 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePush, Press, Slide: Mode-Aware Planar Contact Manipulation via Reduced-Order Models
Mar 17, 2026Non-prehensile planar manipulation, including pushing and press-and-slide, is critical for diverse robotic tasks, but notoriously challenging due to hybrid contact mechanics, under-actuation, and asymmetric friction limits that traditionally necessitate computationally expensive iterative control. In this paper, we propose a mode-aware framework for planar manipulation with one or two robotic arms based on contact topology selection and reduced-order kinematic modeling. Our core insight is that complex wrench-twist limit surface mechanics can be abstracted into a discrete library of physically intuitive models. We systematically map various single-arm and bimanual contact topologies to simple non-holonomic formulations, e.g. unicycle for simplified press-and-slide motion. By anchoring trajectory generation to these reduced-order models, our framework computes the required object wrench and distributes feasible, friction-bounded contact forces via a direct algebraic allocator. We incorporate manipulator kinematics to ensure long-horizon feasibility and demonstrate our fast, optimization-free approach in simulation across diverse single-arm and bimanual manipulation tasks. Supplementary videos and additional information are available at: https://sites.google.com/view/pushpressslide
SeGMan: Sequential and Guided Manipulation Planner for Robust Planning in 2D Constrained Environments
Mar 06, 2025


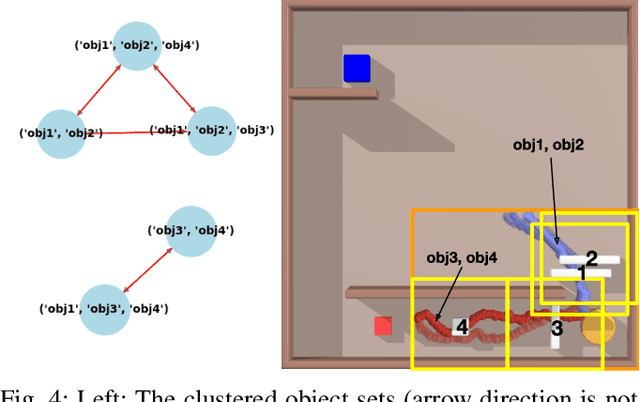
In this paper, we present SeGMan, a hybrid motion planning framework that integrates sampling-based and optimization-based techniques with a guided forward search to address complex, constrained sequential manipulation challenges, such as pick-and-place puzzles. SeGMan incorporates an adaptive subgoal selection method that adjusts the granularity of subgoals, enhancing overall efficiency. Furthermore, proposed generalizable heuristics guide the forward search in a more targeted manner. Extensive evaluations in maze-like tasks populated with numerous objects and obstacles demonstrate that SeGMan is capable of generating not only consistent and computationally efficient manipulation plans but also outperform state-of-the-art approaches.
Locally Adaptive One-Class Classifier Fusion with Dynamic $\ell$p-Norm Constraints for Robust Anomaly Detection
Nov 20, 2024


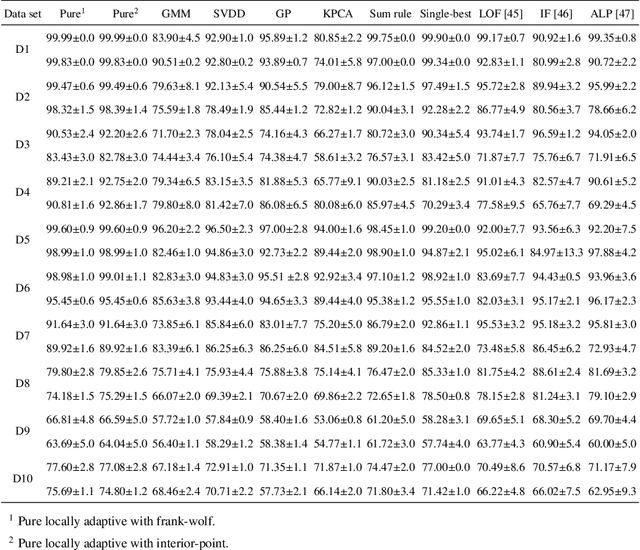
This paper presents a novel approach to one-class classifier fusion through locally adaptive learning with dynamic $\ell$p-norm constraints. We introduce a framework that dynamically adjusts fusion weights based on local data characteristics, addressing fundamental challenges in ensemble-based anomaly detection. Our method incorporates an interior-point optimization technique that significantly improves computational efficiency compared to traditional Frank-Wolfe approaches, achieving up to 19-fold speed improvements in complex scenarios. The framework is extensively evaluated on standard UCI benchmark datasets and specialized temporal sequence datasets, demonstrating superior performance across diverse anomaly types. Statistical validation through Skillings-Mack tests confirms our method's significant advantages over existing approaches, with consistent top rankings in both pure and non-pure learning scenarios. The framework's ability to adapt to local data patterns while maintaining computational efficiency makes it particularly valuable for real-time applications where rapid and accurate anomaly detection is crucial.
Interpretable Responsibility Sharing as a Heuristic for Task and Motion Planning
Sep 09, 2024
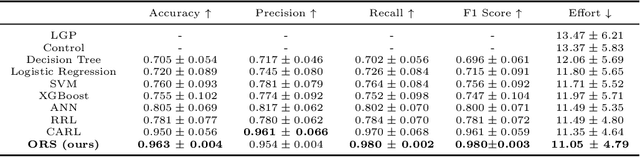
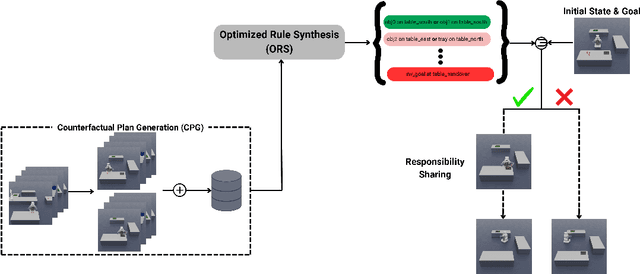

This article introduces a novel heuristic for Task and Motion Planning (TAMP) named Interpretable Responsibility Sharing (IRS), which enhances planning efficiency in domestic robots by leveraging human-constructed environments and inherent biases. Utilizing auxiliary objects (e.g., trays and pitchers), which are commonly found in household settings, IRS systematically incorporates these elements to simplify and optimize task execution. The heuristic is rooted in the novel concept of Responsibility Sharing (RS), where auxiliary objects share the task's responsibility with the embodied agent, dividing complex tasks into manageable sub-problems. This division not only reflects human usage patterns but also aids robots in navigating and manipulating within human spaces more effectively. By integrating Optimized Rule Synthesis (ORS) for decision-making, IRS ensures that the use of auxiliary objects is both strategic and context-aware, thereby improving the interpretability and effectiveness of robotic planning. Experiments conducted across various household tasks demonstrate that IRS significantly outperforms traditional methods by reducing the effort required in task execution and enhancing the overall decision-making process. This approach not only aligns with human intuitive methods but also offers a scalable solution adaptable to diverse domestic environments. Code is available at https://github.com/asyncs/IRS.
CUER: Corrected Uniform Experience Replay for Off-Policy Continuous Deep Reinforcement Learning Algorithms
Jun 13, 2024


The utilization of the experience replay mechanism enables agents to effectively leverage their experiences on several occasions. In previous studies, the sampling probability of the transitions was modified based on their relative significance. The process of reassigning sample probabilities for every transition in the replay buffer after each iteration is considered extremely inefficient. Hence, in order to enhance computing efficiency, experience replay prioritization algorithms reassess the importance of a transition as it is sampled. However, the relative importance of the transitions undergoes dynamic adjustments when the agent's policy and value function are iteratively updated. Furthermore, experience replay is a mechanism that retains the transitions generated by the agent's past policies, which could potentially diverge significantly from the agent's most recent policy. An increased deviation from the agent's most recent policy results in a greater frequency of off-policy updates, which has a negative impact on the agent's performance. In this paper, we develop a novel algorithm, Corrected Uniform Experience Replay (CUER), which stochastically samples the stored experience while considering the fairness among all other experiences without ignoring the dynamic nature of the transition importance by making sampled state distribution more on-policy. CUER provides promising improvements for off-policy continuous control algorithms in terms of sample efficiency, final performance, and stability of the policy during the training.
H-MaP: An Iterative and Hybrid Sequential Manipulation Planner
Mar 15, 2024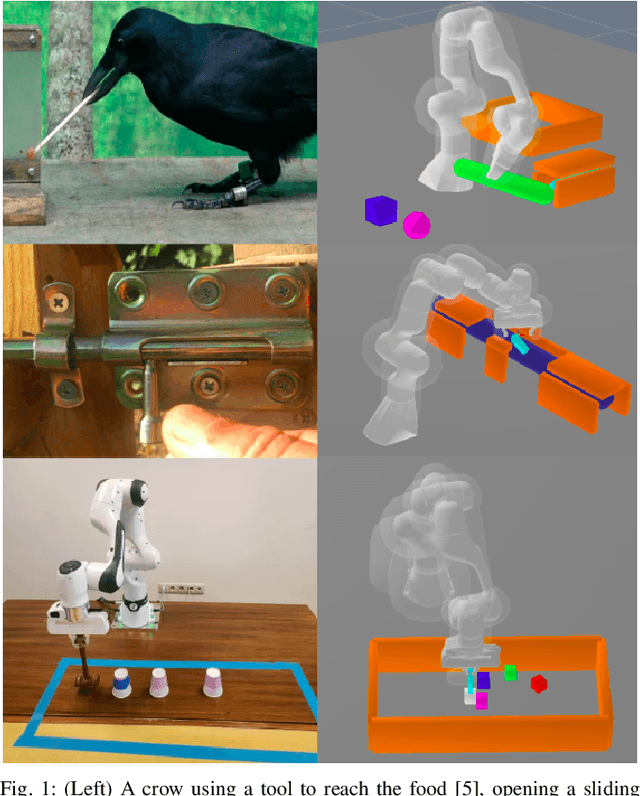



This study introduces the Hybrid Sequential Manipulation Planner (H-MaP), a novel approach that iteratively does motion planning using contact points and waypoints for complex sequential manipulation tasks in robotics. Combining optimization-based methods for generalizability and sampling-based methods for robustness, H-MaP enhances manipulation planning through active contact mode switches and enables interactions with auxiliary objects and tools. This framework, validated by a series of diverse physical manipulation tasks and real-robot experiments, offers a scalable and adaptable solution for complex real-world applications in robotic manipulation.
Contact Energy Based Hindsight Experience Prioritization
Dec 05, 2023
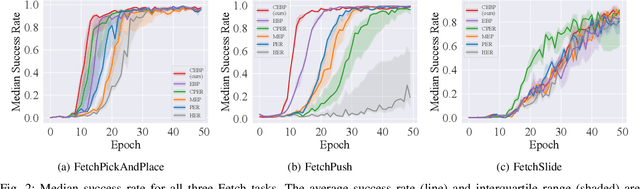
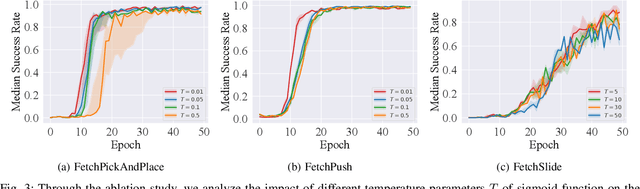
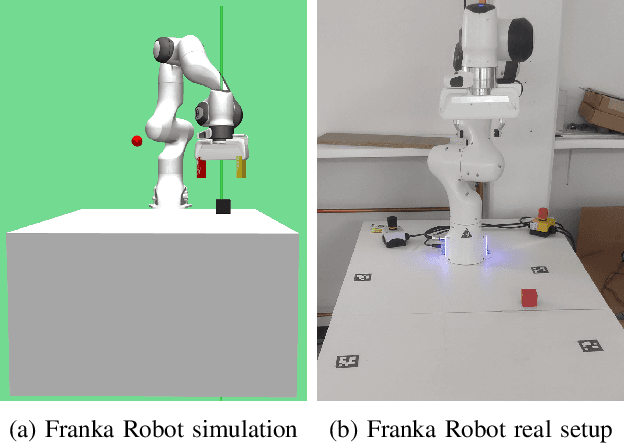
Multi-goal robot manipulation tasks with sparse rewards are difficult for reinforcement learning (RL) algorithms due to the inefficiency in collecting successful experiences. Recent algorithms such as Hindsight Experience Replay (HER) expedite learning by taking advantage of failed trajectories and replacing the desired goal with one of the achieved states so that any failed trajectory can be utilized as a contribution to learning. However, HER uniformly chooses failed trajectories, without taking into account which ones might be the most valuable for learning. In this paper, we address this problem and propose a novel approach Contact Energy Based Prioritization~(CEBP) to select the samples from the replay buffer based on rich information due to contact, leveraging the touch sensors in the gripper of the robot and object displacement. Our prioritization scheme favors sampling of contact-rich experiences, which are arguably the ones providing the largest amount of information. We evaluate our proposed approach on various sparse reward robotic tasks and compare them with the state-of-the-art methods. We show that our method surpasses or performs on par with those methods on robot manipulation tasks. Finally, we deploy the trained policy from our method to a real Franka robot for a pick-and-place task. We observe that the robot can solve the task successfully. The videos and code are publicly available at: https://erdiphd.github.io/HER_force
FViT-Grasp: Grasping Objects With Using Fast Vision Transformers
Nov 23, 2023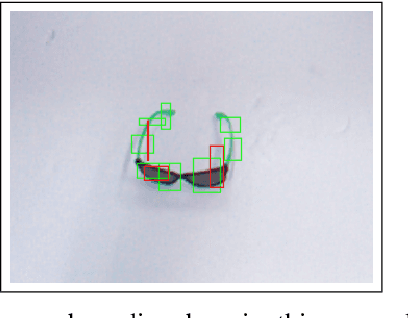
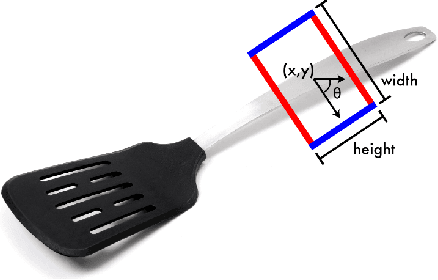
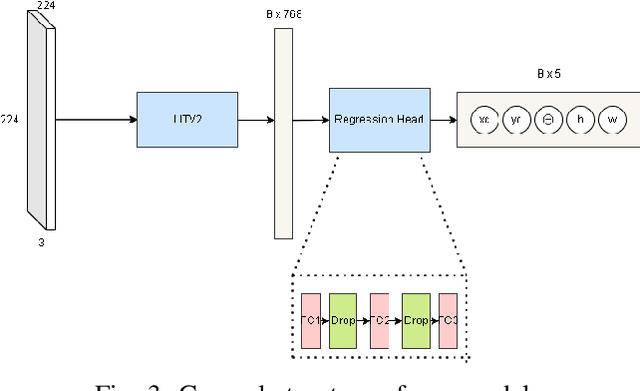
This study addresses the challenge of manipulation, a prominent issue in robotics. We have devised a novel methodology for swiftly and precisely identifying the optimal grasp point for a robot to manipulate an object. Our approach leverages a Fast Vision Transformer (FViT), a type of neural network designed for processing visual data and predicting the most suitable grasp location. Demonstrating state-of-the-art performance in terms of speed while maintaining a high level of accuracy, our method holds promise for potential deployment in real-time robotic grasping applications. We believe that this study provides a baseline for future research in vision-based robotic grasp applications. Its high speed and accuracy bring researchers closer to real-life applications.
Neural Field Representations of Articulated Objects for Robotic Manipulation Planning
Sep 14, 2023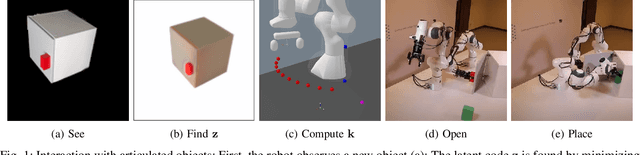
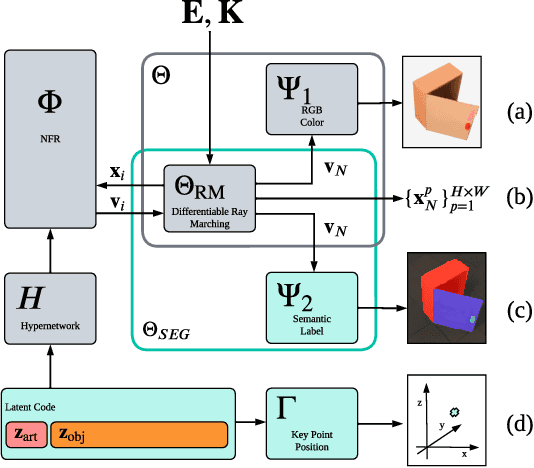

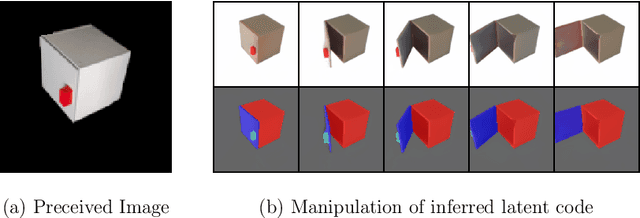
Traditional approaches for manipulation planning rely on an explicit geometric model of the environment to formulate a given task as an optimization problem. However, inferring an accurate model from raw sensor input is a hard problem in itself, in particular for articulated objects (e.g., closets, drawers). In this paper, we propose a Neural Field Representation (NFR) of articulated objects that enables manipulation planning directly from images. Specifically, after taking a few pictures of a new articulated object, we can forward simulate its possible movements, and, therefore, use this neural model directly for planning with trajectory optimization. Additionally, this representation can be used for shape reconstruction, semantic segmentation and image rendering, which provides a strong supervision signal during training and generalization. We show that our model, which was trained only on synthetic images, is able to extract a meaningful representation for unseen objects of the same class, both in simulation and with real images. Furthermore, we demonstrate that the representation enables robotic manipulation of an articulated object in the real world directly from images.
Spatial Reasoning via Deep Vision Models for Robotic Sequential Manipulation
Jul 06, 2023In this paper, we propose using deep neural architectures (i.e., vision transformers and ResNet) as heuristics for sequential decision-making in robotic manipulation problems. This formulation enables predicting the subset of objects that are relevant for completing a task. Such problems are often addressed by task and motion planning (TAMP) formulations combining symbolic reasoning and continuous motion planning. In essence, the action-object relationships are resolved for discrete, symbolic decisions that are used to solve manipulation motions (e.g., via nonlinear trajectory optimization). However, solving long-horizon tasks requires consideration of all possible action-object combinations which limits the scalability of TAMP approaches. To overcome this combinatorial complexity, we introduce a visual perception module integrated with a TAMP-solver. Given a task and an initial image of the scene, the learned model outputs the relevancy of objects to accomplish the task. By incorporating the predictions of the model into a TAMP formulation as a heuristic, the size of the search space is significantly reduced. Results show that our framework finds feasible solutions more efficiently when compared to a state-of-the-art TAMP solver.