 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-based Non-Rigid Reconstruction from Contours
Oct 12, 2022



Visual reconstruction of fast non-rigid object deformations over time is a challenge for conventional frame-based cameras. In this paper, we propose a novel approach for reconstructing such deformations using measurements from event-based cameras. Under the assumption of a static background, where all events are generated by the motion, our approach estimates the deformation of objects from events generated at the object contour in a probabilistic optimization framework. It associates events to mesh faces on the contour and maximizes the alignment of the line of sight through the event pixel with the associated face. In experiments on synthetic and real data, we demonstrate the advantages of our method over state-of-the-art optimization and learning-based approaches for reconstructing the motion of human hands. A video of the experiments is available at https://youtu.be/gzfw7i5OKjg
Semi-Supervised Learning of Multi-Object 3D Scene Representations
Oct 08, 2020
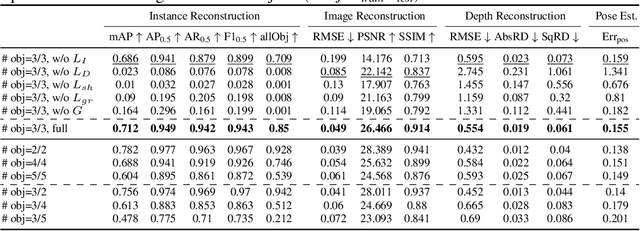
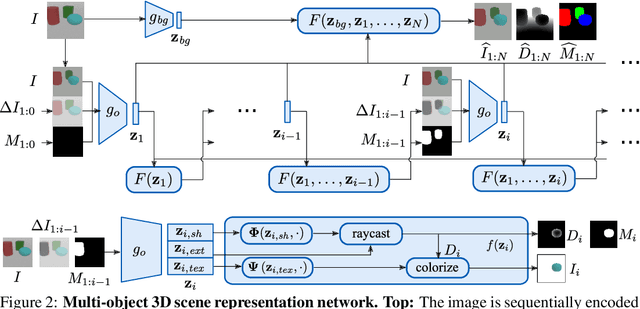
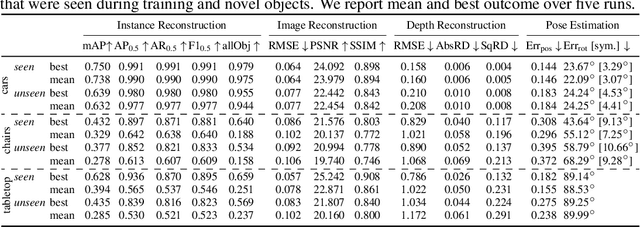
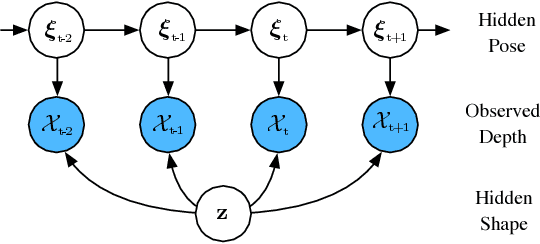
Representing scenes at the granularity of objects is a prerequisite for scene understanding and decision making. We propose a novel approach for learning multi-object 3D scene representations from images. A recurrent encoder regresses a latent representation of 3D shapes, poses and texture of each object from an input RGB image. The 3D shapes are represented continuously in function-space as signed distance functions (SDF) which we efficiently pre-train from example shapes in a supervised way. By differentiable rendering we then train our model to decompose scenes self-supervised from RGB-D images. Our approach learns to decompose images into the constituent objects of the scene and to infer their shape, pose and texture from a single view. We evaluate the accuracy of our model in inferring the 3D scene layout and demonstrate its generative capabilities.
Learning to Adapt Multi-View Stereo by Self-Supervision
Sep 28, 2020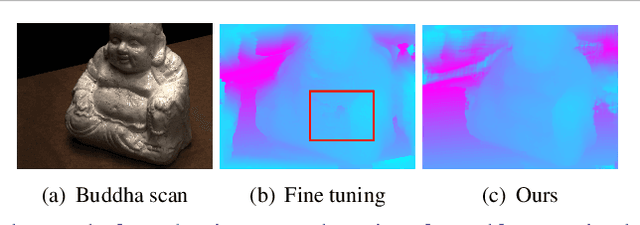
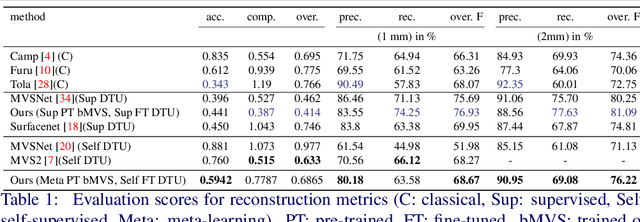

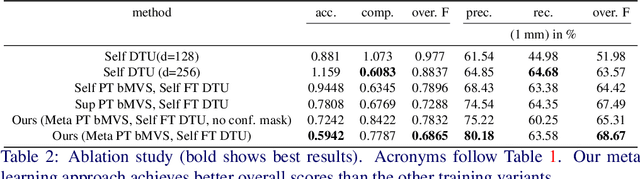
3D scene reconstruction from multiple views is an important classical problem in computer vision. Deep learning based approaches have recently demonstrated impressive reconstruction results. When training such models, self-supervised methods are favourable since they do not rely on ground truth data which would be needed for supervised training and is often difficult to obtain. Moreover, learned multi-view stereo reconstruction is prone to environment changes and should robustly generalise to different domains. We propose an adaptive learning approach for multi-view stereo which trains a deep neural network for improved adaptability to new target domains. We use model-agnostic meta-learning (MAML) to train base parameters which, in turn, are adapted for multi-view stereo on new domains through self-supervised training. Our evaluations demonstrate that the proposed adaptation method is effective in learning self-supervised multi-view stereo reconstruction in new domains.
Learning to Identify Physical Parameters from Video Using Differentiable Physics
Sep 17, 2020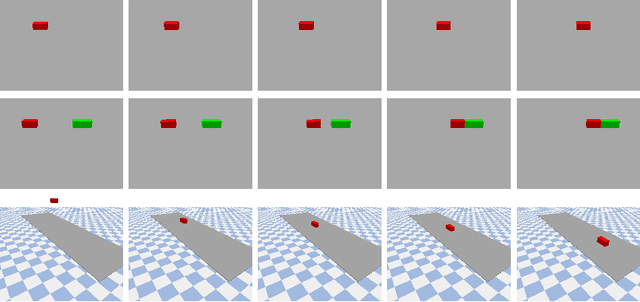
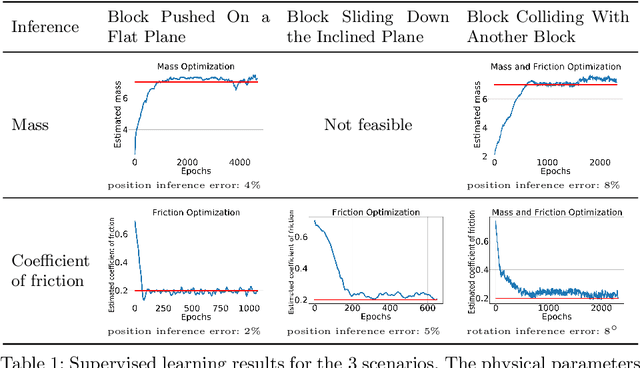
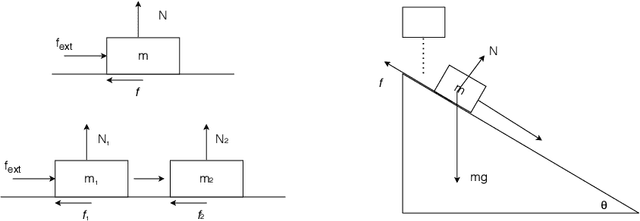
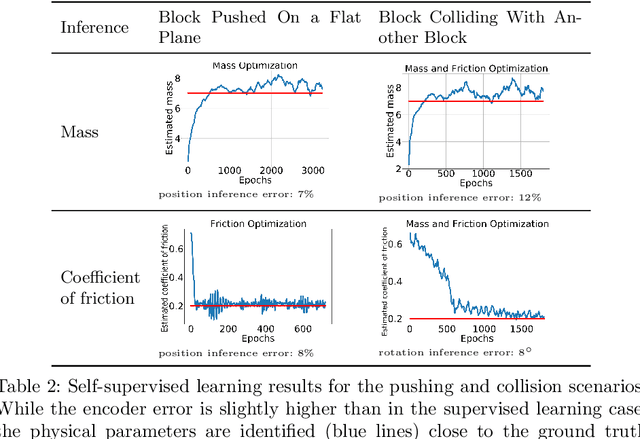
Video representation learning has recently attracted attention in computer vision due to its applications for activity and scene forecasting or vision-based planning and control. Video prediction models often learn a latent representation of video which is encoded from input frames and decoded back into images. Even when conditioned on actions, purely deep learning based architectures typically lack a physically interpretable latent space. In this study, we use a differentiable physics engine within an action-conditional video representation network to learn a physical latent representation. We propose supervised and self-supervised learning methods to train our network and identify physical properties. The latter uses spatial transformers to decode physical states back into images. The simulation scenarios in our experiments comprise pushing, sliding and colliding objects, for which we also analyze the observability of the physical properties. In experiments we demonstrate that our network can learn to encode images and identify physical properties like mass and friction from videos and action sequences in the simulated scenarios. We evaluate the accuracy of our supervised and self-supervised methods and compare it with a system identification baseline which directly learns from state trajectories. We also demonstrate the ability of our method to predict future video frames from input images and actions.
Planning from Images with Deep Latent Gaussian Process Dynamics
May 07, 2020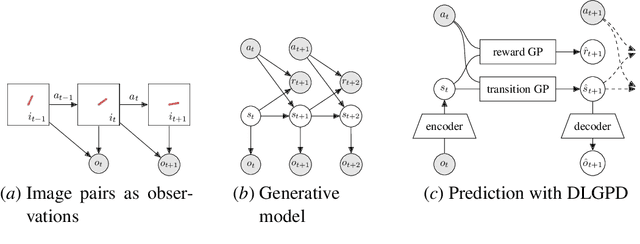
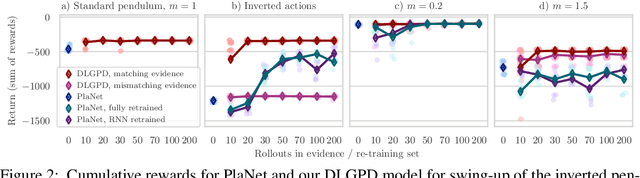
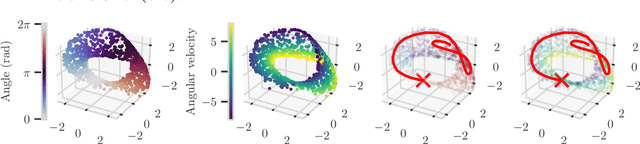
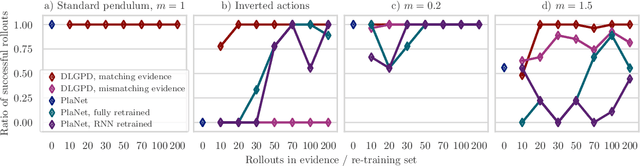
Planning is a powerful approach to control problems with known environment dynamics. In unknown environments the agent needs to learn a model of the system dynamics to make planning applicable. This is particularly challenging when the underlying states are only indirectly observable through images. We propose to learn a deep latent Gaussian process dynamics (DLGPD) model that learns low-dimensional system dynamics from environment interactions with visual observations. The method infers latent state representations from observations using neural networks and models the system dynamics in the learned latent space with Gaussian processes. All parts of the model can be trained jointly by optimizing a lower bound on the likelihood of transitions in image space. We evaluate the proposed approach on the pendulum swing-up task while using the learned dynamics model for planning in latent space in order to solve the control problem. We also demonstrate that our method can quickly adapt a trained agent to changes in the system dynamics from just a few rollouts. We compare our approach to a state-of-the-art purely deep learning based method and demonstrate the advantages of combining Gaussian processes with deep learning for data efficiency and transfer learning.
SAMP: Shape and Motion Priors for 4D Vehicle Reconstruction
May 02, 2020

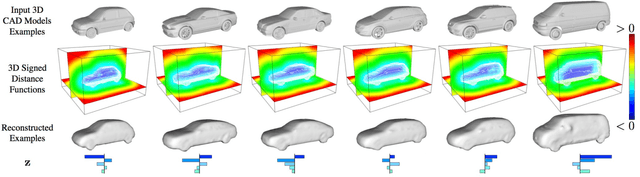
Inferring the pose and shape of vehicles in 3D from a movable platform still remains a challenging task due to the projective sensing principle of cameras, difficult surface properties e.g. reflections or transparency, and illumination changes between images. In this paper, we propose to use 3D shape and motion priors to regularize the estimation of the trajectory and the shape of vehicles in sequences of stereo images. We represent shapes by 3D signed distance functions and embed them in a low-dimensional manifold. Our optimization method allows for imposing a common shape across all image observations along an object track. We employ a motion model to regularize the trajectory to plausible object motions. We evaluate our method on the KITTI dataset and show state-of-the-art results in terms of shape reconstruction and pose estimation accuracy.
Visual-Inertial Mapping with Non-Linear Factor Recovery
Apr 29, 2019


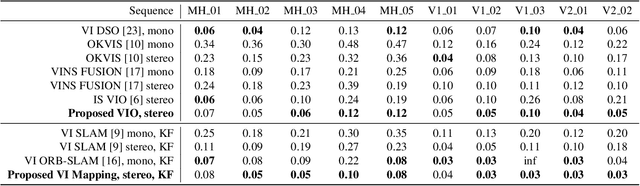
Cameras and inertial measurement units are complementary sensors for ego-motion estimation and environment mapping. Their combination makes visual-inertial odometry (VIO) systems more accurate and robust. For globally consistent mapping, however, combining visual and inertial information is not straightforward. To estimate the motion and geometry with a set of images large baselines are required. Because of that, most systems operate on keyframes that have large time intervals between each other. Inertial data on the other hand quickly degrades with the duration of the intervals and after several seconds of integration, it typically contains only little useful information. In this paper, we propose to extract relevant information for visual-inertial mapping from visual-inertial odometry using non-linear factor recovery. We reconstruct a set of non-linear factors that make an optimal approximation of the information on the trajectory accumulated by VIO. To obtain a globally consistent map we combine these factors with loop-closing constraints using bundle adjustment. The VIO factors make the roll and pitch angles of the global map observable, and improve the robustness and the accuracy of the mapping. In experiments on a public benchmark, we demonstrate superior performance of our method over the state-of-the-art approaches.
EM-Fusion: Dynamic Object-Level SLAM with Probabilistic Data Association
Apr 26, 2019



The majority of approaches for acquiring dense 3D environment maps with RGB-D cameras assumes static environments or rejects moving objects as outliers. The representation and tracking of moving objects, however, has significant potential for applications in robotics or augmented reality. In this paper, we propose a novel approach to dynamic SLAM with dense object-level representations. We represent rigid objects in local volumetric signed distance function (SDF) maps, and formulate multi-object tracking as direct alignment of RGB-D images with the SDF representations. Our main novelty is a probabilistic formulation which naturally leads to strategies for data association and occlusion handling. We analyze our approach in experiments and demonstrate that our approach compares favorably with the state-of-the-art methods in terms of robustness and accuracy.
The TUM VI Benchmark for Evaluating Visual-Inertial Odometry
Sep 20, 2018
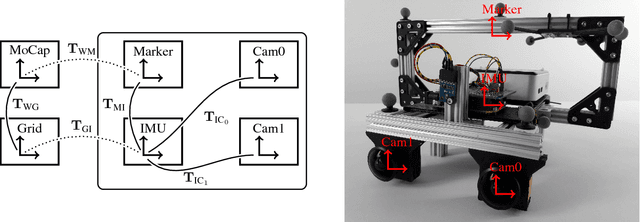
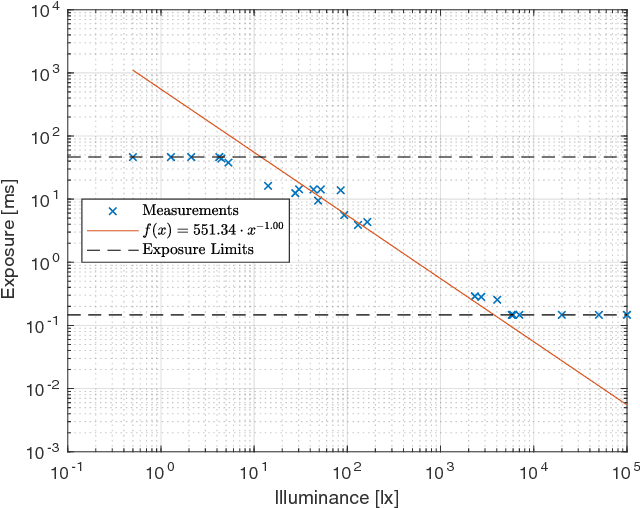
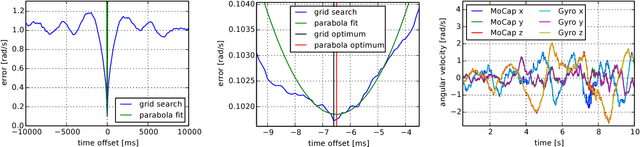
Visual odometry and SLAM methods have a large variety of applications in domains such as augmented reality or robotics. Complementing vision sensors with inertial measurements tremendously improves tracking accuracy and robustness, and thus has spawned large interest in the development of visual-inertial (VI) odometry approaches. In this paper, we propose the TUM VI benchmark, a novel dataset with a diverse set of sequences in different scenes for evaluating VI odometry. It provides camera images with 1024x1024 resolution at 20 Hz, high dynamic range and photometric calibration. An IMU measures accelerations and angular velocities on 3 axes at 200 Hz, while the cameras and IMU sensors are time-synchronized in hardware. For trajectory evaluation, we also provide accurate pose ground truth from a motion capture system at high frequency (120 Hz) at the start and end of the sequences which we accurately aligned with the camera and IMU measurements. The full dataset with raw and calibrated data is publicly available. We also evaluate state-of-the-art VI odometry approaches on our dataset.
Omnidirectional DSO: Direct Sparse Odometry with Fisheye Cameras
Aug 08, 2018


We propose a novel real-time direct monocular visual odometry for omnidirectional cameras. Our method extends direct sparse odometry (DSO) by using the unified omnidirectional model as a projection function, which can be applied to fisheye cameras with a field-of-view (FoV) well above 180 degrees. This formulation allows for using the full area of the input image even with strong distortion, while most existing visual odometry methods can only use a rectified and cropped part of it. Model parameters within an active keyframe window are jointly optimized, including the intrinsic/extrinsic camera parameters, 3D position of points, and affine brightness parameters. Thanks to the wide FoV, image overlap between frames becomes bigger and points are more spatially distributed. Our results demonstrate that our method provides increased accuracy and robustness over state-of-the-art visual odometry algorithms.