 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-3.1-FoundationAI-SecurityLLM-Reasoning-8B Technical Report
Jan 28, 2026We present Foundation-Sec-8B-Reasoning, the first open-source native reasoning model for cybersecurity. Built upon our previously released Foundation-Sec-8B base model (derived from Llama-3.1-8B-Base), the model is trained through a two-stage process combining supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR). Our training leverages proprietary reasoning data spanning cybersecurity analysis, instruction-following, and mathematical reasoning. Evaluation across 10 cybersecurity benchmarks and 10 general-purpose benchmarks demonstrates performance competitive with significantly larger models on cybersecurity tasks while maintaining strong general capabilities. The model shows effective generalization on multi-hop reasoning tasks and strong safety performance when deployed with appropriate system prompts and guardrails. This work demonstrates that domain-specialized reasoning models can achieve strong performance on specialized tasks while maintaining broad general capabilities. We release the model publicly at https://huggingface.co/fdtn-ai/Foundation-Sec-8B-Reasoning.
Think Before You Retrieve: Learning Test-Time Adaptive Search with Small Language Models
Nov 10, 2025Effective information retrieval requires reasoning over partial evidence and refining strategies as information emerges. Yet current approaches fall short: neural retrievers lack reasoning capabilities, large language models (LLMs) provide semantic depth but at prohibitive cost, and query rewriting or decomposition limits improvement to static transformations. As a result, existing methods fail to capture the iterative dynamics of exploration, feedback, and revision that complex user queries demand. We introduce Orion, a training framework that enables compact models (350M-1.2B parameters) to perform iterative retrieval through learned search strategies. Orion combines: (1) synthetic trajectory generation and supervised fine-tuning to encourage diverse exploration patterns in models, (2) reinforcement learning (RL) that rewards effective query refinement and backtracking behaviors, and (3) inference-time beam search algorithms that exploit the self-reflection capabilities learned during RL. Despite using only 3% of the training data available, our 1.2B model achieves 77.6% success on SciFact (vs. 72.6% for prior retrievers), 25.2% on BRIGHT (vs. 22.1%), 63.2% on NFCorpus (vs. 57.8%), and remains competitive on FEVER, HotpotQA, and MSMarco. It outperforms retrievers up to 200-400x larger on five of six benchmarks. These findings suggest that retrieval performance can emerge from learned strategies, not just model scale, when models are trained to search, reflect, and revise.
Llama-3.1-FoundationAI-SecurityLLM-Base-8B Technical Report
Apr 28, 2025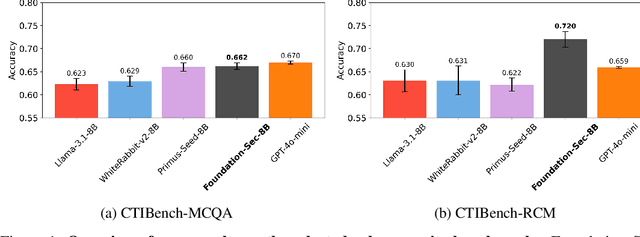
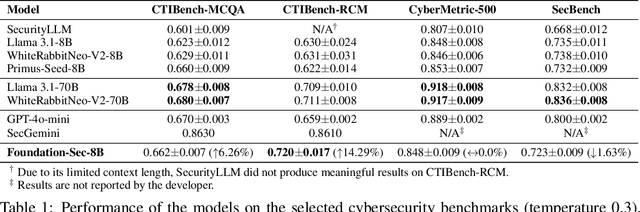
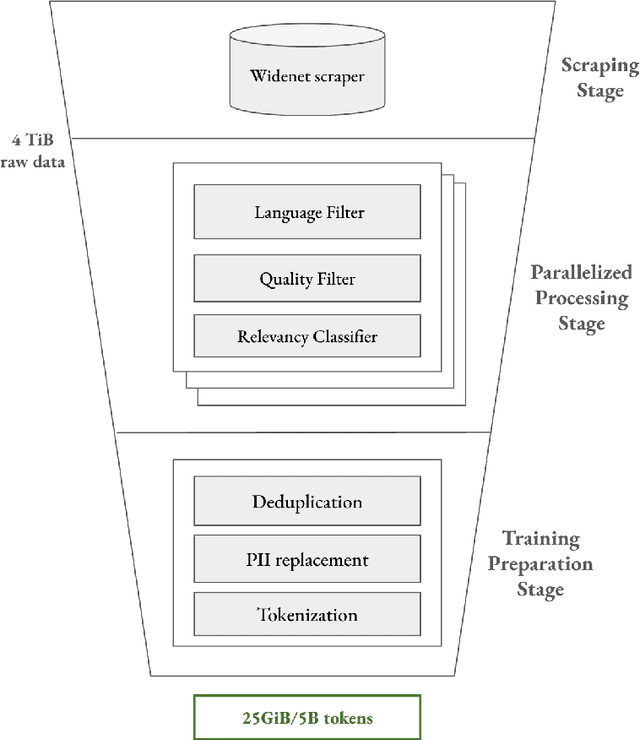

As transformer-based large language models (LLMs) increasingly permeate society, they have revolutionized domains such as software engineering, creative writing, and digital arts. However, their adoption in cybersecurity remains limited due to challenges like scarcity of specialized training data and complexity of representing cybersecurity-specific knowledge. To address these gaps, we present Foundation-Sec-8B, a cybersecurity-focused LLM built on the Llama 3.1 architecture and enhanced through continued pretraining on a carefully curated cybersecurity corpus. We evaluate Foundation-Sec-8B across both established and new cybersecurity benchmarks, showing that it matches Llama 3.1-70B and GPT-4o-mini in certain cybersecurity-specific tasks. By releasing our model to the public, we aim to accelerate progress and adoption of AI-driven tools in both public and private cybersecurity contexts.
Learning Task Representations from In-Context Learning
Feb 08, 2025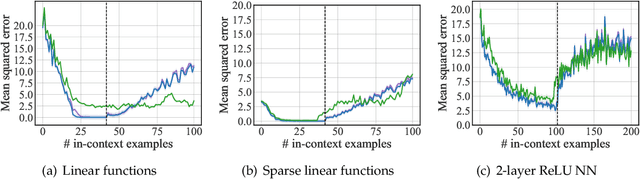
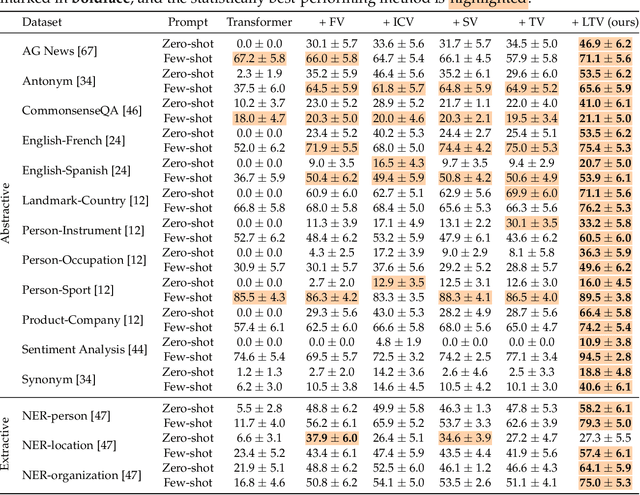
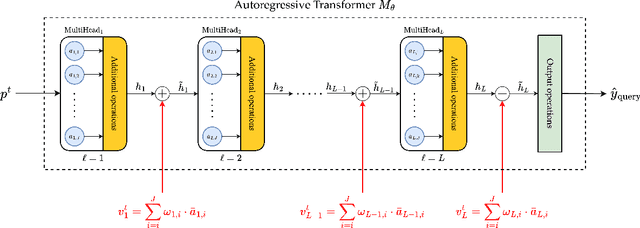
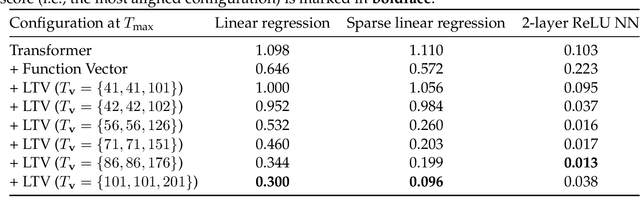
Large language models (LLMs) have demonstrated remarkable proficiency in in-context learning (ICL), where models adapt to new tasks through example-based prompts without requiring parameter updates. However, understanding how tasks are internally encoded and generalized remains a challenge. To address some of the empirical and technical gaps in the literature, we introduce an automated formulation for encoding task information in ICL prompts as a function of attention heads within the transformer architecture. This approach computes a single task vector as a weighted sum of attention heads, with the weights optimized causally via gradient descent. Our findings show that existing methods fail to generalize effectively to modalities beyond text. In response, we also design a benchmark to evaluate whether a task vector can preserve task fidelity in functional regression tasks. The proposed method successfully extracts task-specific information from in-context demonstrations and excels in both text and regression tasks, demonstrating its generalizability across modalities. Moreover, ablation studies show that our method's effectiveness stems from aligning the distribution of the last hidden state with that of an optimally performing in-context-learned model.
Compatible Gradient Approximations for Actor-Critic Algorithms
Sep 02, 2024



Deterministic policy gradient algorithms are foundational for actor-critic methods in controlling continuous systems, yet they often encounter inaccuracies due to their dependence on the derivative of the critic's value estimates with respect to input actions. This reliance requires precise action-value gradient computations, a task that proves challenging under function approximation. We introduce an actor-critic algorithm that bypasses the need for such precision by employing a zeroth-order approximation of the action-value gradient through two-point stochastic gradient estimation within the action space. This approach provably and effectively addresses compatibility issues inherent in deterministic policy gradient schemes. Empirical results further demonstrate that our algorithm not only matches but frequently exceeds the performance of current state-of-the-art methods.
Deep Intrinsically Motivated Exploration in Continuous Control
Oct 01, 2022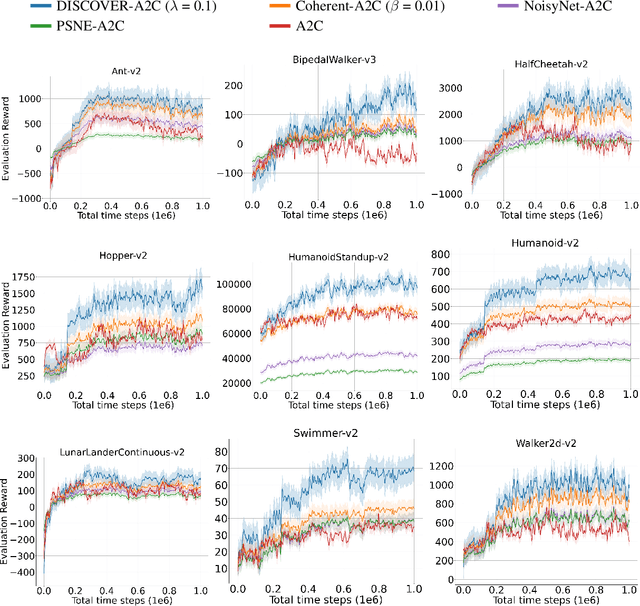
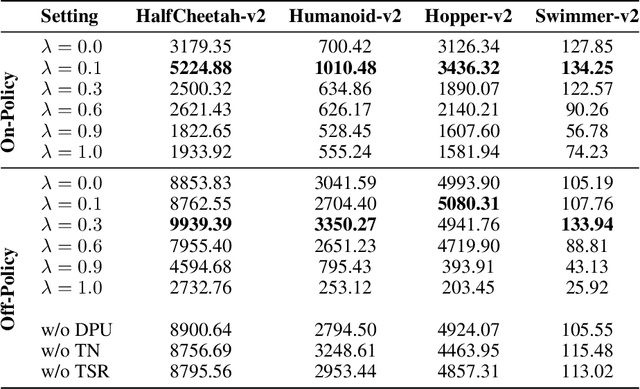

In continuous control, exploration is often performed through undirected strategies in which parameters of the networks or selected actions are perturbed by random noise. Although the deep setting of undirected exploration has been shown to improve the performance of on-policy methods, they introduce an excessive computational complexity and are known to fail in the off-policy setting. The intrinsically motivated exploration is an effective alternative to the undirected strategies, but they are usually studied for discrete action domains. In this paper, we investigate how intrinsic motivation can effectively be combined with deep reinforcement learning in the control of continuous systems to obtain a directed exploratory behavior. We adapt the existing theories on animal motivational systems into the reinforcement learning paradigm and introduce a novel and scalable directed exploration strategy. The introduced approach, motivated by the maximization of the value function's error, can benefit from a collected set of experiences by extracting useful information and unify the intrinsic exploration motivations in the literature under a single exploration objective. An extensive set of empirical studies demonstrate that our framework extends to larger and more diverse state spaces, dramatically improves the baselines, and outperforms the undirected strategies significantly.
Off-Policy Correction for Actor-Critic Algorithms in Deep Reinforcement Learning
Aug 01, 2022



Compared to on-policy policy gradient techniques, off-policy model-free deep reinforcement learning (RL) approaches that use previously gathered data can improve sampling efficiency. However, off-policy learning becomes challenging when the discrepancy between the distributions of the policy of interest and the policies that collected the data increases. Although the well-studied importance sampling and off-policy policy gradient techniques were proposed to compensate for this discrepancy, they usually require a collection of long trajectories that increases the computational complexity and induce additional problems such as vanishing or exploding gradients. Moreover, their generalization to continuous action domains is strictly limited as they require action probabilities, which is unsuitable for deterministic policies. To overcome these limitations, we introduce an alternative off-policy correction algorithm for continuous action spaces, Actor-Critic Off-Policy Correction (AC-Off-POC), to mitigate the potential drawbacks introduced by the previously collected data. Through a novel discrepancy measure computed by the agent's most recent action decisions on the states of the randomly sampled batch of transitions, the approach does not require actual or estimated action probabilities for any policy and offers an adequate one-step importance sampling. Theoretical results show that the introduced approach can achieve a contraction mapping with a fixed unique point, which allows a "safe" off-policy learning. Our empirical results suggest that AC-Off-POC consistently improves the state-of-the-art and attains higher returns in fewer steps than the competing methods by efficiently scheduling the learning rate in Q-learning and policy optimization.
Safe and Robust Experience Sharing for Deterministic Policy Gradient Algorithms
Jul 27, 2022



Learning in high dimensional continuous tasks is challenging, mainly when the experience replay memory is very limited. We introduce a simple yet effective experience sharing mechanism for deterministic policies in continuous action domains for the future off-policy deep reinforcement learning applications in which the allocated memory for the experience replay buffer is limited. To overcome the extrapolation error induced by learning from other agents' experiences, we facilitate our algorithm with a novel off-policy correction technique without any action probability estimates. We test the effectiveness of our method in challenging OpenAI Gym continuous control tasks and conclude that it can achieve a safe experience sharing across multiple agents and exhibits a robust performance when the replay memory is strictly limited.
Off-Policy Correction for Deep Deterministic Policy Gradient Algorithms via Batch Prioritized Experience Replay
Nov 12, 2021



The experience replay mechanism allows agents to use the experiences multiple times. In prior works, the sampling probability of the transitions was adjusted according to their importance. Reassigning sampling probabilities for every transition in the replay buffer after each iteration is highly inefficient. Therefore, experience replay prioritization algorithms recalculate the significance of a transition when the corresponding transition is sampled to gain computational efficiency. However, the importance level of the transitions changes dynamically as the policy and the value function of the agent are updated. In addition, experience replay stores the transitions are generated by the previous policies of the agent that may significantly deviate from the most recent policy of the agent. Higher deviation from the most recent policy of the agent leads to more off-policy updates, which is detrimental for the agent. In this paper, we develop a novel algorithm, Batch Prioritizing Experience Replay via KL Divergence (KLPER), which prioritizes batch of transitions rather than directly prioritizing each transition. Moreover, to reduce the off-policyness of the updates, our algorithm selects one batch among a certain number of batches and forces the agent to learn through the batch that is most likely generated by the most recent policy of the agent. We combine our algorithm with Deep Deterministic Policy Gradient and Twin Delayed Deep Deterministic Policy Gradient and evaluate it on various continuous control tasks. KLPER provides promising improvements for deep deterministic continuous control algorithms in terms of sample efficiency, final performance, and stability of the policy during the training.
AWD3: Dynamic Reduction of the Estimation Bias
Nov 12, 2021



Value-based deep Reinforcement Learning (RL) algorithms suffer from the estimation bias primarily caused by function approximation and temporal difference (TD) learning. This problem induces faulty state-action value estimates and therefore harms the performance and robustness of the learning algorithms. Although several techniques were proposed to tackle, learning algorithms still suffer from this bias. Here, we introduce a technique that eliminates the estimation bias in off-policy continuous control algorithms using the experience replay mechanism. We adaptively learn the weighting hyper-parameter beta in the Weighted Twin Delayed Deep Deterministic Policy Gradient algorithm. Our method is named Adaptive-WD3 (AWD3). We show through continuous control environments of OpenAI gym that our algorithm matches or outperforms the state-of-the-art off-policy policy gradient learning algorithms.