 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Identify Physical Parameters from Video Using Differentiable Physics
Paper and Code
Sep 17, 2020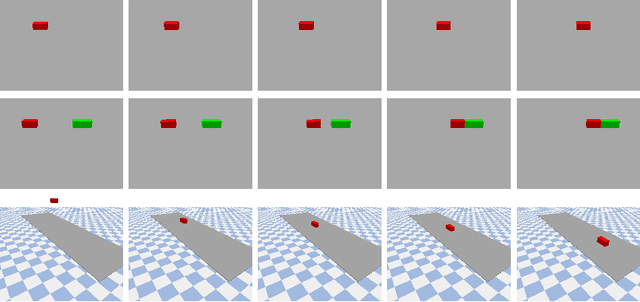
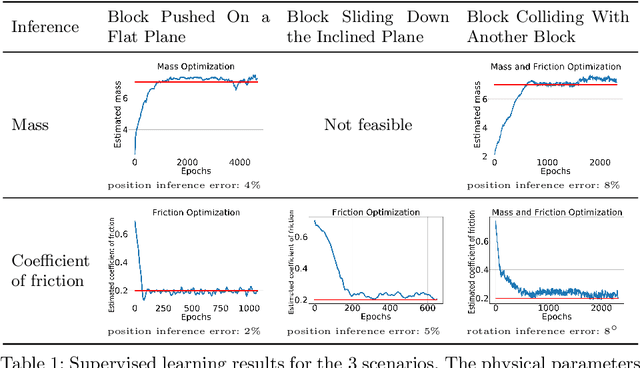
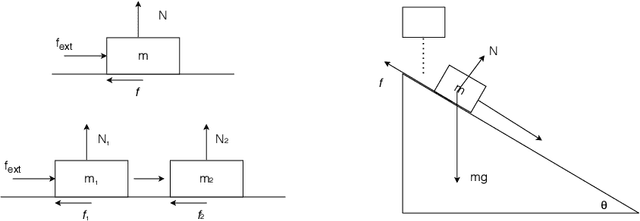
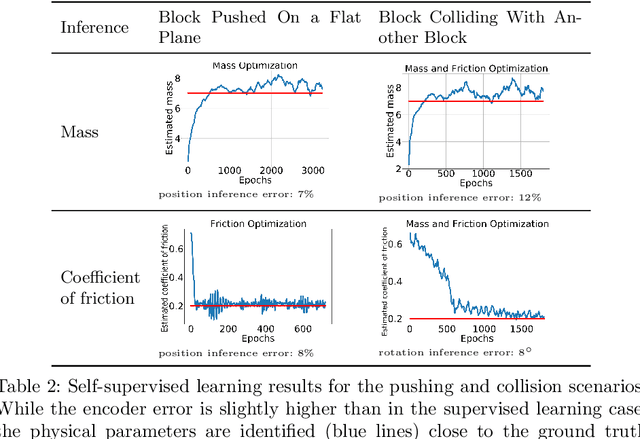
Video representation learning has recently attracted attention in computer vision due to its applications for activity and scene forecasting or vision-based planning and control. Video prediction models often learn a latent representation of video which is encoded from input frames and decoded back into images. Even when conditioned on actions, purely deep learning based architectures typically lack a physically interpretable latent space. In this study, we use a differentiable physics engine within an action-conditional video representation network to learn a physical latent representation. We propose supervised and self-supervised learning methods to train our network and identify physical properties. The latter uses spatial transformers to decode physical states back into images. The simulation scenarios in our experiments comprise pushing, sliding and colliding objects, for which we also analyze the observability of the physical properties. In experiments we demonstrate that our network can learn to encode images and identify physical properties like mass and friction from videos and action sequences in the simulated scenarios. We evaluate the accuracy of our supervised and self-supervised methods and compare it with a system identification baseline which directly learns from state trajectories. We also demonstrate the ability of our method to predict future video frames from input images and actions.