 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Enhanced SAM3 for Occlusion-Robust Surgical Instrument Segmentation
Dec 18, 2025Accurate surgical instrument segmentation in endoscopic videos is crucial for computer-assisted interventions, yet remains challenging due to frequent occlusions, rapid motion, specular artefacts, and long-term instrument re-entry. While SAM3 provides a powerful spatio-temporal framework for video object segmentation, its performance in surgical scenes is limited by indiscriminate memory updates, fixed memory capacity, and weak identity recovery after occlusions. We propose ReMeDI-SAM3, a training-free memory-enhanced extension of SAM3, that addresses these limitations through three components: (i) relevance-aware memory filtering with a dedicated occlusion-aware memory for storing pre-occlusion frames, (ii) a piecewise interpolation scheme that expands the effective memory capacity, and (iii) a feature-based re-identification module with temporal voting for reliable post-occlusion identity disambiguation. Together, these components mitigate error accumulation and enable reliable recovery after occlusions. Evaluations on EndoVis17 and EndoVis18 under a zero-shot setting show absolute mcIoU improvements of around 7% and 16%, respectively, over vanilla SAM3, outperforming even prior training-based approaches. Project page: https://valaybundele.github.io/remedi-sam3/.
HistDiST: Histopathological Diffusion-based Stain Transfer
May 11, 2025



Hematoxylin and Eosin (H&E) staining is the cornerstone of histopathology but lacks molecular specificity. While Immunohistochemistry (IHC) provides molecular insights, it is costly and complex, motivating H&E-to-IHC translation as a cost-effective alternative. Existing translation methods are mainly GAN-based, often struggling with training instability and limited structural fidelity, while diffusion-based approaches remain underexplored. We propose HistDiST, a Latent Diffusion Model (LDM) based framework for high-fidelity H&E-to-IHC translation. HistDiST introduces a dual-conditioning strategy, utilizing Phikon-extracted morphological embeddings alongside VAE-encoded H&E representations to ensure pathology-relevant context and structural consistency. To overcome brightness biases, we incorporate a rescaled noise schedule, v-prediction, and trailing timesteps, enforcing a zero-SNR condition at the final timestep. During inference, DDIM inversion preserves the morphological structure, while an eta-cosine noise schedule introduces controlled stochasticity, balancing structural consistency and molecular fidelity. Moreover, we propose Molecular Retrieval Accuracy (MRA), a novel pathology-aware metric leveraging GigaPath embeddings to assess molecular relevance. Extensive evaluations on MIST and BCI datasets demonstrate that HistDiST significantly outperforms existing methods, achieving a 28% improvement in MRA on the H&E-to-Ki67 translation task, highlighting its effectiveness in capturing true IHC semantics.
You Are Your Best Teacher: Semi-Supervised Surgical Point Tracking with Cycle-Consistent Self-Distillation
May 09, 2025



Synthetic datasets have enabled significant progress in point tracking by providing large-scale, densely annotated supervision. However, deploying these models in real-world domains remains challenging due to domain shift and lack of labeled data-issues that are especially severe in surgical videos, where scenes exhibit complex tissue deformation, occlusion, and lighting variation. While recent approaches adapt synthetic-trained trackers to natural videos using teacher ensembles or augmentation-heavy pseudo-labeling pipelines, their effectiveness in high-shift domains like surgery remains unexplored. This work presents SurgTracker, a semi-supervised framework for adapting synthetic-trained point trackers to surgical video using filtered self-distillation. Pseudo-labels are generated online by a fixed teacher-identical in architecture and initialization to the student-and are filtered using a cycle consistency constraint to discard temporally inconsistent trajectories. This simple yet effective design enforces geometric consistency and provides stable supervision throughout training, without the computational overhead of maintaining multiple teachers. Experiments on the STIR benchmark show that SurgTracker improves tracking performance using only 80 unlabeled videos, demonstrating its potential for robust adaptation in high-shift, data-scarce domains.
Evaluating Self-Supervised Learning in Medical Imaging: A Benchmark for Robustness, Generalizability, and Multi-Domain Impact
Dec 26, 2024Self-supervised learning (SSL) has emerged as a promising paradigm in medical imaging, addressing the chronic challenge of limited labeled data in healthcare settings. While SSL has shown impressive results, existing studies in the medical domain are often limited in scope, focusing on specific datasets or modalities, or evaluating only isolated aspects of model performance. This fragmented evaluation approach poses a significant challenge, as models deployed in critical medical settings must not only achieve high accuracy but also demonstrate robust performance and generalizability across diverse datasets and varying conditions. To address this gap, we present a comprehensive evaluation of SSL methods within the medical domain, with a particular focus on robustness and generalizability. Using the MedMNIST dataset collection as a standardized benchmark, we evaluate 8 major SSL methods across 11 different medical datasets. Our study provides an in-depth analysis of model performance in both in-domain scenarios and the detection of out-of-distribution (OOD) samples, while exploring the effect of various initialization strategies, model architectures, and multi-domain pre-training. We further assess the generalizability of SSL methods through cross-dataset evaluations and the in-domain performance with varying label proportions (1%, 10%, and 100%) to simulate real-world scenarios with limited supervision. We hope this comprehensive benchmark helps practitioners and researchers make more informed decisions when applying SSL methods to medical applications.
Scaling Vision-and-Language Navigation With Offline RL
Mar 27, 2024The study of vision-and-language navigation (VLN) has typically relied on expert trajectories, which may not always be available in real-world situations due to the significant effort required to collect them. On the other hand, existing approaches to training VLN agents that go beyond available expert data involve data augmentations or online exploration which can be tedious and risky. In contrast, it is easy to access large repositories of suboptimal offline trajectories. Inspired by research in offline reinforcement learning (ORL), we introduce a new problem setup of VLN-ORL which studies VLN using suboptimal demonstration data. We introduce a simple and effective reward-conditioned approach that can account for dataset suboptimality for training VLN agents, as well as benchmarks to evaluate progress and promote research in this area. We empirically study various noise models for characterizing dataset suboptimality among other unique challenges in VLN-ORL and instantiate it for the VLN$\circlearrowright$BERT and MTVM architectures in the R2R and RxR environments. Our experiments demonstrate that the proposed reward-conditioned approach leads to significant performance improvements, even in complex and intricate environments.
Learning Class and Domain Augmentations for Single-Source Open-Domain Generalization
Nov 05, 2023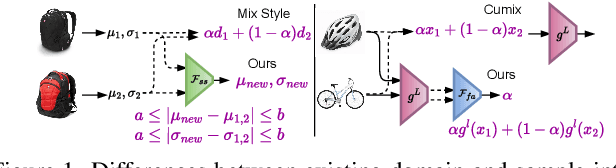
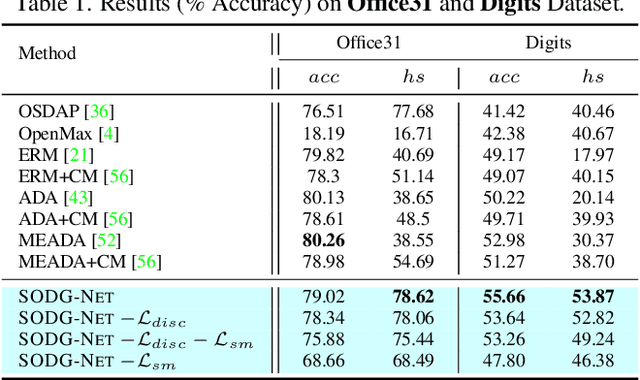
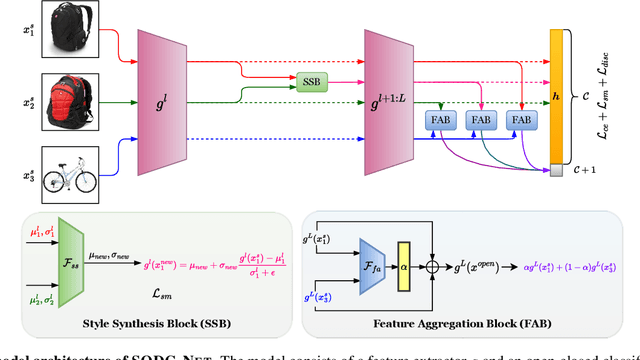
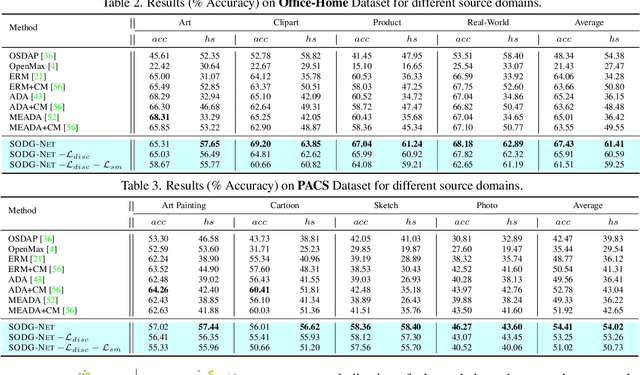
Single-source open-domain generalization (SS-ODG) addresses the challenge of labeled source domains with supervision during training and unlabeled novel target domains during testing. The target domain includes both known classes from the source domain and samples from previously unseen classes. Existing techniques for SS-ODG primarily focus on calibrating source-domain classifiers to identify open samples in the target domain. However, these methods struggle with visually fine-grained open-closed data, often misclassifying open samples as closed-set classes. Moreover, relying solely on a single source domain restricts the model's ability to generalize. To overcome these limitations, we propose a novel framework called SODG-Net that simultaneously synthesizes novel domains and generates pseudo-open samples using a learning-based objective, in contrast to the ad-hoc mixing strategies commonly found in the literature. Our approach enhances generalization by diversifying the styles of known class samples using a novel metric criterion and generates diverse pseudo-open samples to train a unified and confident multi-class classifier capable of handling both open and closed-set data. Extensive experimental evaluations conducted on multiple benchmarks consistently demonstrate the superior performance of SODG-Net compared to the literature.
Perceptual cGAN for MRI Super-resolution
Jan 23, 2022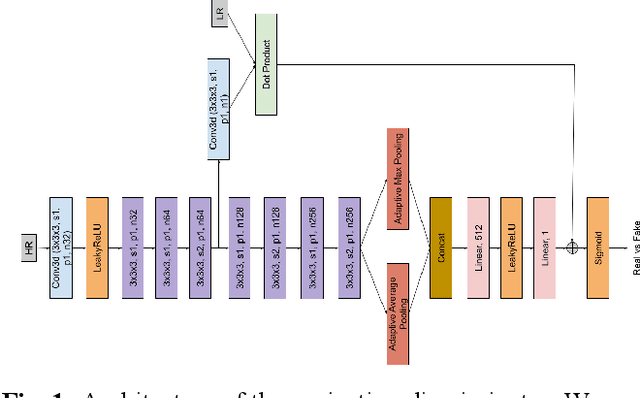

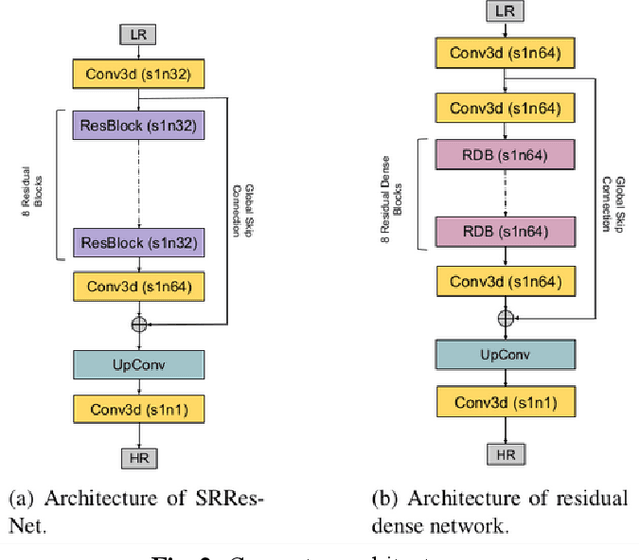
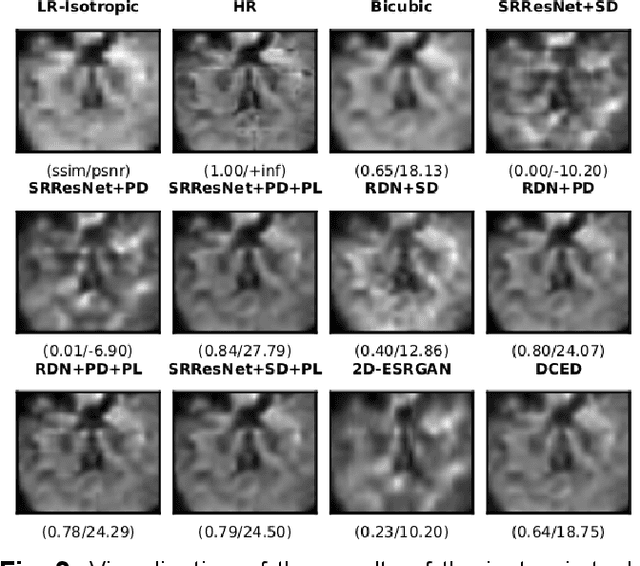
Capturing high-resolution magnetic resonance (MR) images is a time consuming process, which makes it unsuitable for medical emergencies and pediatric patients. Low-resolution MR imaging, by contrast, is faster than its high-resolution counterpart, but it compromises on fine details necessary for a more precise diagnosis. Super-resolution (SR), when applied to low-resolution MR images, can help increase their utility by synthetically generating high-resolution images with little additional time. In this paper, we present a SR technique for MR images that is based on generative adversarial networks (GANs), which have proven to be quite useful in generating sharp-looking details in SR. We introduce a conditional GAN with perceptual loss, which is conditioned upon the input low-resolution image, which improves the performance for isotropic and anisotropic MRI super-resolution.