 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Are Your Best Teacher: Semi-Supervised Surgical Point Tracking with Cycle-Consistent Self-Distillation
May 09, 2025



Synthetic datasets have enabled significant progress in point tracking by providing large-scale, densely annotated supervision. However, deploying these models in real-world domains remains challenging due to domain shift and lack of labeled data-issues that are especially severe in surgical videos, where scenes exhibit complex tissue deformation, occlusion, and lighting variation. While recent approaches adapt synthetic-trained trackers to natural videos using teacher ensembles or augmentation-heavy pseudo-labeling pipelines, their effectiveness in high-shift domains like surgery remains unexplored. This work presents SurgTracker, a semi-supervised framework for adapting synthetic-trained point trackers to surgical video using filtered self-distillation. Pseudo-labels are generated online by a fixed teacher-identical in architecture and initialization to the student-and are filtered using a cycle consistency constraint to discard temporally inconsistent trajectories. This simple yet effective design enforces geometric consistency and provides stable supervision throughout training, without the computational overhead of maintaining multiple teachers. Experiments on the STIR benchmark show that SurgTracker improves tracking performance using only 80 unlabeled videos, demonstrating its potential for robust adaptation in high-shift, data-scarce domains.
Evaluating Self-Supervised Learning in Medical Imaging: A Benchmark for Robustness, Generalizability, and Multi-Domain Impact
Dec 26, 2024Self-supervised learning (SSL) has emerged as a promising paradigm in medical imaging, addressing the chronic challenge of limited labeled data in healthcare settings. While SSL has shown impressive results, existing studies in the medical domain are often limited in scope, focusing on specific datasets or modalities, or evaluating only isolated aspects of model performance. This fragmented evaluation approach poses a significant challenge, as models deployed in critical medical settings must not only achieve high accuracy but also demonstrate robust performance and generalizability across diverse datasets and varying conditions. To address this gap, we present a comprehensive evaluation of SSL methods within the medical domain, with a particular focus on robustness and generalizability. Using the MedMNIST dataset collection as a standardized benchmark, we evaluate 8 major SSL methods across 11 different medical datasets. Our study provides an in-depth analysis of model performance in both in-domain scenarios and the detection of out-of-distribution (OOD) samples, while exploring the effect of various initialization strategies, model architectures, and multi-domain pre-training. We further assess the generalizability of SSL methods through cross-dataset evaluations and the in-domain performance with varying label proportions (1%, 10%, and 100%) to simulate real-world scenarios with limited supervision. We hope this comprehensive benchmark helps practitioners and researchers make more informed decisions when applying SSL methods to medical applications.
SIGNeRF: Scene Integrated Generation for Neural Radiance Fields
Jan 03, 2024



Advances in image diffusion models have recently led to notable improvements in the generation of high-quality images. In combination with Neural Radiance Fields (NeRFs), they enabled new opportunities in 3D generation. However, most generative 3D approaches are object-centric and applying them to editing existing photorealistic scenes is not trivial. We propose SIGNeRF, a novel approach for fast and controllable NeRF scene editing and scene-integrated object generation. A new generative update strategy ensures 3D consistency across the edited images, without requiring iterative optimization. We find that depth-conditioned diffusion models inherently possess the capability to generate 3D consistent views by requesting a grid of images instead of single views. Based on these insights, we introduce a multi-view reference sheet of modified images. Our method updates an image collection consistently based on the reference sheet and refines the original NeRF with the newly generated image set in one go. By exploiting the depth conditioning mechanism of the image diffusion model, we gain fine control over the spatial location of the edit and enforce shape guidance by a selected region or an external mesh.
Learning to Adapt Multi-View Stereo by Self-Supervision
Sep 28, 2020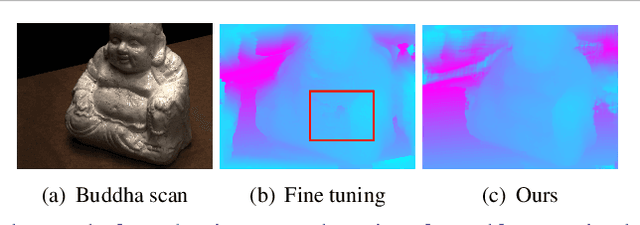
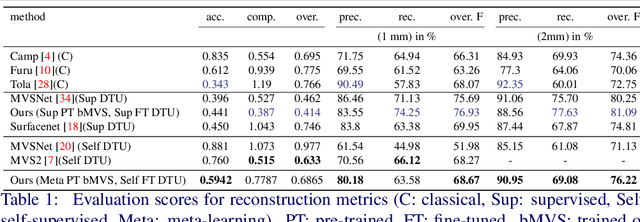

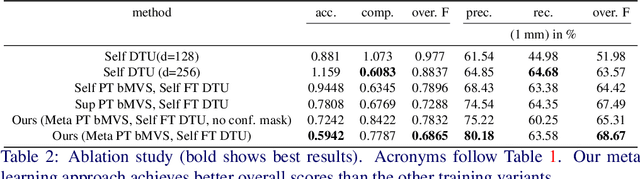
3D scene reconstruction from multiple views is an important classical problem in computer vision. Deep learning based approaches have recently demonstrated impressive reconstruction results. When training such models, self-supervised methods are favourable since they do not rely on ground truth data which would be needed for supervised training and is often difficult to obtain. Moreover, learned multi-view stereo reconstruction is prone to environment changes and should robustly generalise to different domains. We propose an adaptive learning approach for multi-view stereo which trains a deep neural network for improved adaptability to new target domains. We use model-agnostic meta-learning (MAML) to train base parameters which, in turn, are adapted for multi-view stereo on new domains through self-supervised training. Our evaluations demonstrate that the proposed adaptation method is effective in learning self-supervised multi-view stereo reconstruction in new domains.