 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUER: Corrected Uniform Experience Replay for Off-Policy Continuous Deep Reinforcement Learning Algorithms
Jun 13, 2024


The utilization of the experience replay mechanism enables agents to effectively leverage their experiences on several occasions. In previous studies, the sampling probability of the transitions was modified based on their relative significance. The process of reassigning sample probabilities for every transition in the replay buffer after each iteration is considered extremely inefficient. Hence, in order to enhance computing efficiency, experience replay prioritization algorithms reassess the importance of a transition as it is sampled. However, the relative importance of the transitions undergoes dynamic adjustments when the agent's policy and value function are iteratively updated. Furthermore, experience replay is a mechanism that retains the transitions generated by the agent's past policies, which could potentially diverge significantly from the agent's most recent policy. An increased deviation from the agent's most recent policy results in a greater frequency of off-policy updates, which has a negative impact on the agent's performance. In this paper, we develop a novel algorithm, Corrected Uniform Experience Replay (CUER), which stochastically samples the stored experience while considering the fairness among all other experiences without ignoring the dynamic nature of the transition importance by making sampled state distribution more on-policy. CUER provides promising improvements for off-policy continuous control algorithms in terms of sample efficiency, final performance, and stability of the policy during the training.
Binary Feature Mask Optimization for Feature Selection
Jan 23, 2024



We investigate feature selection problem for generic machine learning (ML) models. We introduce a novel framework that selects features considering the predictions of the model. Our framework innovates by using a novel feature masking approach to eliminate the features during the selection process, instead of completely removing them from the dataset. This allows us to use the same ML model during feature selection, unlike other feature selection methods where we need to train the ML model again as the dataset has different dimensions on each iteration. We obtain the mask operator using the predictions of the ML model, which offers a comprehensive view on the subsets of the features essential for the predictive performance of the model. A variety of approaches exist in the feature selection literature. However, no study has introduced a training-free framework for a generic ML model to select features while considering the importance of the feature subsets as a whole, instead of focusing on the individual features. We demonstrate significant performance improvements on the real-life datasets under different settings using LightGBM and Multi-Layer Perceptron as our ML models. Additionally, we openly share the implementation code for our methods to encourage the research and the contributions in this area.
AFS-BM: Enhancing Model Performance through Adaptive Feature Selection with Binary Masking
Jan 20, 2024



We study the problem of feature selection in general machine learning (ML) context, which is one of the most critical subjects in the field. Although, there exist many feature selection methods, however, these methods face challenges such as scalability, managing high-dimensional data, dealing with correlated features, adapting to variable feature importance, and integrating domain knowledge. To this end, we introduce the ``Adaptive Feature Selection with Binary Masking" (AFS-BM) which remedies these problems. AFS-BM achieves this by joint optimization for simultaneous feature selection and model training. In particular, we do the joint optimization and binary masking to continuously adapt the set of features and model parameters during the training process. This approach leads to significant improvements in model accuracy and a reduction in computational requirements. We provide an extensive set of experiments where we compare AFS-BM with the established feature selection methods using well-known datasets from real-life competitions. Our results show that AFS-BM makes significant improvement in terms of accuracy and requires significantly less computational complexity. This is due to AFS-BM's ability to dynamically adjust to the changing importance of features during the training process, which an important contribution to the field. We openly share our code for the replicability of our results and to facilitate further research.
Hierarchical Ensemble-Based Feature Selection for Time Series Forecasting
Oct 26, 2023We study a novel ensemble approach for feature selection based on hierarchical stacking in cases of non-stationarity and limited number of samples with large number of features. Our approach exploits the co-dependency between features using a hierarchical structure. Initially, a machine learning model is trained using a subset of features, and then the model's output is updated using another algorithm with the remaining features to minimize the target loss. This hierarchical structure allows for flexible depth and feature selection. By exploiting feature co-dependency hierarchically, our proposed approach overcomes the limitations of traditional feature selection methods and feature importance scores. The effectiveness of the approach is demonstrated on synthetic and real-life datasets, indicating improved performance with scalability and stability compared to the traditional methods and state-of-the-art approaches.
Hybrid State Space-based Learning for Sequential Data Prediction with Joint Optimization
Sep 19, 2023We investigate nonlinear prediction/regression in an online setting and introduce a hybrid model that effectively mitigates, via a joint mechanism through a state space formulation, the need for domain-specific feature engineering issues of conventional nonlinear prediction models and achieves an efficient mix of nonlinear and linear components. In particular, we use recursive structures to extract features from raw sequential sequences and a traditional linear time series model to deal with the intricacies of the sequential data, e.g., seasonality, trends. The state-of-the-art ensemble or hybrid models typically train the base models in a disjoint manner, which is not only time consuming but also sub-optimal due to the separation of modeling or independent training. In contrast, as the first time in the literature, we jointly optimize an enhanced recurrent neural network (LSTM) for automatic feature extraction from raw data and an ARMA-family time series model (SARIMAX) for effectively addressing peculiarities associated with time series data. We achieve this by introducing novel state space representations for the base models, which are then combined to provide a full state space representation of the hybrid or the ensemble. Hence, we are able to jointly optimize both models in a single pass via particle filtering, for which we also provide the update equations. The introduced architecture is generic so that one can use other recurrent architectures, e.g., GRUs, traditional time series-specific models, e.g., ETS or other optimization methods, e.g., EKF, UKF. Due to such novel combination and joint optimization, we demonstrate significant improvements in widely publicized real life competition datasets. We also openly share our code for further research and replicability of our results.
Deep Intrinsically Motivated Exploration in Continuous Control
Oct 01, 2022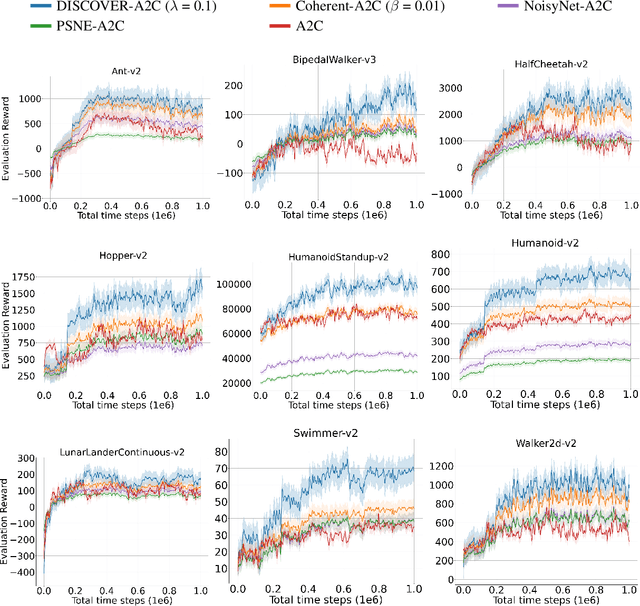
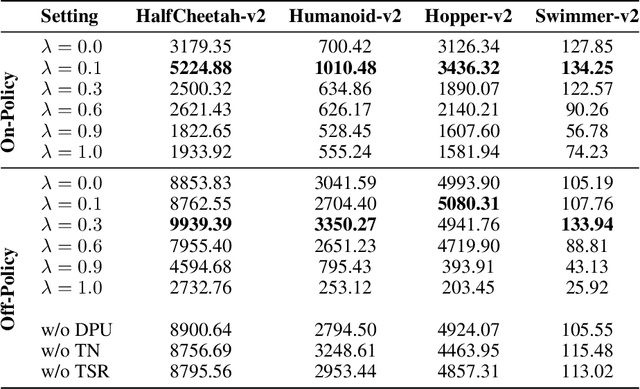
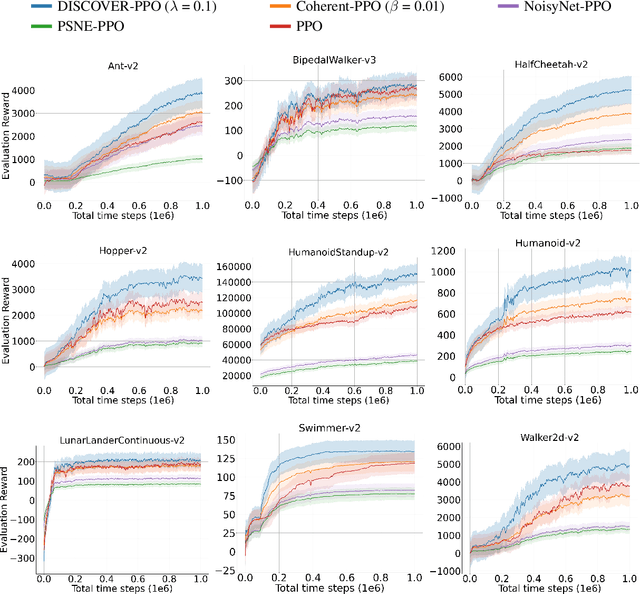

In continuous control, exploration is often performed through undirected strategies in which parameters of the networks or selected actions are perturbed by random noise. Although the deep setting of undirected exploration has been shown to improve the performance of on-policy methods, they introduce an excessive computational complexity and are known to fail in the off-policy setting. The intrinsically motivated exploration is an effective alternative to the undirected strategies, but they are usually studied for discrete action domains. In this paper, we investigate how intrinsic motivation can effectively be combined with deep reinforcement learning in the control of continuous systems to obtain a directed exploratory behavior. We adapt the existing theories on animal motivational systems into the reinforcement learning paradigm and introduce a novel and scalable directed exploration strategy. The introduced approach, motivated by the maximization of the value function's error, can benefit from a collected set of experiences by extracting useful information and unify the intrinsic exploration motivations in the literature under a single exploration objective. An extensive set of empirical studies demonstrate that our framework extends to larger and more diverse state spaces, dramatically improves the baselines, and outperforms the undirected strategies significantly.
Optimal Tracking in Prediction with Expert Advice
Aug 07, 2022We study the prediction with expert advice setting, where the aim is to produce a decision by combining the decisions generated by a set of experts, e.g., independently running algorithms. We achieve the min-max optimal dynamic regret under the prediction with expert advice setting, i.e., we can compete against time-varying (not necessarily fixed) combinations of expert decisions in an optimal manner. Our end-algorithm is truly online with no prior information, such as the time horizon or loss ranges, which are commonly used by different algorithms in the literature. Both our regret guarantees and the min-max lower bounds are derived with the general consideration that the expert losses can have time-varying properties and are possibly unbounded. Our algorithm can be adapted for restrictive scenarios regarding both loss feedback and decision making. Our guarantees are universal, i.e., our end-algorithm can provide regret guarantee against any competitor sequence in a min-max optimal manner with logarithmic complexity. Note that, to our knowledge, for the prediction with expert advice problem, our algorithms are the first to produce such universally optimal, adaptive and truly online guarantees with no prior knowledge.
Off-Policy Correction for Actor-Critic Algorithms in Deep Reinforcement Learning
Aug 01, 2022



Compared to on-policy policy gradient techniques, off-policy model-free deep reinforcement learning (RL) approaches that use previously gathered data can improve sampling efficiency. However, off-policy learning becomes challenging when the discrepancy between the distributions of the policy of interest and the policies that collected the data increases. Although the well-studied importance sampling and off-policy policy gradient techniques were proposed to compensate for this discrepancy, they usually require a collection of long trajectories that increases the computational complexity and induce additional problems such as vanishing or exploding gradients. Moreover, their generalization to continuous action domains is strictly limited as they require action probabilities, which is unsuitable for deterministic policies. To overcome these limitations, we introduce an alternative off-policy correction algorithm for continuous action spaces, Actor-Critic Off-Policy Correction (AC-Off-POC), to mitigate the potential drawbacks introduced by the previously collected data. Through a novel discrepancy measure computed by the agent's most recent action decisions on the states of the randomly sampled batch of transitions, the approach does not require actual or estimated action probabilities for any policy and offers an adequate one-step importance sampling. Theoretical results show that the introduced approach can achieve a contraction mapping with a fixed unique point, which allows a "safe" off-policy learning. Our empirical results suggest that AC-Off-POC consistently improves the state-of-the-art and attains higher returns in fewer steps than the competing methods by efficiently scheduling the learning rate in Q-learning and policy optimization.
Safe and Robust Experience Sharing for Deterministic Policy Gradient Algorithms
Jul 27, 2022



Learning in high dimensional continuous tasks is challenging, mainly when the experience replay memory is very limited. We introduce a simple yet effective experience sharing mechanism for deterministic policies in continuous action domains for the future off-policy deep reinforcement learning applications in which the allocated memory for the experience replay buffer is limited. To overcome the extrapolation error induced by learning from other agents' experiences, we facilitate our algorithm with a novel off-policy correction technique without any action probability estimates. We test the effectiveness of our method in challenging OpenAI Gym continuous control tasks and conclude that it can achieve a safe experience sharing across multiple agents and exhibits a robust performance when the replay memory is strictly limited.
A Hybrid Framework for Sequential Data Prediction with End-to-End Optimization
Mar 25, 2022

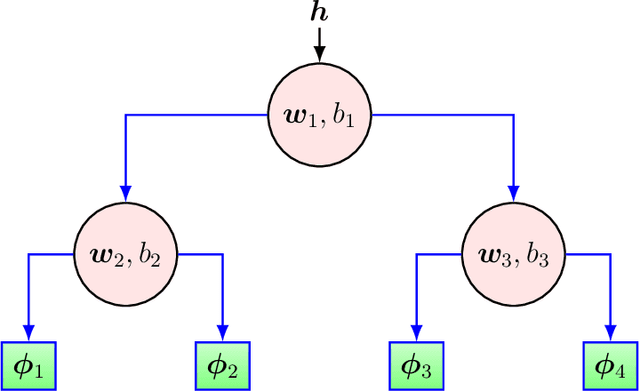

We investigate nonlinear prediction in an online setting and introduce a hybrid model that effectively mitigates, via an end-to-end architecture, the need for hand-designed features and manual model selection issues of conventional nonlinear prediction/regression methods. In particular, we use recursive structures to extract features from sequential signals, while preserving the state information, i.e., the history, and boosted decision trees to produce the final output. The connection is in an end-to-end fashion and we jointly optimize the whole architecture using stochastic gradient descent, for which we also provide the backward pass update equations. In particular, we employ a recurrent neural network (LSTM) for adaptive feature extraction from sequential data and a gradient boosting machinery (soft GBDT) for effective supervised regression. Our framework is generic so that one can use other deep learning architectures for feature extraction (such as RNNs and GRUs) and machine learning algorithms for decision making as long as they are differentiable. We demonstrate the learning behavior of our algorithm on synthetic data and the significant performance improvements over the conventional methods over various real life datasets. Furthermore, we openly share the source code of the proposed method to facilitate further research.