 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWSSAMNet: Weakly Supervised Semantic Attentive Medical Image Registration Network
Mar 05, 2022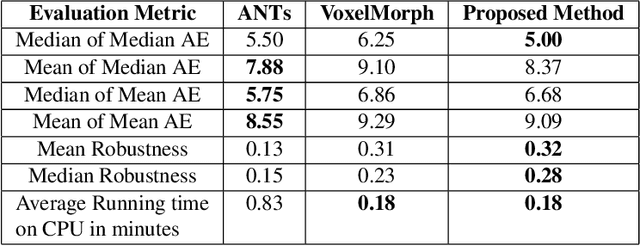
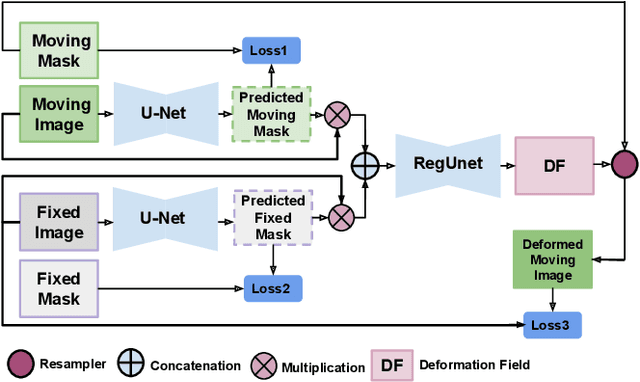
We present WSSAMNet, a weakly supervised method for medical image registration. Ours is a two step method, with the first step being the computation of segmentation masks of the fixed and moving volumes. These masks are then used to attend to the input volume, which are then provided as inputs to a registration network in the second step. The registration network computes the deformation field to perform the alignment between the fixed and the moving volumes. We study the effectiveness of our technique on the BraTSReg challenge data against ANTs and VoxelMorph, where we demonstrate that our method performs competitively.
Perceptual cGAN for MRI Super-resolution
Jan 23, 2022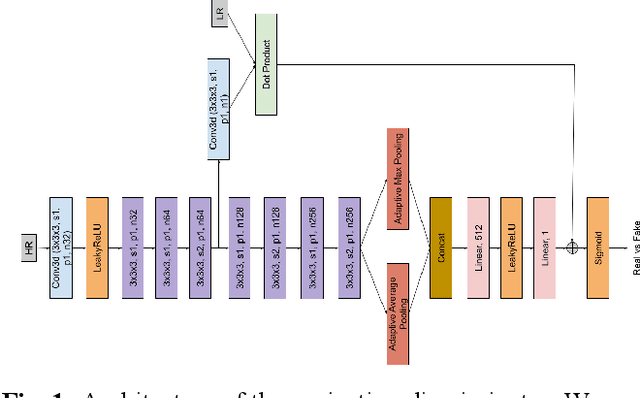

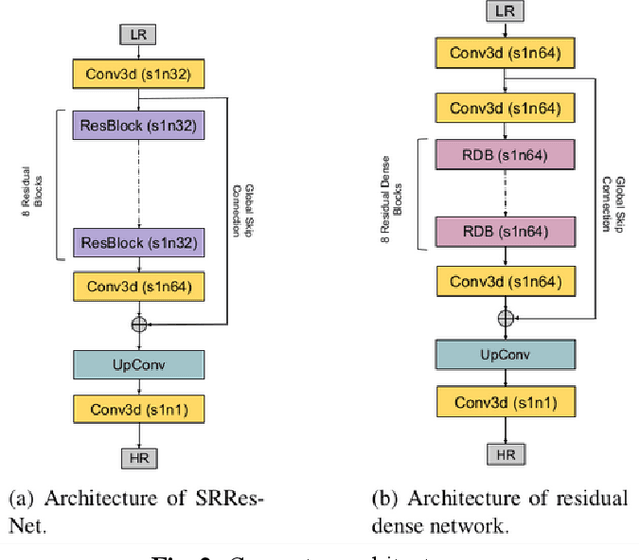
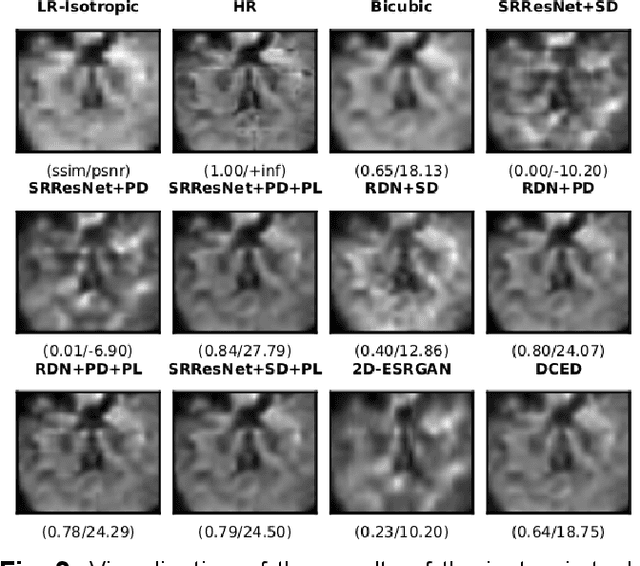
Capturing high-resolution magnetic resonance (MR) images is a time consuming process, which makes it unsuitable for medical emergencies and pediatric patients. Low-resolution MR imaging, by contrast, is faster than its high-resolution counterpart, but it compromises on fine details necessary for a more precise diagnosis. Super-resolution (SR), when applied to low-resolution MR images, can help increase their utility by synthetically generating high-resolution images with little additional time. In this paper, we present a SR technique for MR images that is based on generative adversarial networks (GANs), which have proven to be quite useful in generating sharp-looking details in SR. We introduce a conditional GAN with perceptual loss, which is conditioned upon the input low-resolution image, which improves the performance for isotropic and anisotropic MRI super-resolution.
Self-Supervised Visual Representation Learning Using Lightweight Architectures
Oct 21, 2021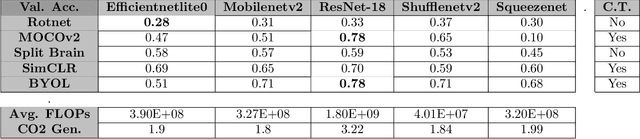
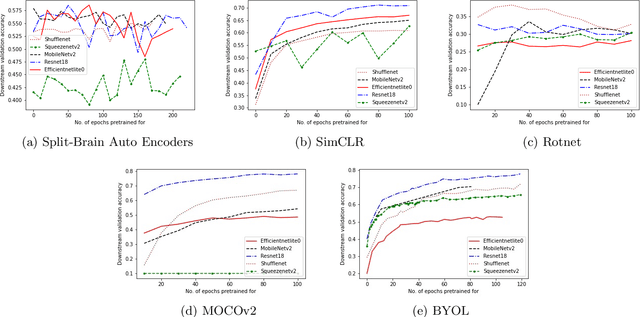
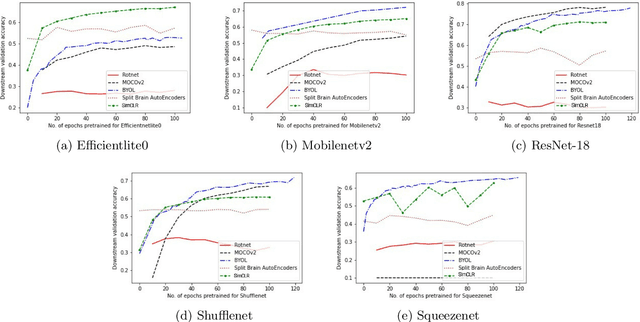

In self-supervised learning, a model is trained to solve a pretext task, using a data set whose annotations are created by a machine. The objective is to transfer the trained weights to perform a downstream task in the target domain. We critically examine the most notable pretext tasks to extract features from image data and further go on to conduct experiments on resource constrained networks, which aid faster experimentation and deployment. We study the performance of various self-supervised techniques keeping all other parameters uniform. We study the patterns that emerge by varying model type, size and amount of pre-training done for the backbone as well as establish a standard to compare against for future research. We also conduct comprehensive studies to understand the quality of representations learned by different architectures.
Group Affect Prediction Using Multimodal Distributions
Mar 12, 2018

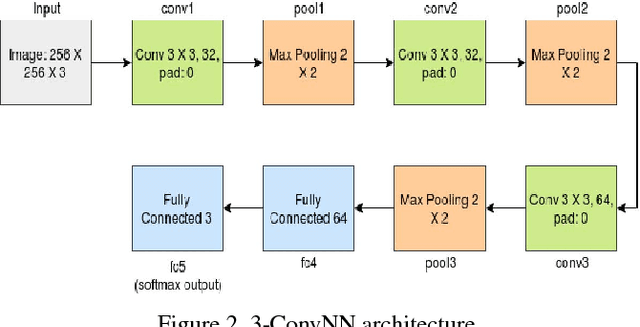
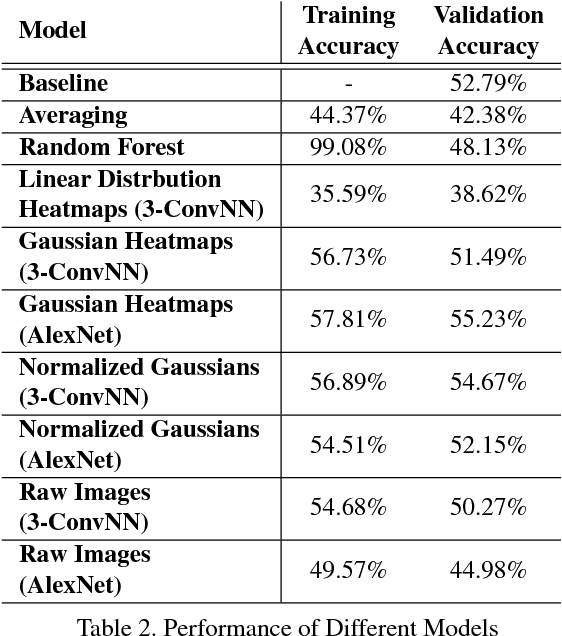
We describe our approach towards building an efficient predictive model to detect emotions for a group of people in an image. We have proposed that training a Convolutional Neural Network (CNN) model on the emotion heatmaps extracted from the image, outperforms a CNN model trained entirely on the raw images. The comparison of the models have been done on a recently published dataset of Emotion Recognition in the Wild (EmotiW) challenge, 2017. The proposed method achieved validation accuracy of 55.23% which is 2.44% above the baseline accuracy, provided by the EmotiW organizers.