 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Intrinsically Motivated Exploration in Continuous Control
Paper and Code
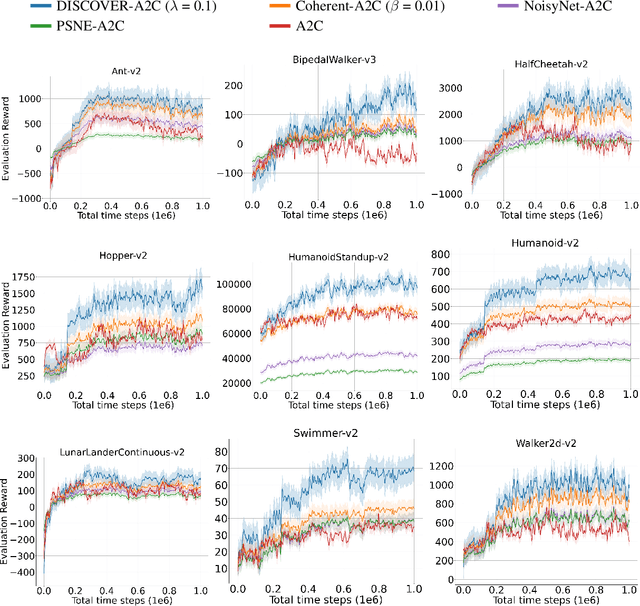
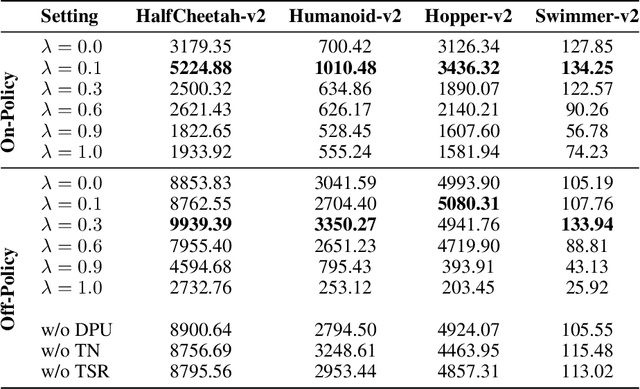
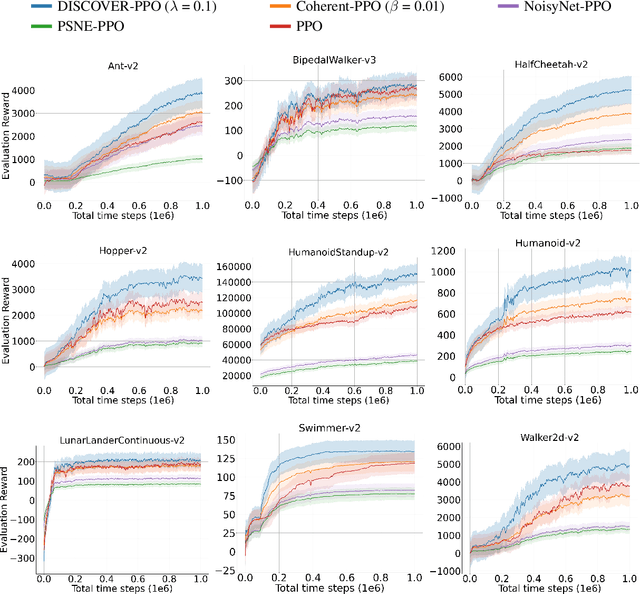

In continuous control, exploration is often performed through undirected strategies in which parameters of the networks or selected actions are perturbed by random noise. Although the deep setting of undirected exploration has been shown to improve the performance of on-policy methods, they introduce an excessive computational complexity and are known to fail in the off-policy setting. The intrinsically motivated exploration is an effective alternative to the undirected strategies, but they are usually studied for discrete action domains. In this paper, we investigate how intrinsic motivation can effectively be combined with deep reinforcement learning in the control of continuous systems to obtain a directed exploratory behavior. We adapt the existing theories on animal motivational systems into the reinforcement learning paradigm and introduce a novel and scalable directed exploration strategy. The introduced approach, motivated by the maximization of the value function's error, can benefit from a collected set of experiences by extracting useful information and unify the intrinsic exploration motivations in the literature under a single exploration objective. An extensive set of empirical studies demonstrate that our framework extends to larger and more diverse state spaces, dramatically improves the baselines, and outperforms the undirected strategies significantly.