 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenie: Generative Interactive Environments
Feb 23, 2024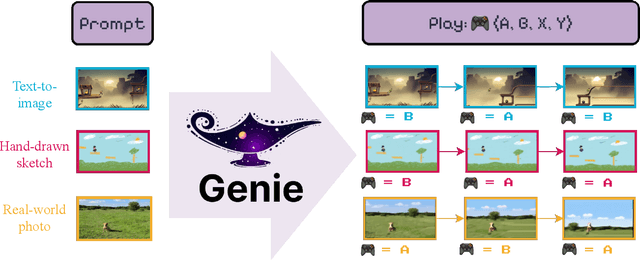
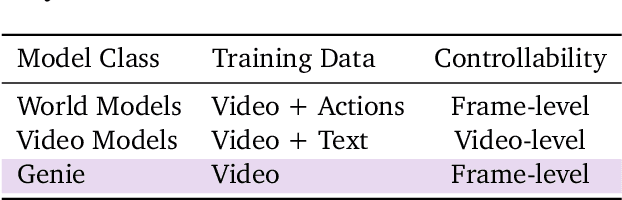
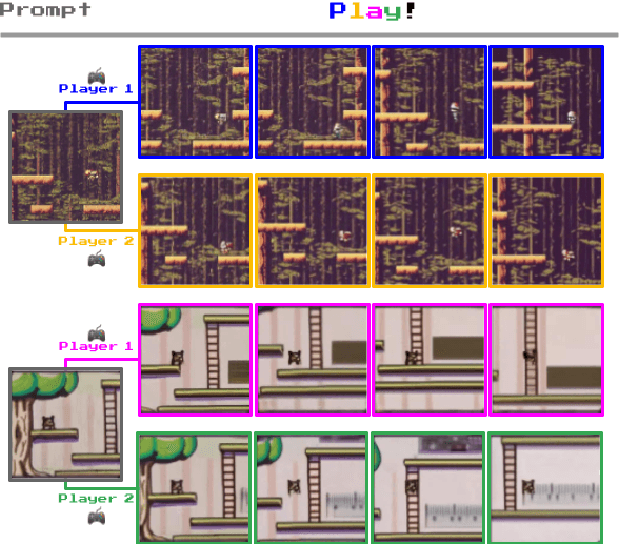
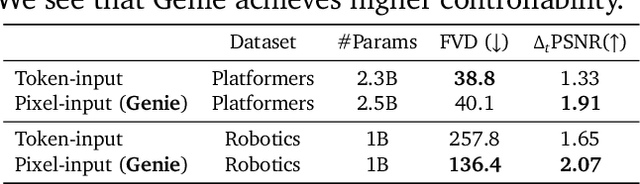
We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
Offline Actor-Critic Reinforcement Learning Scales to Large Models
Feb 08, 2024



We show that offline actor-critic reinforcement learning can scale to large models - such as transformers - and follows similar scaling laws as supervised learning. We find that offline actor-critic algorithms can outperform strong, supervised, behavioral cloning baselines for multi-task training on a large dataset containing both sub-optimal and expert behavior on 132 continuous control tasks. We introduce a Perceiver-based actor-critic model and elucidate the key model features needed to make offline RL work with self- and cross-attention modules. Overall, we find that: i) simple offline actor critic algorithms are a natural choice for gradually moving away from the currently predominant paradigm of behavioral cloning, and ii) via offline RL it is possible to learn multi-task policies that master many domains simultaneously, including real robotics tasks, from sub-optimal demonstrations or self-generated data.
Mastering Stacking of Diverse Shapes with Large-Scale Iterative Reinforcement Learning on Real Robots
Dec 18, 2023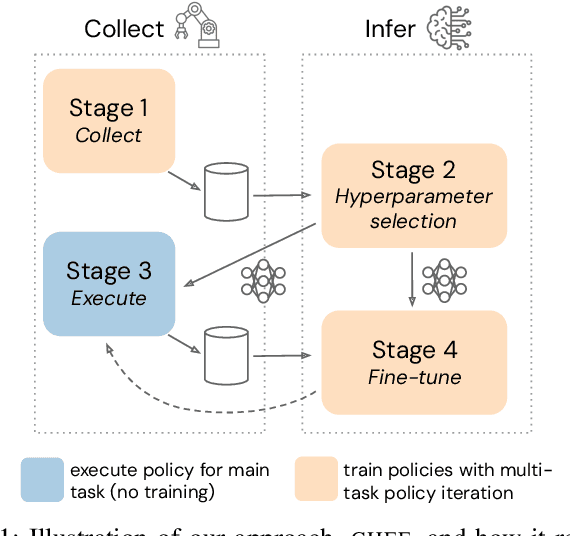


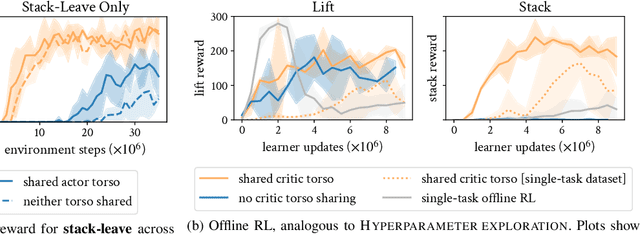
Reinforcement learning solely from an agent's self-generated data is often believed to be infeasible for learning on real robots, due to the amount of data needed. However, if done right, agents learning from real data can be surprisingly efficient through re-using previously collected sub-optimal data. In this paper we demonstrate how the increased understanding of off-policy learning methods and their embedding in an iterative online/offline scheme (``collect and infer'') can drastically improve data-efficiency by using all the collected experience, which empowers learning from real robot experience only. Moreover, the resulting policy improves significantly over the state of the art on a recently proposed real robot manipulation benchmark. Our approach learns end-to-end, directly from pixels, and does not rely on additional human domain knowledge such as a simulator or demonstrations.
Foundations for Transfer in Reinforcement Learning: A Taxonomy of Knowledge Modalities
Dec 04, 2023Contemporary artificial intelligence systems exhibit rapidly growing abilities accompanied by the growth of required resources, expansive datasets and corresponding investments into computing infrastructure. Although earlier successes predominantly focus on constrained settings, recent strides in fundamental research and applications aspire to create increasingly general systems. This evolving landscape presents a dual panorama of opportunities and challenges in refining the generalisation and transfer of knowledge - the extraction from existing sources and adaptation as a comprehensive foundation for tackling new problems. Within the domain of reinforcement learning (RL), the representation of knowledge manifests through various modalities, including dynamics and reward models, value functions, policies, and the original data. This taxonomy systematically targets these modalities and frames its discussion based on their inherent properties and alignment with different objectives and mechanisms for transfer. Where possible, we aim to provide coarse guidance delineating approaches which address requirements such as limiting environment interactions, maximising computational efficiency, and enhancing generalisation across varying axes of change. Finally, we analyse reasons contributing to the prevalence or scarcity of specific forms of transfer, the inherent potential behind pushing these frontiers, and underscore the significance of transitioning from designed to learned transfer.
Equivariant Data Augmentation for Generalization in Offline Reinforcement Learning
Sep 14, 2023We present a novel approach to address the challenge of generalization in offline reinforcement learning (RL), where the agent learns from a fixed dataset without any additional interaction with the environment. Specifically, we aim to improve the agent's ability to generalize to out-of-distribution goals. To achieve this, we propose to learn a dynamics model and check if it is equivariant with respect to a fixed type of transformation, namely translations in the state space. We then use an entropy regularizer to increase the equivariant set and augment the dataset with the resulting transformed samples. Finally, we learn a new policy offline based on the augmented dataset, with an off-the-shelf offline RL algorithm. Our experimental results demonstrate that our approach can greatly improve the test performance of the policy on the considered environments.
A Generalist Dynamics Model for Control
May 18, 2023



We investigate the use of transformer sequence models as dynamics models (TDMs) for control. In a number of experiments in the DeepMind control suite, we find that first, TDMs perform well in a single-environment learning setting when compared to baseline models. Second, TDMs exhibit strong generalization capabilities to unseen environments, both in a few-shot setting, where a generalist model is fine-tuned with small amounts of data from the target environment, and in a zero-shot setting, where a generalist model is applied to an unseen environment without any further training. We further demonstrate that generalizing system dynamics can work much better than generalizing optimal behavior directly as a policy. This makes TDMs a promising ingredient for a foundation model of control.
Model Based Meta Learning of Critics for Policy Gradients
Apr 05, 2022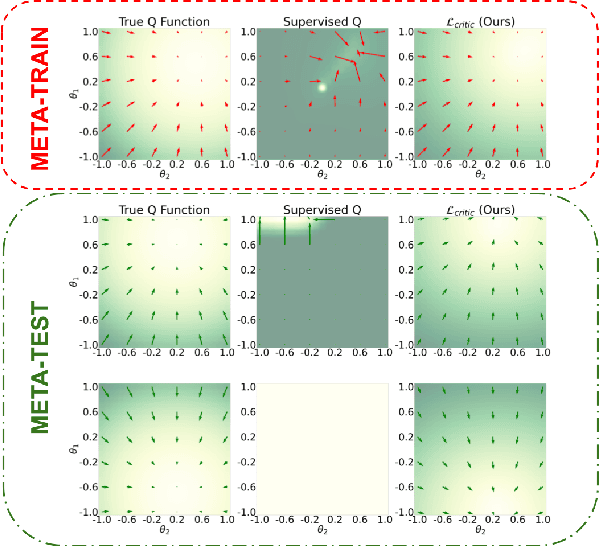
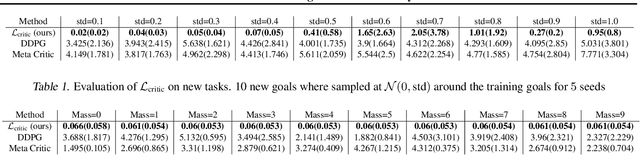
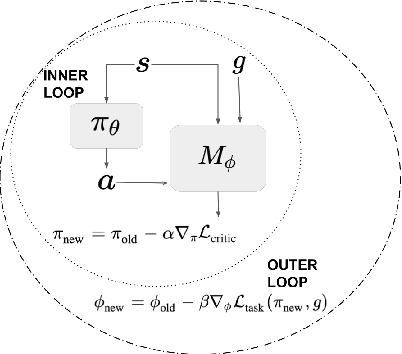
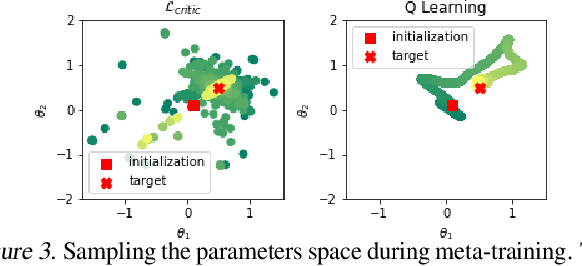
Being able to seamlessly generalize across different tasks is fundamental for robots to act in our world. However, learning representations that generalize quickly to new scenarios is still an open research problem in reinforcement learning. In this paper we present a framework to meta-learn the critic for gradient-based policy learning. Concretely, we propose a model-based bi-level optimization algorithm that updates the critics parameters such that the policy that is learned with the updated critic gets closer to solving the meta-training tasks. We illustrate that our algorithm leads to learned critics that resemble the ground truth Q function for a given task. Finally, after meta-training, the learned critic can be used to learn new policies for new unseen task and environment settings via model-free policy gradient optimization, without requiring a model. We present results that show the generalization capabilities of our learned critic to new tasks and dynamics when used to learn a new policy in a new scenario.
Learning Time-Invariant Reward Functions through Model-Based Inverse Reinforcement Learning
Jul 07, 2021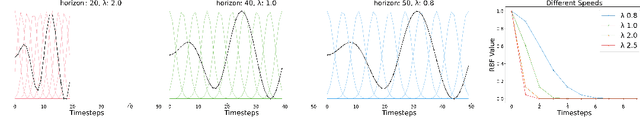
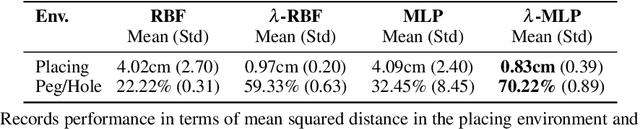

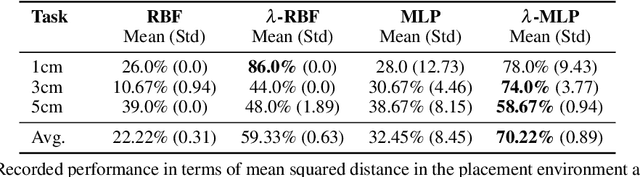
Inverse reinforcement learning is a paradigm motivated by the goal of learning general reward functions from demonstrated behaviours. Yet the notion of generality for learnt costs is often evaluated in terms of robustness to various spatial perturbations only, assuming deployment at fixed speeds of execution. However, this is impractical in the context of robotics and building time-invariant solutions is of crucial importance. In this work, we propose a formulation that allows us to 1) vary the length of execution by learning time-invariant costs, and 2) relax the temporal alignment requirements for learning from demonstration. We apply our method to two different types of cost formulations and evaluate their performance in the context of learning reward functions for simulated placement and peg in hole tasks. Our results show that our approach enables learning temporally invariant rewards from misaligned demonstration that can also generalise spatially to out of distribution tasks.
Learning Extended Body Schemas from Visual Keypoints for Object Manipulation
Nov 08, 2020
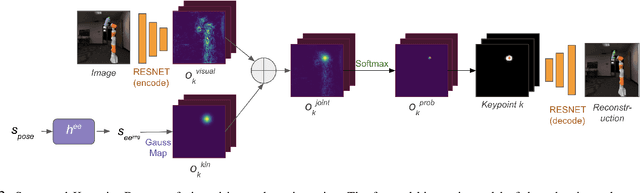
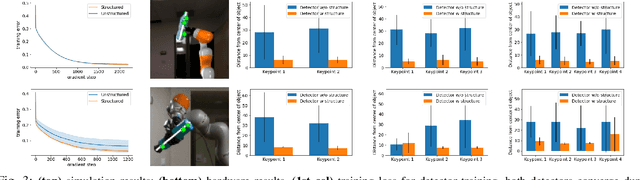

Humans have impressive generalization capabilities when it comes to manipulating objects and tools in completely novel environments. These capabilities are, at least partially, a result of humans having internal models of their bodies and any grasped object. How to learn such body schemas for robots remains an open problem. In this work, we develop an approach that can extend a robot's kinematic model when grasping an object from visual latent representations. Our framework comprises two components: 1) a structured keypoint detector, which fuses proprioception and vision to predict visual key points on an object; 2) Learning an adaptation of the kinematic chain by regressing virtual joints from the predicted key points. Our evaluation shows that our approach learns to consistently predict visual keypoints on objects, and can easily adapt a kinematic chain to the object grasped in various configurations, from a few seconds of data. Finally we show that this extended kinematic chain lends itself for object manipulation tasks such as placing a grasped object.
Leveraging Forward Model Prediction Error for Learning Control
Nov 07, 2020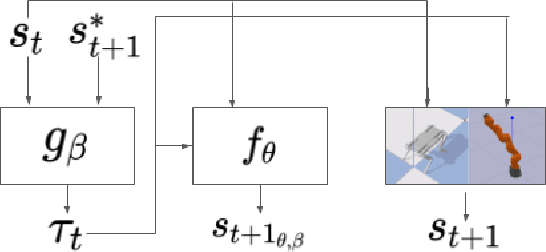
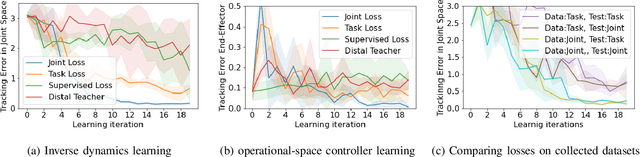
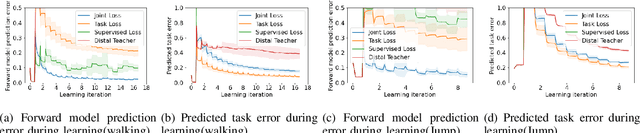

Learning for model based control can be sample-efficient and generalize well, however successfully learning models and controllers that represent the problem at hand can be challenging for complex tasks. Using inaccurate models for learning can lead to sub-optimal solutions, that are unlikely to perform well in practice. In this work, we present a learning approach which iterates between model learning and data collection and leverages forward model prediction error for learning control. We show how using the controller's prediction as input to a forward model can create a differentiable connection between the controller and the model, allowing us to formulate a loss in the state space. This lets us include forward model prediction error during controller learning and we show that this creates a loss objective that significantly improves learning on different motor control tasks. We provide empirical and theoretical results that show the benefits of our method and present evaluations in simulation for learning control on a 7 DoF manipulator and an underactuated 12 DoF quadruped. We show that our approach successfully learns controllers for challenging motor control tasks involving contact switching.