs. Furthermore, they suggest a need to move beyond prompt-based CoT to new paradigms that better leverage intermediate computation across the whole range of LLM applications.
Learning to Refine with Fine-Grained Natural Language Feedback
Jul 02, 2024Recent work has explored the capability of large language models (LLMs) to identify and correct errors in LLM-generated responses. These refinement approaches frequently evaluate what sizes of models are able to do refinement for what problems, but less attention is paid to what effective feedback for refinement looks like. In this work, we propose looking at refinement with feedback as a composition of three distinct LLM competencies: (1) identification of bad generations; (2) fine-grained natural language feedback generation; (3) refining with fine-grained feedback. The first step can be implemented with a high-performing discriminative model and steps 2 and 3 can be implemented either via prompted or fine-tuned LLMs. A key property of this approach is that the step 2 critique model can give fine-grained feedback about errors, made possible by offloading the discrimination to a separate model in step 1. We show that models of different capabilities benefit from refining with this approach on the task of improving factual consistency of document grounded summaries. Overall, our proposed method consistently outperforms existing end-to-end refinement approaches and current trained models not fine-tuned for factuality critiquing.
Using Natural Language Explanations to Rescale Human Judgments
May 24, 2023



The rise of large language models (LLMs) has brought a critical need for high-quality human-labeled data, particularly for processes like human feedback and evaluation. A common practice is to label data via consensus annotation over the judgments of multiple crowdworkers. However, different annotators may have different interpretations of labeling schemes unless given extensive training, and for subjective NLP tasks, even trained expert annotators can diverge heavily. We show that these nuances can be captured by high quality natural language explanations, and propose a method to rescale ordinal annotation in the presence of disagreement using LLMs. Specifically, we feed Likert ratings and corresponding natural language explanations into an LLM and prompt it to produce a numeric score. This score should reflect the underlying assessment of the example by the annotator. The presence of explanations allows the LLM to homogenize ratings across annotators in spite of scale usage differences. We explore our technique in the context of a document-grounded question answering task on which large language models achieve near-human performance. Among questions where annotators identify incompleteness in the answers, our rescaling improves correlation between nearly all annotator pairs, improving pairwise correlation on these examples by an average of 0.2 Kendall's tau.
Group Affect Prediction Using Multimodal Distributions
Mar 12, 2018

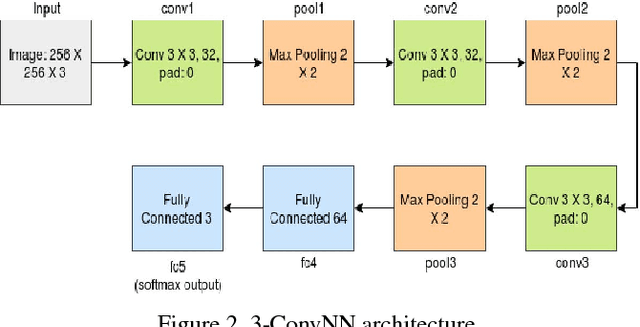
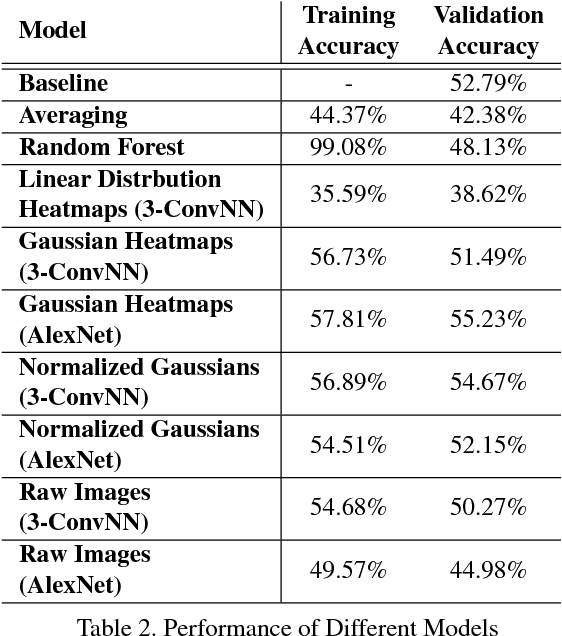
We describe our approach towards building an efficient predictive model to detect emotions for a group of people in an image. We have proposed that training a Convolutional Neural Network (CNN) model on the emotion heatmaps extracted from the image, outperforms a CNN model trained entirely on the raw images. The comparison of the models have been done on a recently published dataset of Emotion Recognition in the Wild (EmotiW) challenge, 2017. The proposed method achieved validation accuracy of 55.23% which is 2.44% above the baseline accuracy, provided by the EmotiW organizers.