 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBimArt: A Unified Approach for the Synthesis of 3D Bimanual Interaction with Articulated Objects
Dec 06, 2024



We present BimArt, a novel generative approach for synthesizing 3D bimanual hand interactions with articulated objects. Unlike prior works, we do not rely on a reference grasp, a coarse hand trajectory, or separate modes for grasping and articulating. To achieve this, we first generate distance-based contact maps conditioned on the object trajectory with an articulation-aware feature representation, revealing rich bimanual patterns for manipulation. The learned contact prior is then used to guide our hand motion generator, producing diverse and realistic bimanual motions for object movement and articulation. Our work offers key insights into feature representation and contact prior for articulated objects, demonstrating their effectiveness in taming the complex, high-dimensional space of bimanual hand-object interactions. Through comprehensive quantitative experiments, we demonstrate a clear step towards simplified and high-quality hand-object animations that excel over the state-of-the-art in motion quality and diversity.
Learning to Stabilize Faces
Nov 22, 2024Nowadays, it is possible to scan faces and automatically register them with high quality. However, the resulting face meshes often need further processing: we need to stabilize them to remove unwanted head movement. Stabilization is important for tasks like game development or movie making which require facial expressions to be cleanly separated from rigid head motion. Since manual stabilization is labor-intensive, there have been attempts to automate it. However, previous methods remain impractical: they either still require some manual input, produce imprecise alignments, rely on dubious heuristics and slow optimization, or assume a temporally ordered input. Instead, we present a new learning-based approach that is simple and fully automatic. We treat stabilization as a regression problem: given two face meshes, our network directly predicts the rigid transform between them that brings their skulls into alignment. We generate synthetic training data using a 3D Morphable Model (3DMM), exploiting the fact that 3DMM parameters separate skull motion from facial skin motion. Through extensive experiments we show that our approach outperforms the state-of-the-art both quantitatively and qualitatively on the tasks of stabilizing discrete sets of facial expressions as well as dynamic facial performances. Furthermore, we provide an ablation study detailing the design choices and best practices to help others adopt our approach for their own uses. Supplementary videos can be found on the project webpage syntec-research.github.io/FaceStab.
HMP: Hand Motion Priors for Pose and Shape Estimation from Video
Dec 27, 2023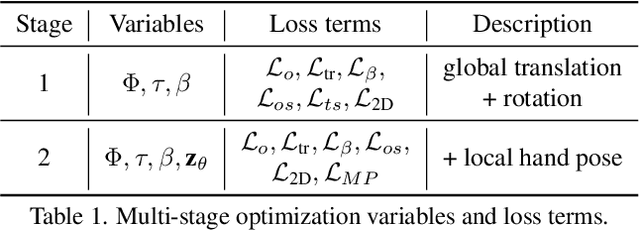
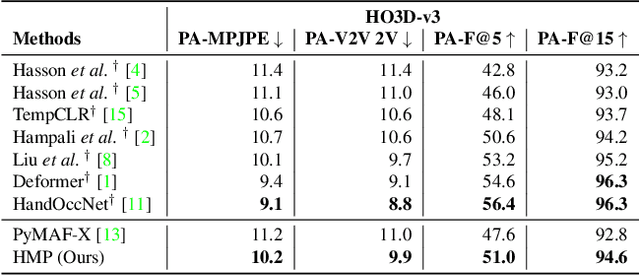


Understanding how humans interact with the world necessitates accurate 3D hand pose estimation, a task complicated by the hand's high degree of articulation, frequent occlusions, self-occlusions, and rapid motions. While most existing methods rely on single-image inputs, videos have useful cues to address aforementioned issues. However, existing video-based 3D hand datasets are insufficient for training feedforward models to generalize to in-the-wild scenarios. On the other hand, we have access to large human motion capture datasets which also include hand motions, e.g. AMASS. Therefore, we develop a generative motion prior specific for hands, trained on the AMASS dataset which features diverse and high-quality hand motions. This motion prior is then employed for video-based 3D hand motion estimation following a latent optimization approach. Our integration of a robust motion prior significantly enhances performance, especially in occluded scenarios. It produces stable, temporally consistent results that surpass conventional single-frame methods. We demonstrate our method's efficacy via qualitative and quantitative evaluations on the HO3D and DexYCB datasets, with special emphasis on an occlusion-focused subset of HO3D. Code is available at https://hmp.is.tue.mpg.de
Reconstructing Signing Avatars From Video Using Linguistic Priors
Apr 20, 2023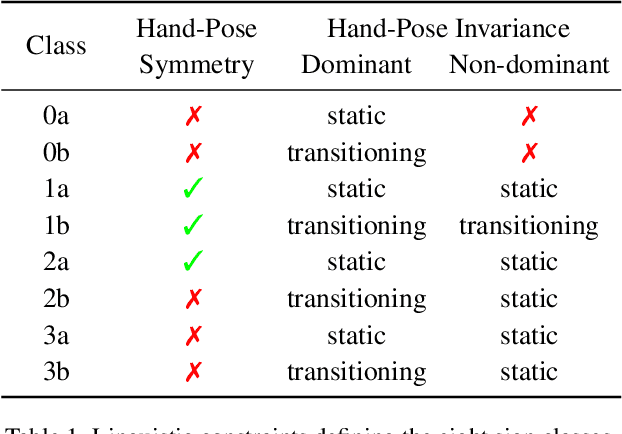
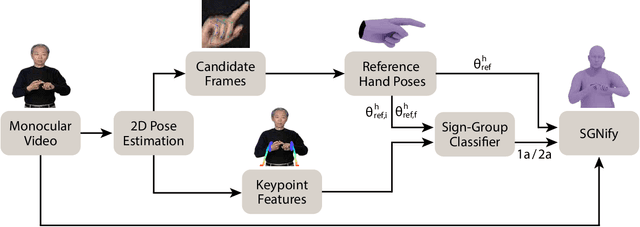

Sign language (SL) is the primary method of communication for the 70 million Deaf people around the world. Video dictionaries of isolated signs are a core SL learning tool. Replacing these with 3D avatars can aid learning and enable AR/VR applications, improving access to technology and online media. However, little work has attempted to estimate expressive 3D avatars from SL video; occlusion, noise, and motion blur make this task difficult. We address this by introducing novel linguistic priors that are universally applicable to SL and provide constraints on 3D hand pose that help resolve ambiguities within isolated signs. Our method, SGNify, captures fine-grained hand pose, facial expression, and body movement fully automatically from in-the-wild monocular SL videos. We evaluate SGNify quantitatively by using a commercial motion-capture system to compute 3D avatars synchronized with monocular video. SGNify outperforms state-of-the-art 3D body-pose- and shape-estimation methods on SL videos. A perceptual study shows that SGNify's 3D reconstructions are significantly more comprehensible and natural than those of previous methods and are on par with the source videos. Code and data are available at $\href{http://sgnify.is.tue.mpg.de}{\text{sgnify.is.tue.mpg.de}}$.
Spatio-Temporal Action Detection Under Large Motion
Sep 06, 2022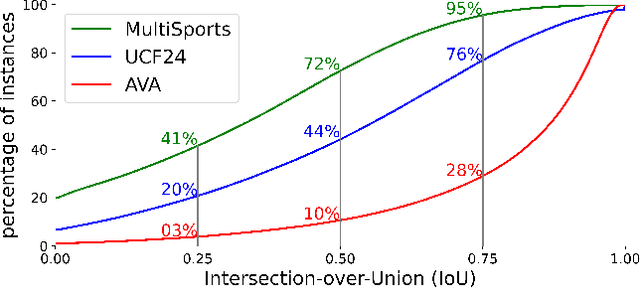
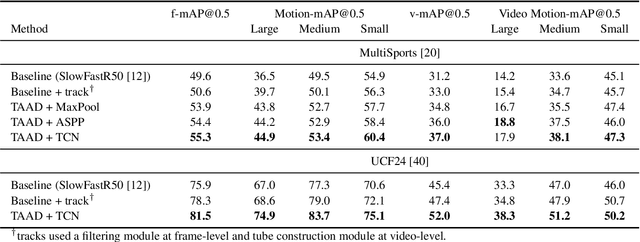

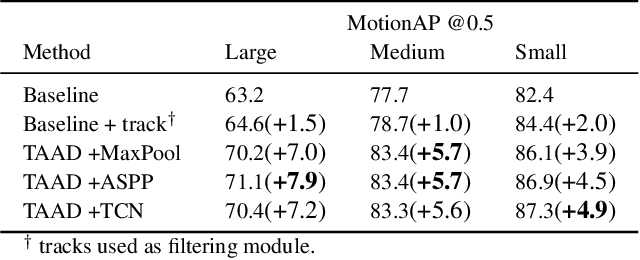
Current methods for spatiotemporal action tube detection often extend a bounding box proposal at a given keyframe into a 3D temporal cuboid and pool features from nearby frames. However, such pooling fails to accumulate meaningful spatiotemporal features if the position or shape of the actor shows large 2D motion and variability through the frames, due to large camera motion, large actor shape deformation, fast actor action and so on. In this work, we aim to study the performance of cuboid-aware feature aggregation in action detection under large action. Further, we propose to enhance actor feature representation under large motion by tracking actors and performing temporal feature aggregation along the respective tracks. We define the actor motion with intersection-over-union (IoU) between the boxes of action tubes/tracks at various fixed time scales. The action having a large motion would result in lower IoU over time, and slower actions would maintain higher IoU. We find that track-aware feature aggregation consistently achieves a large improvement in action detection performance, especially for actions under large motion compared to the cuboid-aware baseline. As a result, we also report state-of-the-art on the large-scale MultiSports dataset.
Accurate 3D Body Shape Regression using Metric and Semantic Attributes
Jun 14, 2022

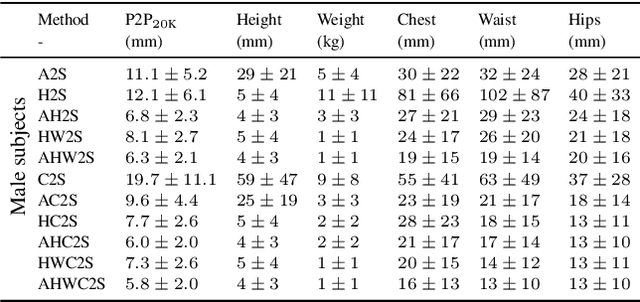
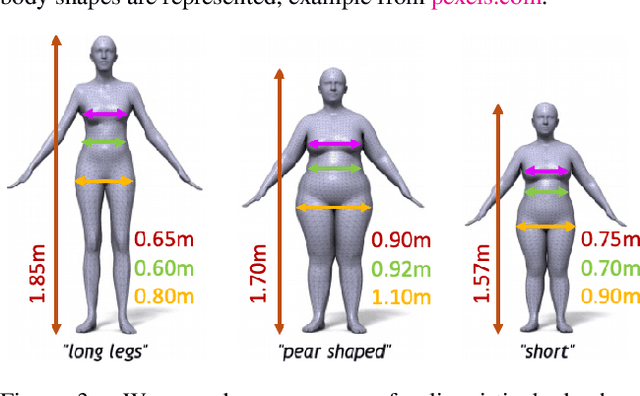
While methods that regress 3D human meshes from images have progressed rapidly, the estimated body shapes often do not capture the true human shape. This is problematic since, for many applications, accurate body shape is as important as pose. The key reason that body shape accuracy lags pose accuracy is the lack of data. While humans can label 2D joints, and these constrain 3D pose, it is not so easy to "label" 3D body shape. Since paired data with images and 3D body shape are rare, we exploit two sources of information: (1) we collect internet images of diverse "fashion" models together with a small set of anthropometric measurements; (2) we collect linguistic shape attributes for a wide range of 3D body meshes and the model images. Taken together, these datasets provide sufficient constraints to infer dense 3D shape. We exploit the anthropometric measurements and linguistic shape attributes in several novel ways to train a neural network, called SHAPY, that regresses 3D human pose and shape from an RGB image. We evaluate SHAPY on public benchmarks, but note that they either lack significant body shape variation, ground-truth shape, or clothing variation. Thus, we collect a new dataset for evaluating 3D human shape estimation, called HBW, containing photos of "Human Bodies in the Wild" for which we have ground-truth 3D body scans. On this new benchmark, SHAPY significantly outperforms state-of-the-art methods on the task of 3D body shape estimation. This is the first demonstration that 3D body shape regression from images can be trained from easy-to-obtain anthropometric measurements and linguistic shape attributes. Our model and data are available at: shapy.is.tue.mpg.de
* First two authors contributed equally
GOAL: Generating 4D Whole-Body Motion for Hand-Object Grasping
Dec 21, 2021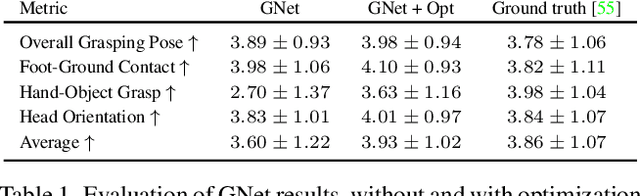
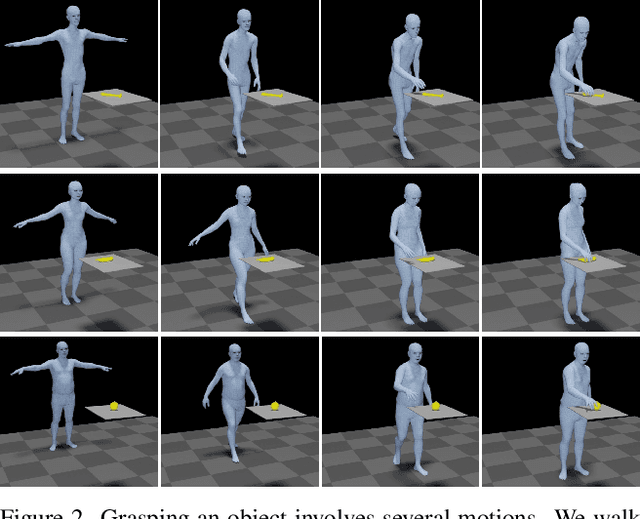
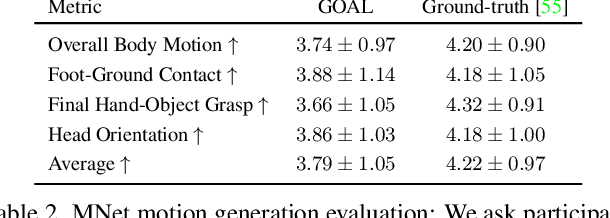
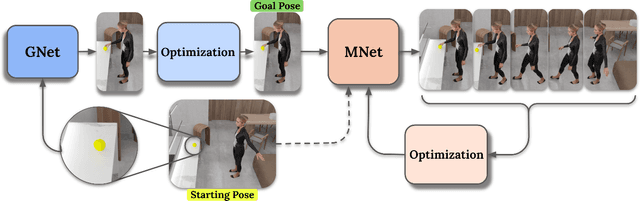
Generating digital humans that move realistically has many applications and is widely studied, but existing methods focus on the major limbs of the body, ignoring the hands and head. Hands have been separately studied but the focus has been on generating realistic static grasps of objects. To synthesize virtual characters that interact with the world, we need to generate full-body motions and realistic hand grasps simultaneously. Both sub-problems are challenging on their own and, together, the state-space of poses is significantly larger, the scales of hand and body motions differ, and the whole-body posture and the hand grasp must agree, satisfy physical constraints, and be plausible. Additionally, the head is involved because the avatar must look at the object to interact with it. For the first time, we address the problem of generating full-body, hand and head motions of an avatar grasping an unknown object. As input, our method, called GOAL, takes a 3D object, its position, and a starting 3D body pose and shape. GOAL outputs a sequence of whole-body poses using two novel networks. First, GNet generates a goal whole-body grasp with a realistic body, head, arm, and hand pose, as well as hand-object contact. Second, MNet generates the motion between the starting and goal pose. This is challenging, as it requires the avatar to walk towards the object with foot-ground contact, orient the head towards it, reach out, and grasp it with a realistic hand pose and hand-object contact. To achieve this the networks exploit a representation that combines SMPL-X body parameters and 3D vertex offsets. We train and evaluate GOAL, both qualitatively and quantitatively, on the GRAB dataset. Results show that GOAL generalizes well to unseen objects, outperforming baselines. GOAL takes a step towards synthesizing realistic full-body object grasping.
Learning to Fit Morphable Models
Nov 29, 2021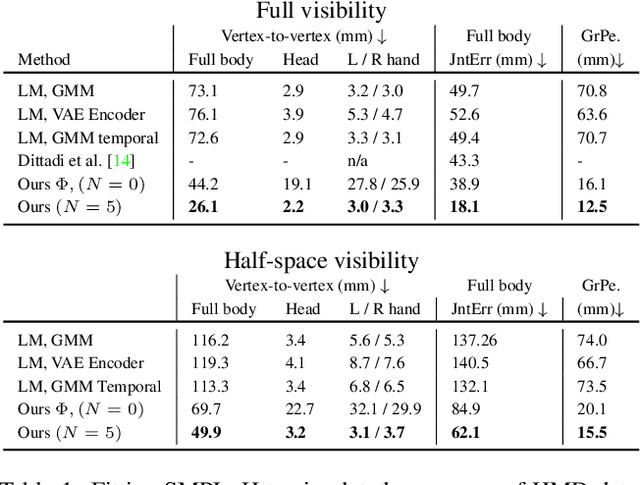


Fitting parametric models of human bodies, hands or faces to sparse input signals in an accurate, robust, and fast manner has the promise of significantly improving immersion in AR and VR scenarios. A common first step in systems that tackle these problems is to regress the parameters of the parametric model directly from the input data. This approach is fast, robust, and is a good starting point for an iterative minimization algorithm. The latter searches for the minimum of an energy function, typically composed of a data term and priors that encode our knowledge about the problem's structure. While this is undoubtedly a very successful recipe, priors are often hand defined heuristics and finding the right balance between the different terms to achieve high quality results is a non-trivial task. Furthermore, converting and optimizing these systems to run in a performant way requires custom implementations that demand significant time investments from both engineers and domain experts. In this work, we build upon recent advances in learned optimization and propose an update rule inspired by the classic Levenberg-Marquardt algorithm. We show the effectiveness of the proposed neural optimizer on the problems of 3D body surface estimation from a head-mounted device and face fitting from 2D landmarks. Our method can easily be applied to new model fitting problems and offers a competitive alternative to well tuned 'traditional' model fitting pipelines, both in terms of accuracy and speed.
Collaborative Regression of Expressive Bodies using Moderation
May 11, 2021

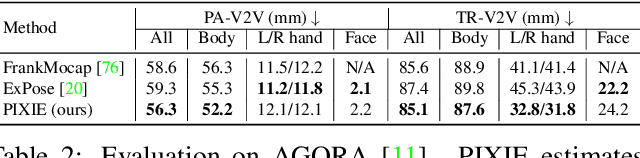
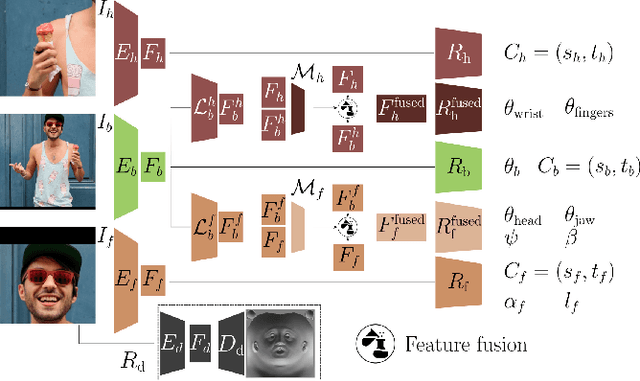
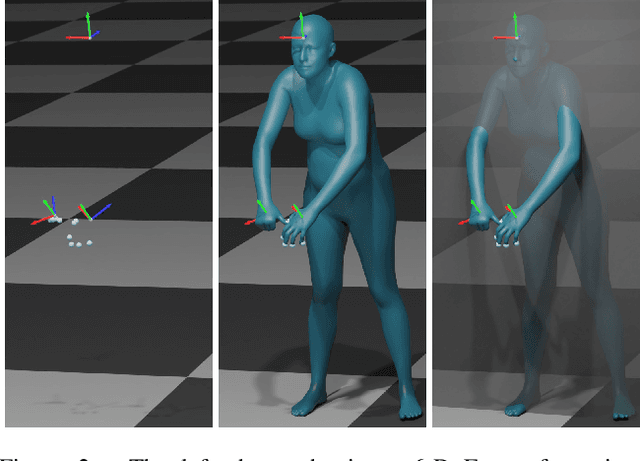
Recovering expressive humans from images is essential for understanding human behavior. Methods that estimate 3D bodies, faces, or hands have progressed significantly, yet separately. Face methods recover accurate 3D shape and geometric details, but need a tight crop and struggle with extreme views and low resolution. Whole-body methods are robust to a wide range of poses and resolutions, but provide only a rough 3D face shape without details like wrinkles. To get the best of both worlds, we introduce PIXIE, which produces animatable, whole-body 3D avatars from a single image, with realistic facial detail. To get accurate whole bodies, PIXIE uses two key observations. First, body parts are correlated, but existing work combines independent estimates from body, face, and hand experts, by trusting them equally. PIXIE introduces a novel moderator that merges the features of the experts, weighted by their confidence. Uniquely, part experts can contribute to the whole, using SMPL-X's shared shape space across all body parts. Second, human shape is highly correlated with gender, but existing work ignores this. We label training images as male, female, or non-binary, and train PIXIE to infer "gendered" 3D body shapes with a novel shape loss. In addition to 3D body pose and shape parameters, PIXIE estimates expression, illumination, albedo and 3D surface displacements for the face. Quantitative and qualitative evaluation shows that PIXIE estimates 3D humans with a more accurate whole-body shape and detailed face shape than the state of the art. Our models and code are available for research at https://pixie.is.tue.mpg.de.
Monocular Expressive Body Regression through Body-Driven Attention
Aug 20, 2020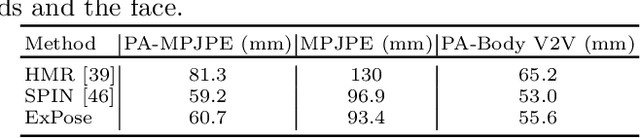
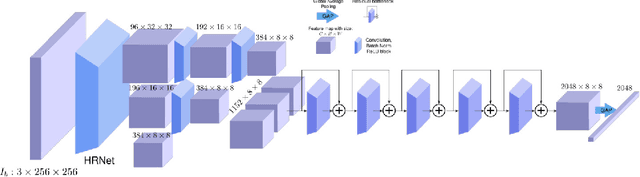
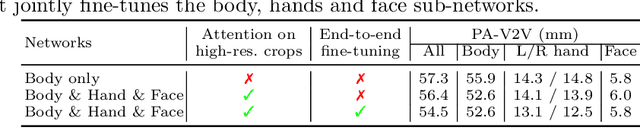

To understand how people look, interact, or perform tasks, we need to quickly and accurately capture their 3D body, face, and hands together from an RGB image. Most existing methods focus only on parts of the body. A few recent approaches reconstruct full expressive 3D humans from images using 3D body models that include the face and hands. These methods are optimization-based and thus slow, prone to local optima, and require 2D keypoints as input. We address these limitations by introducing ExPose (EXpressive POse and Shape rEgression), which directly regresses the body, face, and hands, in SMPL-X format, from an RGB image. This is a hard problem due to the high dimensionality of the body and the lack of expressive training data. Additionally, hands and faces are much smaller than the body, occupying very few image pixels. This makes hand and face estimation hard when body images are downscaled for neural networks. We make three main contributions. First, we account for the lack of training data by curating a dataset of SMPL-X fits on in-the-wild images. Second, we observe that body estimation localizes the face and hands reasonably well. We introduce body-driven attention for face and hand regions in the original image to extract higher-resolution crops that are fed to dedicated refinement modules. Third, these modules exploit part-specific knowledge from existing face- and hand-only datasets. ExPose estimates expressive 3D humans more accurately than existing optimization methods at a small fraction of the computational cost. Our data, model and code are available for research at https://expose.is.tue.mpg.de .