 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Reasoning via Deep Vision Models for Robotic Sequential Manipulation
Jul 06, 2023In this paper, we propose using deep neural architectures (i.e., vision transformers and ResNet) as heuristics for sequential decision-making in robotic manipulation problems. This formulation enables predicting the subset of objects that are relevant for completing a task. Such problems are often addressed by task and motion planning (TAMP) formulations combining symbolic reasoning and continuous motion planning. In essence, the action-object relationships are resolved for discrete, symbolic decisions that are used to solve manipulation motions (e.g., via nonlinear trajectory optimization). However, solving long-horizon tasks requires consideration of all possible action-object combinations which limits the scalability of TAMP approaches. To overcome this combinatorial complexity, we introduce a visual perception module integrated with a TAMP-solver. Given a task and an initial image of the scene, the learned model outputs the relevancy of objects to accomplish the task. By incorporating the predictions of the model into a TAMP formulation as a heuristic, the size of the search space is significantly reduced. Results show that our framework finds feasible solutions more efficiently when compared to a state-of-the-art TAMP solver.
A Generalist Dynamics Model for Control
May 18, 2023



We investigate the use of transformer sequence models as dynamics models (TDMs) for control. In a number of experiments in the DeepMind control suite, we find that first, TDMs perform well in a single-environment learning setting when compared to baseline models. Second, TDMs exhibit strong generalization capabilities to unseen environments, both in a few-shot setting, where a generalist model is fine-tuned with small amounts of data from the target environment, and in a zero-shot setting, where a generalist model is applied to an unseen environment without any further training. We further demonstrate that generalizing system dynamics can work much better than generalizing optimal behavior directly as a policy. This makes TDMs a promising ingredient for a foundation model of control.
Reinforcement Learning with Neural Radiance Fields
Jun 03, 2022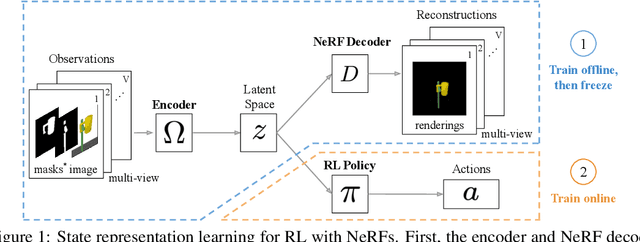

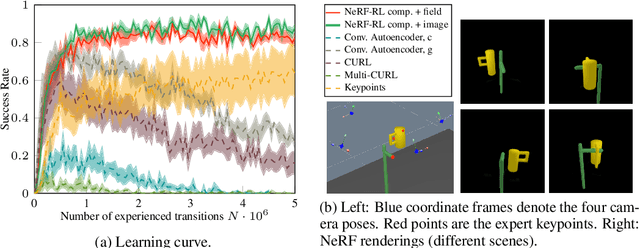
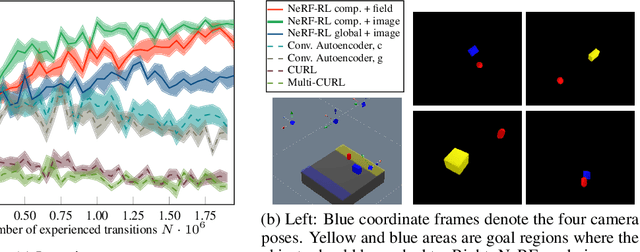
It is a long-standing problem to find effective representations for training reinforcement learning (RL) agents. This paper demonstrates that learning state representations with supervision from Neural Radiance Fields (NeRFs) can improve the performance of RL compared to other learned representations or even low-dimensional, hand-engineered state information. Specifically, we propose to train an encoder that maps multiple image observations to a latent space describing the objects in the scene. The decoder built from a latent-conditioned NeRF serves as the supervision signal to learn the latent space. An RL algorithm then operates on the learned latent space as its state representation. We call this NeRF-RL. Our experiments indicate that NeRF as supervision leads to a latent space better suited for the downstream RL tasks involving robotic object manipulations like hanging mugs on hooks, pushing objects, or opening doors. Video: https://dannydriess.github.io/nerf-rl
Learning to Execute: Efficient Learning of Universal Plan-Conditioned Policies in Robotics
Nov 15, 2021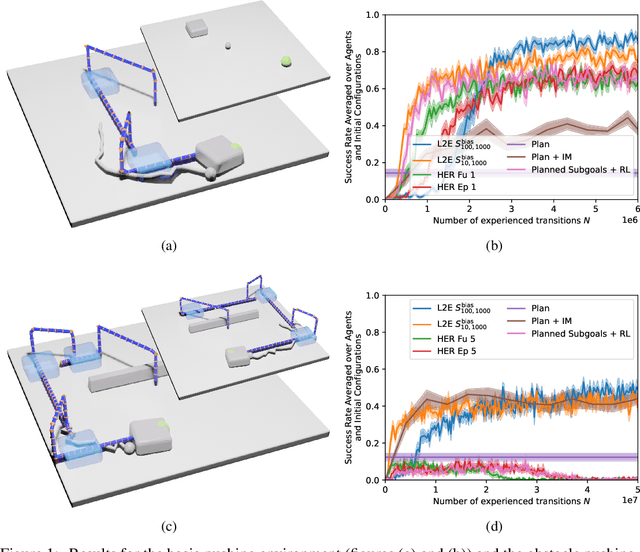
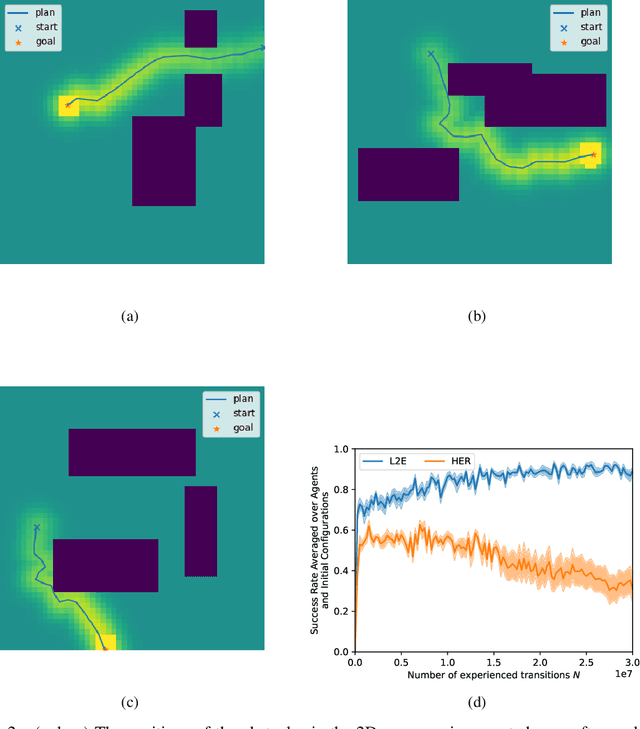
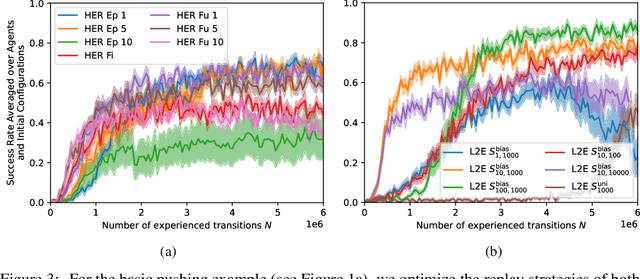
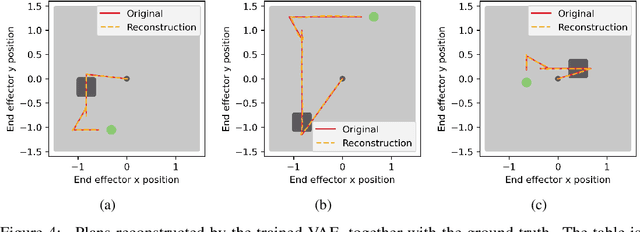
Applications of Reinforcement Learning (RL) in robotics are often limited by high data demand. On the other hand, approximate models are readily available in many robotics scenarios, making model-based approaches like planning a data-efficient alternative. Still, the performance of these methods suffers if the model is imprecise or wrong. In this sense, the respective strengths and weaknesses of RL and model-based planners are. In the present work, we investigate how both approaches can be integrated into one framework that combines their strengths. We introduce Learning to Execute (L2E), which leverages information contained in approximate plans to learn universal policies that are conditioned on plans. In our robotic manipulation experiments, L2E exhibits increased performance when compared to pure RL, pure planning, or baseline methods combining learning and planning.
Plan-Based Relaxed Reward Shaping for Goal-Directed Tasks
Jul 14, 2021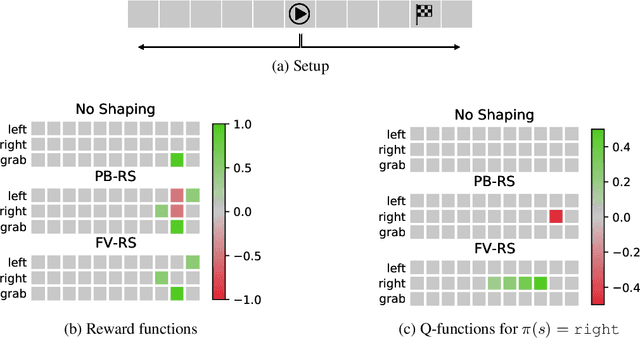
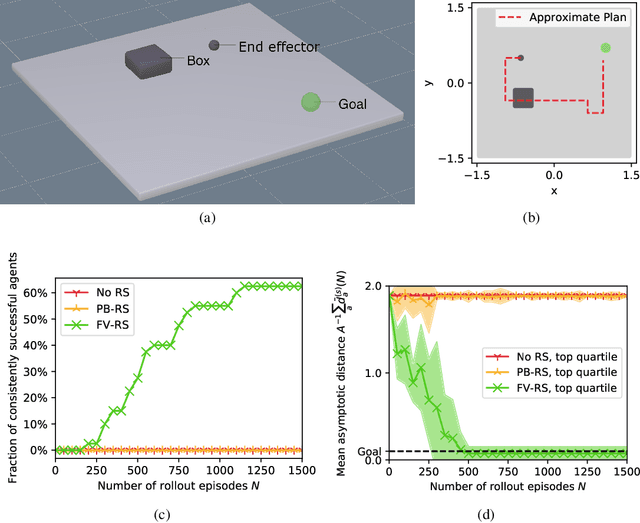
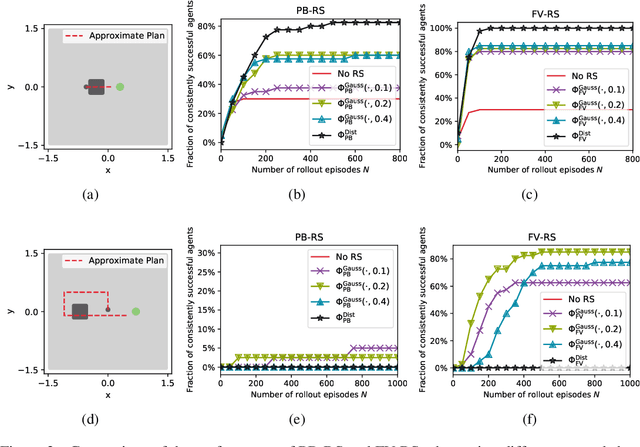

In high-dimensional state spaces, the usefulness of Reinforcement Learning (RL) is limited by the problem of exploration. This issue has been addressed using potential-based reward shaping (PB-RS) previously. In the present work, we introduce Final-Volume-Preserving Reward Shaping (FV-RS). FV-RS relaxes the strict optimality guarantees of PB-RS to a guarantee of preserved long-term behavior. Being less restrictive, FV-RS allows for reward shaping functions that are even better suited for improving the sample efficiency of RL algorithms. In particular, we consider settings in which the agent has access to an approximate plan. Here, we use examples of simulated robotic manipulation tasks to demonstrate that plan-based FV-RS can indeed significantly improve the sample efficiency of RL over plan-based PB-RS.
* Published as a conference paper at ICLR 2021