Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-efficient Cross-Entropy Method for Real-time Planning
Paper and Code

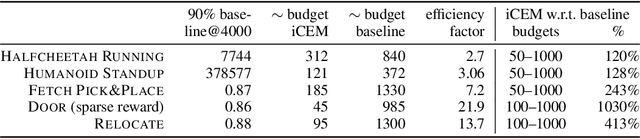
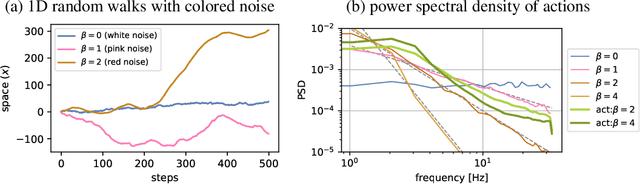
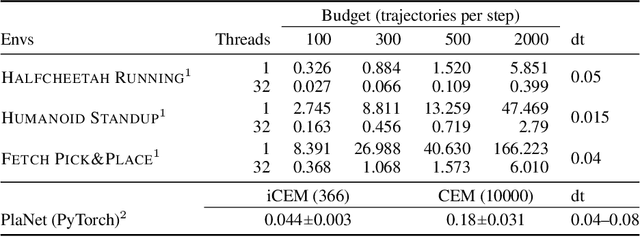
Trajectory optimizers for model-based reinforcement learning, such as the Cross-Entropy Method (CEM), can yield compelling results even in high-dimensional control tasks and sparse-reward environments. However, their sampling inefficiency prevents them from being used for real-time planning and control. We propose an improved version of the CEM algorithm for fast planning, with novel additions including temporally-correlated actions and memory, requiring 2.7-22x less samples and yielding a performance increase of 1.2-10x in high-dimensional control problems.
View paper on