 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Safe LLM Systems via Soft Prompts for On Device Settings
Jun 08, 2026Deploying safe large language models (LLMs) on resource-constrained edge devices presents a critical challenge: while dual-model systems combining LLMs with guard models provide effective safety guarantees, their substantial memory and computational demands make them prohibitively expensive for on-device deployment. This paper presents a comprehensive study of parameter-efficient safety alignment methods for resource-constrained settings. Through systematic evaluation across multiple LLM architectures, training objectives, and parameter-efficient fine-tuning approaches, we identify that soft prompts combined with distillation-based training consistently outperform alternative methods. We introduce distillation frameworks based on total variation and KL divergence that effectively transfer safety behaviors from guard models into learned soft prompts. Our evaluations on various benchmarks demonstrate that this combination achieves superior safety-usefulness trade-offs compared to LoRA adapters, steering vectors, and direct optimization methods, while requiring minimal additional memory and compute at inference time. These findings establish soft prompt distillation as the preferred approach for safety alignment in on-device LLM deployment.
* Accepted to UAI 2026
Guarding the Meaning: Self-Supervised Training for Semantic Robustness in Guard Models
Nov 06, 2025
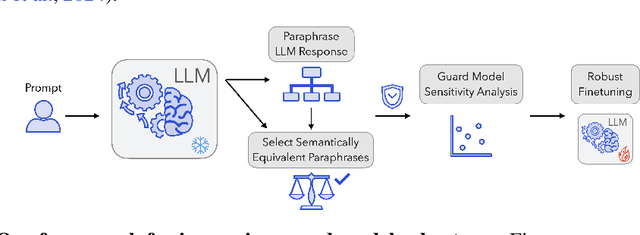
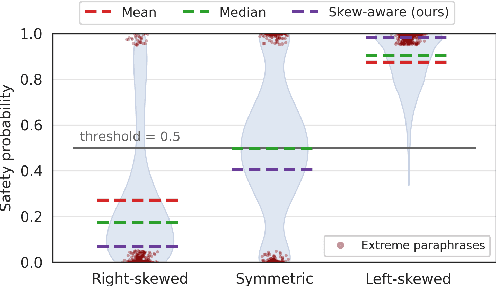
Guard models are a critical component of LLM safety, but their sensitivity to superficial linguistic variations remains a key vulnerability. We show that even meaning-preserving paraphrases can cause large fluctuations in safety scores, revealing a lack of semantic grounding. To address this, we introduce a practical, self-supervised framework for improving the semantic robustness of guard models. Our method leverages paraphrase sets to enforce prediction consistency using a novel, skew-aware aggregation strategy for robust target computation. Notably, we find that standard aggregation methods like mean and median can degrade safety, underscoring the need for skew-aware alternatives. We analyze six open-source guard models and show that our approach reduces semantic variability across paraphrases by ~58%, improves benchmark accuracy by ~2.5% on average, and generalizes to unseen stylistic variations. Intriguingly, we discover a bidirectional relationship between model calibration and consistency: our robustness training improves calibration by up to 40%, revealing a fundamental connection between these properties. These results highlight the value of treating semantic consistency as a first-class training objective and provide a scalable recipe for building more reliable guard models.
Equivariant Data Augmentation for Generalization in Offline Reinforcement Learning
Sep 14, 2023We present a novel approach to address the challenge of generalization in offline reinforcement learning (RL), where the agent learns from a fixed dataset without any additional interaction with the environment. Specifically, we aim to improve the agent's ability to generalize to out-of-distribution goals. To achieve this, we propose to learn a dynamics model and check if it is equivariant with respect to a fixed type of transformation, namely translations in the state space. We then use an entropy regularizer to increase the equivariant set and augment the dataset with the resulting transformed samples. Finally, we learn a new policy offline based on the augmented dataset, with an off-the-shelf offline RL algorithm. Our experimental results demonstrate that our approach can greatly improve the test performance of the policy on the considered environments.
Sample-efficient Cross-Entropy Method for Real-time Planning
Aug 14, 2020
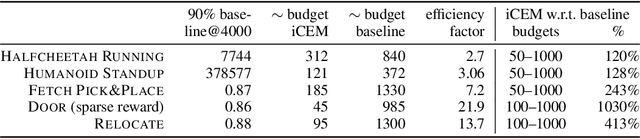
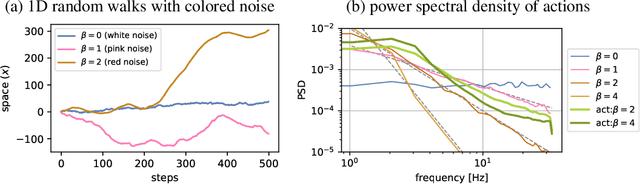
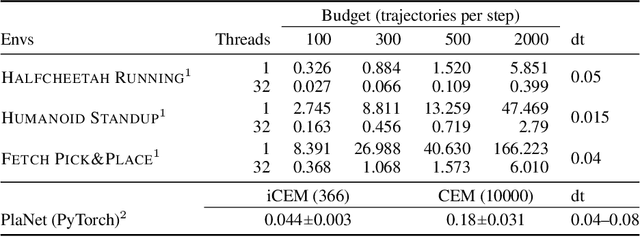
Trajectory optimizers for model-based reinforcement learning, such as the Cross-Entropy Method (CEM), can yield compelling results even in high-dimensional control tasks and sparse-reward environments. However, their sampling inefficiency prevents them from being used for real-time planning and control. We propose an improved version of the CEM algorithm for fast planning, with novel additions including temporally-correlated actions and memory, requiring 2.7-22x less samples and yielding a performance increase of 1.2-10x in high-dimensional control problems.