 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Terrain- and Robot-Aware Dynamics Model for Autonomous Mobile Robot Navigation
Sep 17, 2024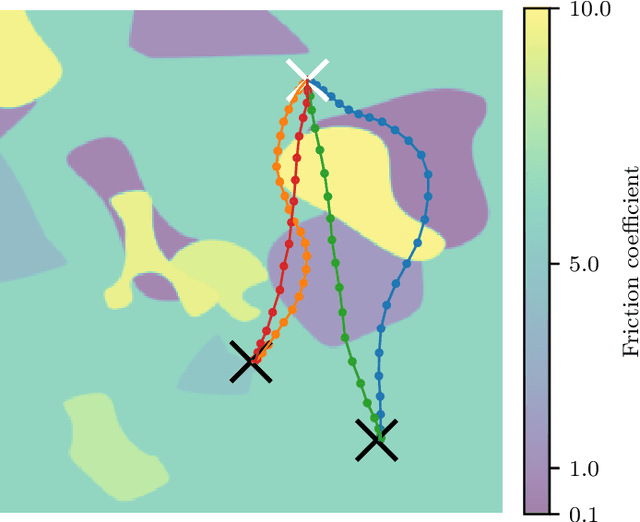

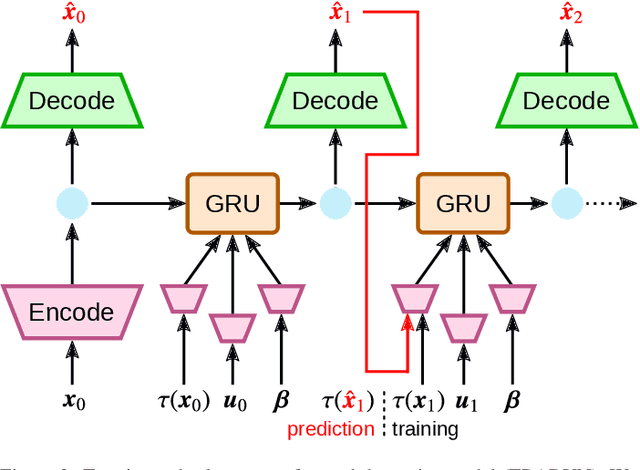
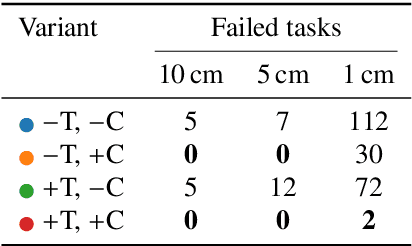
Mobile robots should be capable of planning cost-efficient paths for autonomous navigation. Typically, the terrain and robot properties are subject to variations. For instance, properties of the terrain such as friction may vary across different locations. Also, properties of the robot may change such as payloads or wear and tear, e.g., causing changing actuator gains or joint friction. Autonomous navigation approaches should thus be able to adapt to such variations. In this article, we propose a novel approach for learning a probabilistic, terrain- and robot-aware forward dynamics model (TRADYN) which can adapt to such variations and demonstrate its use for navigation. Our learning approach extends recent advances in meta-learning forward dynamics models based on Neural Processes for mobile robot navigation. We evaluate our method in simulation for 2D navigation of a robot with uni-cycle dynamics with varying properties on terrain with spatially varying friction coefficients. In our experiments, we demonstrate that TRADYN has lower prediction error over long time horizons than model ablations which do not adapt to robot or terrain variations. We also evaluate our model for navigation planning in a model-predictive control framework and under various sources of noise. We demonstrate that our approach yields improved performance in planning control-efficient paths by taking robot and terrain properties into account.
Attention Normalization Impacts Cardinality Generalization in Slot Attention
Jul 04, 2024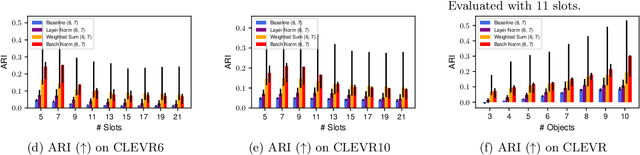
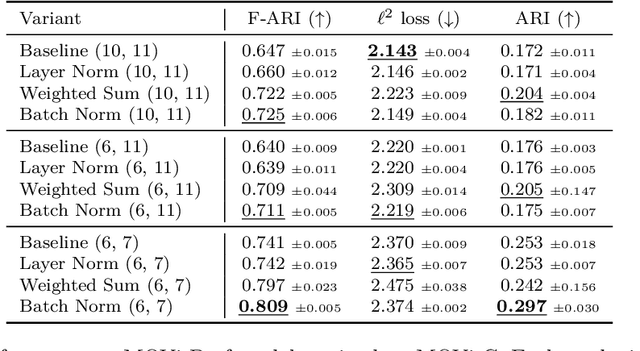
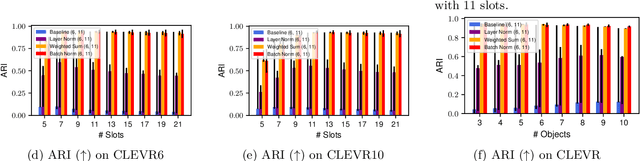
Object-centric scene decompositions are important representations for downstream tasks in fields such as computer vision and robotics. The recently proposed Slot Attention module, already leveraged by several derivative works for image segmentation and object tracking in videos, is a deep learning component which performs unsupervised object-centric scene decomposition on input images. It is based on an attention architecture, in which latent slot vectors, which hold compressed information on objects, attend to localized perceptual features from the input image. In this paper, we show that design decisions on normalizing the aggregated values in the attention architecture have considerable impact on the capabilities of Slot Attention to generalize to a higher number of slots and objects as seen during training. We argue that the original Slot Attention normalization scheme discards information on the prior assignment probability of pixels to slots, which impairs its generalization capabilities. Based on these findings, we propose and investigate alternative normalization approaches which increase the generalization capabilities of Slot Attention to varying slot and object counts, resulting in performance gains on the task of unsupervised image segmentation.
Context-Conditional Navigation with a Learning-Based Terrain- and Robot-Aware Dynamics Model
Jul 20, 2023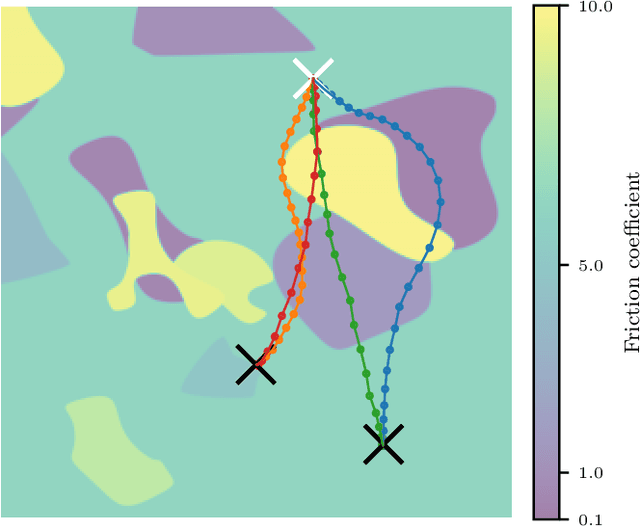
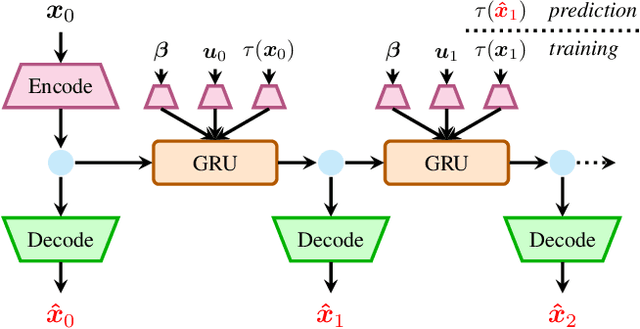
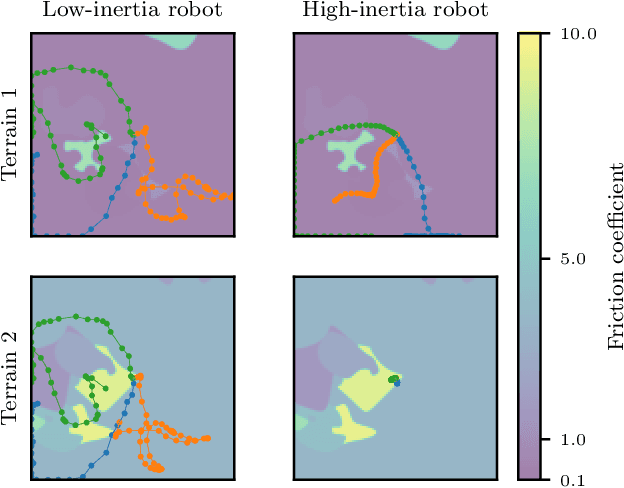
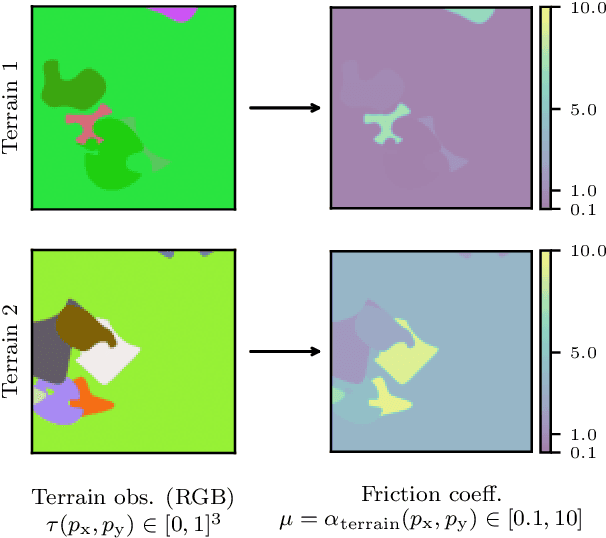
In autonomous navigation settings, several quantities can be subject to variations. Terrain properties such as friction coefficients may vary over time depending on the location of the robot. Also, the dynamics of the robot may change due to, e.g., different payloads, changing the system's mass, or wear and tear, changing actuator gains or joint friction. An autonomous agent should thus be able to adapt to such variations. In this paper, we develop a novel probabilistic, terrain- and robot-aware forward dynamics model, termed TRADYN, which is able to adapt to the above-mentioned variations. It builds on recent advances in meta-learning forward dynamics models based on Neural Processes. We evaluate our method in a simulated 2D navigation setting with a unicycle-like robot and different terrain layouts with spatially varying friction coefficients. In our experiments, the proposed model exhibits lower prediction error for the task of long-horizon trajectory prediction, compared to non-adaptive ablation models. We also evaluate our model on the downstream task of navigation planning, which demonstrates improved performance in planning control-efficient paths by taking robot and terrain properties into account.
Black-Box vs. Gray-Box: A Case Study on Learning Table Tennis Ball Trajectory Prediction with Spin and Impacts
May 24, 2023In this paper, we present a method for table tennis ball trajectory filtering and prediction. Our gray-box approach builds on a physical model. At the same time, we use data to learn parameters of the dynamics model, of an extended Kalman filter, and of a neural model that infers the ball's initial condition. We demonstrate superior prediction performance of our approach over two black-box approaches, which are not supplied with physical prior knowledge. We demonstrate that initializing the spin from parameters of the ball launcher using a neural network drastically improves long-time prediction performance over estimating the spin purely from measured ball positions. An accurate prediction of the ball trajectory is crucial for successful returns. We therefore evaluate the return performance with a pneumatic artificial muscular robot and achieve a return rate of 29/30 (97.7%).
Learning Temporally Extended Skills in Continuous Domains as Symbolic Actions for Planning
Jul 11, 2022
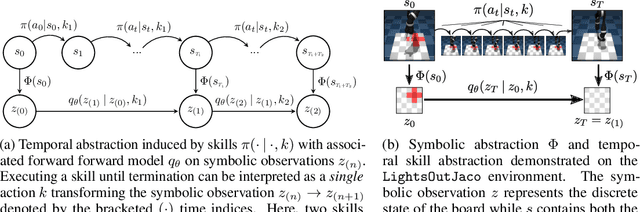
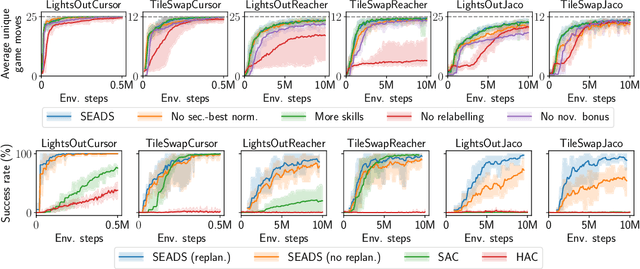
Problems which require both long-horizon planning and continuous control capabilities pose significant challenges to existing reinforcement learning agents. In this paper we introduce a novel hierarchical reinforcement learning agent which links temporally extended skills for continuous control with a forward model in a symbolic discrete abstraction of the environment's state for planning. We term our agent SEADS for Symbolic Effect-Aware Diverse Skills. We formulate an objective and corresponding algorithm which leads to unsupervised learning of a diverse set of skills through intrinsic motivation given a known state abstraction. The skills are jointly learned with the symbolic forward model which captures the effect of skill execution in the state abstraction. After training, we can leverage the skills as symbolic actions using the forward model for long-horizon planning and subsequently execute the plan using the learned continuous-action control skills. The proposed algorithm learns skills and forward models that can be used to solve complex tasks which require both continuous control and long-horizon planning capabilities with high success rate. It compares favorably with other flat and hierarchical reinforcement learning baseline agents and is successfully demonstrated with a real robot.
Explore the Context: Optimal Data Collection for Context-Conditional Dynamics Models
Feb 22, 2021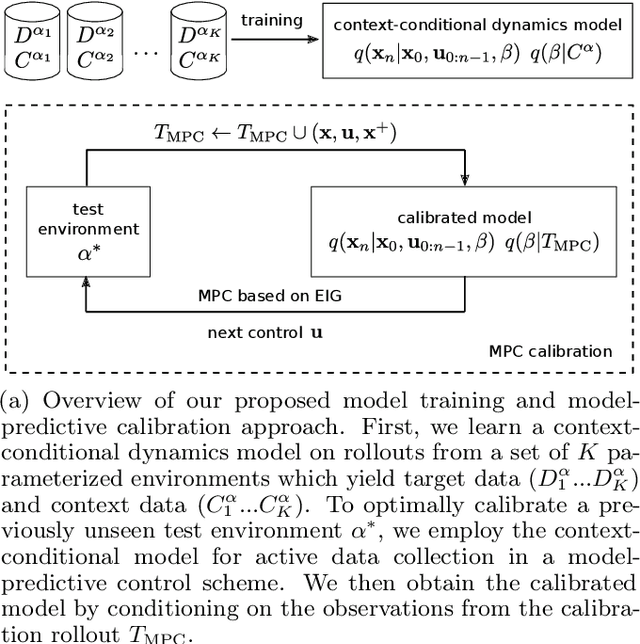
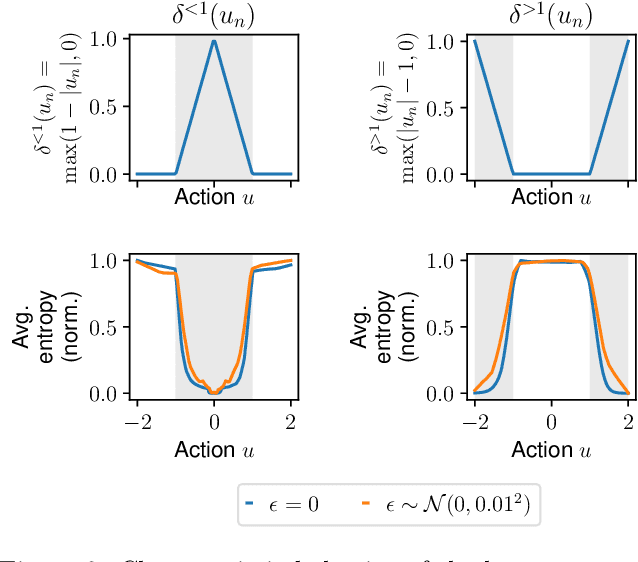
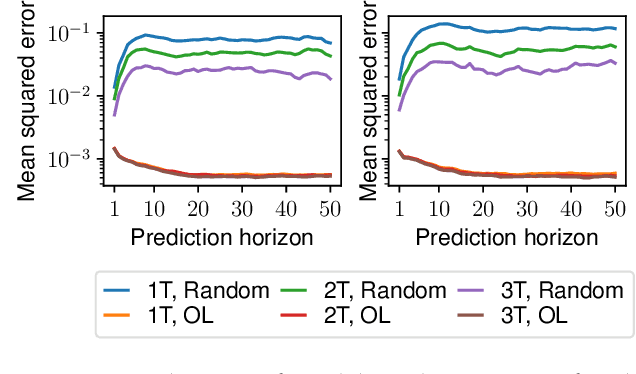
In this paper, we learn dynamics models for parametrized families of dynamical systems with varying properties. The dynamics models are formulated as stochastic processes conditioned on a latent context variable which is inferred from observed transitions of the respective system. The probabilistic formulation allows us to compute an action sequence which, for a limited number of environment interactions, optimally explores the given system within the parametrized family. This is achieved by steering the system through transitions being most informative for the context variable. We demonstrate the effectiveness of our method for exploration on a non-linear toy-problem and two well-known reinforcement learning environments.
Learning to Identify Physical Parameters from Video Using Differentiable Physics
Sep 17, 2020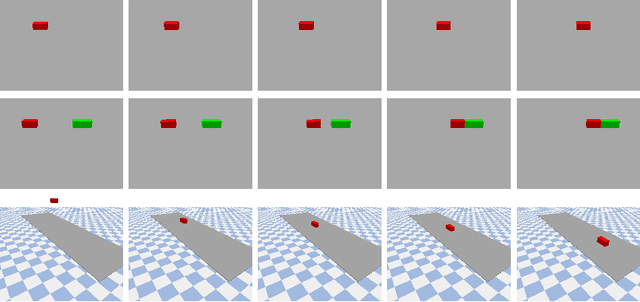
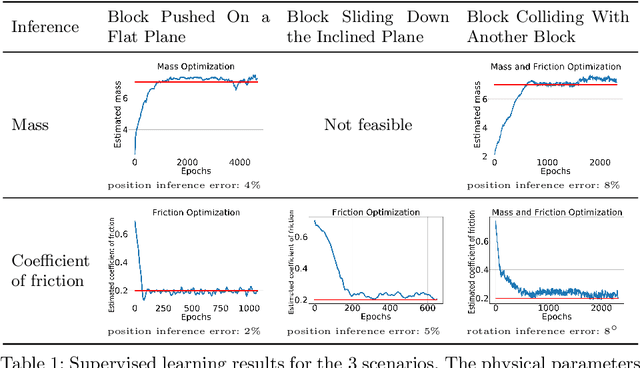
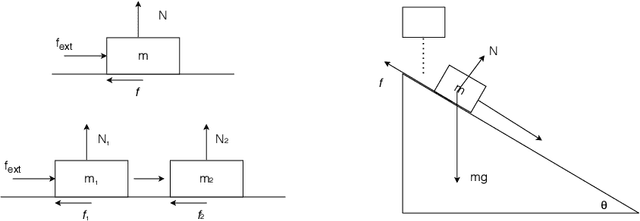
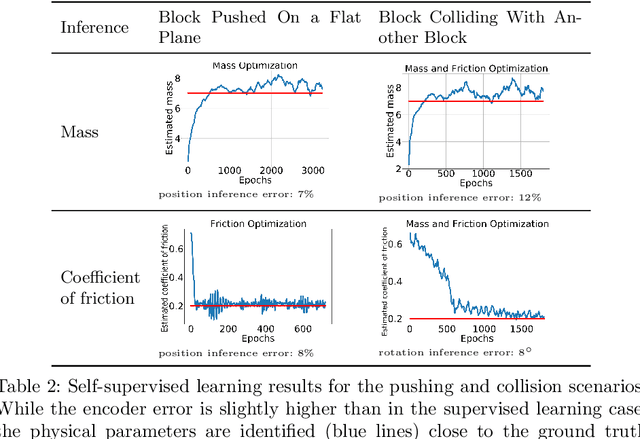
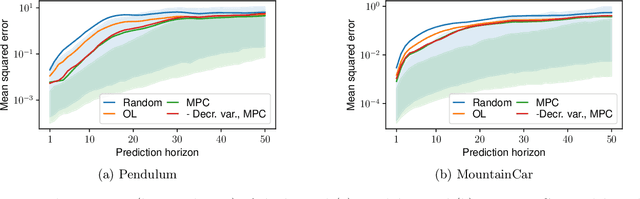
Video representation learning has recently attracted attention in computer vision due to its applications for activity and scene forecasting or vision-based planning and control. Video prediction models often learn a latent representation of video which is encoded from input frames and decoded back into images. Even when conditioned on actions, purely deep learning based architectures typically lack a physically interpretable latent space. In this study, we use a differentiable physics engine within an action-conditional video representation network to learn a physical latent representation. We propose supervised and self-supervised learning methods to train our network and identify physical properties. The latter uses spatial transformers to decode physical states back into images. The simulation scenarios in our experiments comprise pushing, sliding and colliding objects, for which we also analyze the observability of the physical properties. In experiments we demonstrate that our network can learn to encode images and identify physical properties like mass and friction from videos and action sequences in the simulated scenarios. We evaluate the accuracy of our supervised and self-supervised methods and compare it with a system identification baseline which directly learns from state trajectories. We also demonstrate the ability of our method to predict future video frames from input images and actions.
Sample-efficient Cross-Entropy Method for Real-time Planning
Aug 14, 2020
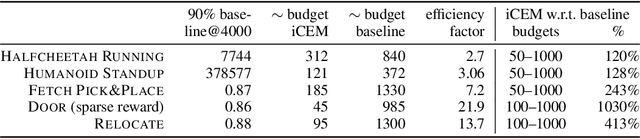
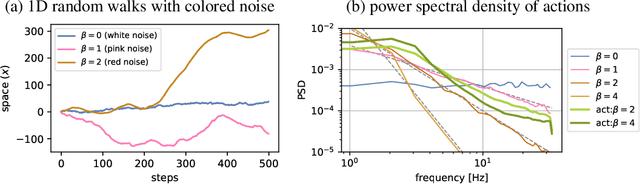
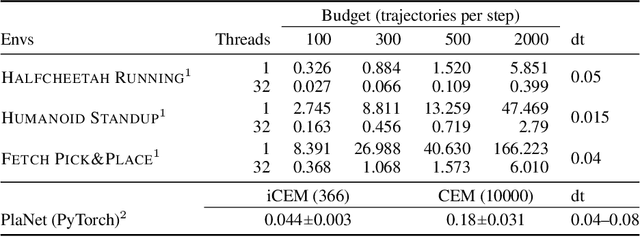
Trajectory optimizers for model-based reinforcement learning, such as the Cross-Entropy Method (CEM), can yield compelling results even in high-dimensional control tasks and sparse-reward environments. However, their sampling inefficiency prevents them from being used for real-time planning and control. We propose an improved version of the CEM algorithm for fast planning, with novel additions including temporally-correlated actions and memory, requiring 2.7-22x less samples and yielding a performance increase of 1.2-10x in high-dimensional control problems.
Planning from Images with Deep Latent Gaussian Process Dynamics
May 07, 2020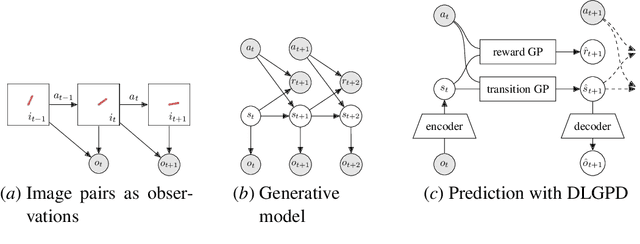
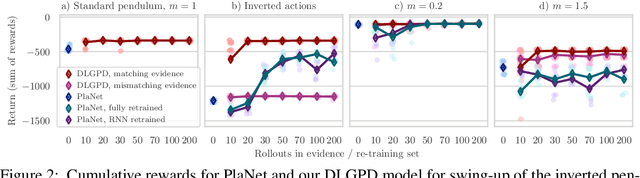
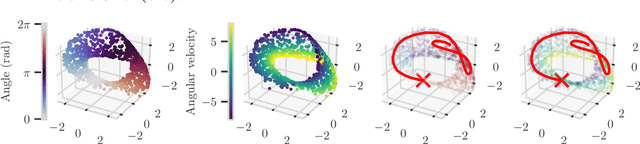
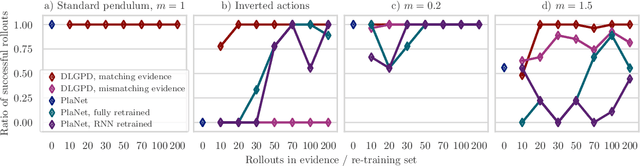
Planning is a powerful approach to control problems with known environment dynamics. In unknown environments the agent needs to learn a model of the system dynamics to make planning applicable. This is particularly challenging when the underlying states are only indirectly observable through images. We propose to learn a deep latent Gaussian process dynamics (DLGPD) model that learns low-dimensional system dynamics from environment interactions with visual observations. The method infers latent state representations from observations using neural networks and models the system dynamics in the learned latent space with Gaussian processes. All parts of the model can be trained jointly by optimizing a lower bound on the likelihood of transitions in image space. We evaluate the proposed approach on the pendulum swing-up task while using the learned dynamics model for planning in latent space in order to solve the control problem. We also demonstrate that our method can quickly adapt a trained agent to changes in the system dynamics from just a few rollouts. We compare our approach to a state-of-the-art purely deep learning based method and demonstrate the advantages of combining Gaussian processes with deep learning for data efficiency and transfer learning.