 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUSION: Full-Body Unified Motion Prior for Body and Hands via Diffusion
Jan 07, 2026Hands are central to interacting with our surroundings and conveying gestures, making their inclusion essential for full-body motion synthesis. Despite this, existing human motion synthesis methods fall short: some ignore hand motions entirely, while others generate full-body motions only for narrowly scoped tasks under highly constrained settings. A key obstacle is the lack of large-scale datasets that jointly capture diverse full-body motion with detailed hand articulation. While some datasets capture both, they are limited in scale and diversity. Conversely, large-scale datasets typically focus either on body motion without hands or on hand motions without the body. To overcome this, we curate and unify existing hand motion datasets with large-scale body motion data to generate full-body sequences that capture both hand and body. We then propose the first diffusion-based unconditional full-body motion prior, FUSION, which jointly models body and hand motion. Despite using a pose-based motion representation, FUSION surpasses state-of-the-art skeletal control models on the Keypoint Tracking task in the HumanML3D dataset and achieves superior motion naturalness. Beyond standard benchmarks, we demonstrate that FUSION can go beyond typical uses of motion priors through two applications: (1) generating detailed full-body motion including fingers during interaction given the motion of an object, and (2) generating Self-Interaction motions using an LLM to transform natural language cues into actionable motion constraints. For these applications, we develop an optimization pipeline that refines the latent space of our diffusion model to generate task-specific motions. Experiments on these tasks highlight precise control over hand motion while maintaining plausible full-body coordination. The code will be public.
HMP: Hand Motion Priors for Pose and Shape Estimation from Video
Dec 27, 2023
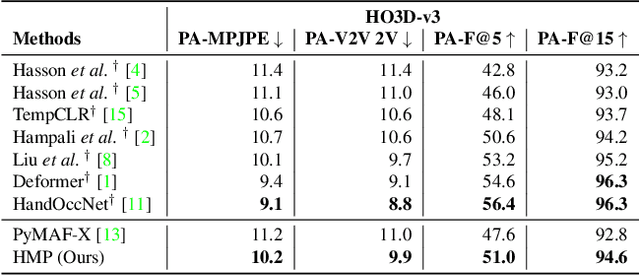


Understanding how humans interact with the world necessitates accurate 3D hand pose estimation, a task complicated by the hand's high degree of articulation, frequent occlusions, self-occlusions, and rapid motions. While most existing methods rely on single-image inputs, videos have useful cues to address aforementioned issues. However, existing video-based 3D hand datasets are insufficient for training feedforward models to generalize to in-the-wild scenarios. On the other hand, we have access to large human motion capture datasets which also include hand motions, e.g. AMASS. Therefore, we develop a generative motion prior specific for hands, trained on the AMASS dataset which features diverse and high-quality hand motions. This motion prior is then employed for video-based 3D hand motion estimation following a latent optimization approach. Our integration of a robust motion prior significantly enhances performance, especially in occluded scenarios. It produces stable, temporally consistent results that surpass conventional single-frame methods. We demonstrate our method's efficacy via qualitative and quantitative evaluations on the HO3D and DexYCB datasets, with special emphasis on an occlusion-focused subset of HO3D. Code is available at https://hmp.is.tue.mpg.de
Off-Policy Correction for Deep Deterministic Policy Gradient Algorithms via Batch Prioritized Experience Replay
Nov 12, 2021



The experience replay mechanism allows agents to use the experiences multiple times. In prior works, the sampling probability of the transitions was adjusted according to their importance. Reassigning sampling probabilities for every transition in the replay buffer after each iteration is highly inefficient. Therefore, experience replay prioritization algorithms recalculate the significance of a transition when the corresponding transition is sampled to gain computational efficiency. However, the importance level of the transitions changes dynamically as the policy and the value function of the agent are updated. In addition, experience replay stores the transitions are generated by the previous policies of the agent that may significantly deviate from the most recent policy of the agent. Higher deviation from the most recent policy of the agent leads to more off-policy updates, which is detrimental for the agent. In this paper, we develop a novel algorithm, Batch Prioritizing Experience Replay via KL Divergence (KLPER), which prioritizes batch of transitions rather than directly prioritizing each transition. Moreover, to reduce the off-policyness of the updates, our algorithm selects one batch among a certain number of batches and forces the agent to learn through the batch that is most likely generated by the most recent policy of the agent. We combine our algorithm with Deep Deterministic Policy Gradient and Twin Delayed Deep Deterministic Policy Gradient and evaluate it on various continuous control tasks. KLPER provides promising improvements for deep deterministic continuous control algorithms in terms of sample efficiency, final performance, and stability of the policy during the training.
AWD3: Dynamic Reduction of the Estimation Bias
Nov 12, 2021



Value-based deep Reinforcement Learning (RL) algorithms suffer from the estimation bias primarily caused by function approximation and temporal difference (TD) learning. This problem induces faulty state-action value estimates and therefore harms the performance and robustness of the learning algorithms. Although several techniques were proposed to tackle, learning algorithms still suffer from this bias. Here, we introduce a technique that eliminates the estimation bias in off-policy continuous control algorithms using the experience replay mechanism. We adaptively learn the weighting hyper-parameter beta in the Weighted Twin Delayed Deep Deterministic Policy Gradient algorithm. Our method is named Adaptive-WD3 (AWD3). We show through continuous control environments of OpenAI gym that our algorithm matches or outperforms the state-of-the-art off-policy policy gradient learning algorithms.
Parameter-Free Deterministic Reduction of the Estimation Bias in Continuous Control
Sep 24, 2021



Approximation of the value functions in value-based deep reinforcement learning systems induces overestimation bias, resulting in suboptimal policies. We show that when the reinforcement signals received by the agents have a high variance, deep actor-critic approaches that overcome the overestimation bias lead to a substantial underestimation bias. We introduce a parameter-free, novel deep Q-learning variant to reduce this underestimation bias for continuous control. By obtaining fixed weights in computing the critic objective as a linear combination of the approximate critic functions, our Q-value update rule integrates the concepts of Clipped Double Q-learning and Maxmin Q-learning. We test the performance of our improvement on a set of MuJoCo and Box2D continuous control tasks and find that it improves the state-of-the-art and outperforms the baseline algorithms in the majority of the environments.
Estimation Error Correction in Deep Reinforcement Learning for Deterministic Actor-Critic Methods
Sep 23, 2021

In value-based deep reinforcement learning methods, approximation of value functions induces overestimation bias and leads to suboptimal policies. We show that in deep actor-critic methods that aim to overcome the overestimation bias, if the reinforcement signals received by the agent have a high variance, a significant underestimation bias arises. To minimize the underestimation, we introduce a parameter-free, novel deep Q-learning variant. Our Q-value update rule combines the notions behind Clipped Double Q-learning and Maxmin Q-learning by computing the critic objective through the nested combination of maximum and minimum operators to bound the approximate value estimates. We evaluate our modification on the suite of several OpenAI Gym continuous control tasks, improving the state-of-the-art in every environment tested.