 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-UAVBench: How Well Do Multimodal Large Language Models See, Think, and Plan in Low-Altitude UAV Scenarios?
Dec 29, 2025While Multimodal Large Language Models (MLLMs) have exhibited remarkable general intelligence across diverse domains, their potential in low-altitude applications dominated by Unmanned Aerial Vehicles (UAVs) remains largely underexplored. Existing MLLM benchmarks rarely cover the unique challenges of low-altitude scenarios, while UAV-related evaluations mainly focus on specific tasks such as localization or navigation, without a unified evaluation of MLLMs'general intelligence. To bridge this gap, we present MM-UAVBench, a comprehensive benchmark that systematically evaluates MLLMs across three core capability dimensions-perception, cognition, and planning-in low-altitude UAV scenarios. MM-UAVBench comprises 19 sub-tasks with over 5.7K manually annotated questions, all derived from real-world UAV data collected from public datasets. Extensive experiments on 16 open-source and proprietary MLLMs reveal that current models struggle to adapt to the complex visual and cognitive demands of low-altitude scenarios. Our analyses further uncover critical bottlenecks such as spatial bias and multi-view understanding that hinder the effective deployment of MLLMs in UAV scenarios. We hope MM-UAVBench will foster future research on robust and reliable MLLMs for real-world UAV intelligence.
VHOI: Controllable Video Generation of Human-Object Interactions from Sparse Trajectories via Motion Densification
Dec 10, 2025Synthesizing realistic human-object interactions (HOI) in video is challenging due to the complex, instance-specific interaction dynamics of both humans and objects. Incorporating controllability in video generation further adds to the complexity. Existing controllable video generation approaches face a trade-off: sparse controls like keypoint trajectories are easy to specify but lack instance-awareness, while dense signals such as optical flow, depths or 3D meshes are informative but costly to obtain. We propose VHOI, a two-stage framework that first densifies sparse trajectories into HOI mask sequences, and then fine-tunes a video diffusion model conditioned on these dense masks. We introduce a novel HOI-aware motion representation that uses color encodings to distinguish not only human and object motion, but also body-part-specific dynamics. This design incorporates a human prior into the conditioning signal and strengthens the model's ability to understand and generate realistic HOI dynamics. Experiments demonstrate state-of-the-art results in controllable HOI video generation. VHOI is not limited to interaction-only scenarios and can also generate full human navigation leading up to object interactions in an end-to-end manner. Project page: https://vcai.mpi-inf.mpg.de/projects/vhoi/.
BimArt: A Unified Approach for the Synthesis of 3D Bimanual Interaction with Articulated Objects
Dec 06, 2024



We present BimArt, a novel generative approach for synthesizing 3D bimanual hand interactions with articulated objects. Unlike prior works, we do not rely on a reference grasp, a coarse hand trajectory, or separate modes for grasping and articulating. To achieve this, we first generate distance-based contact maps conditioned on the object trajectory with an articulation-aware feature representation, revealing rich bimanual patterns for manipulation. The learned contact prior is then used to guide our hand motion generator, producing diverse and realistic bimanual motions for object movement and articulation. Our work offers key insights into feature representation and contact prior for articulated objects, demonstrating their effectiveness in taming the complex, high-dimensional space of bimanual hand-object interactions. Through comprehensive quantitative experiments, we demonstrate a clear step towards simplified and high-quality hand-object animations that excel over the state-of-the-art in motion quality and diversity.
ChineseWebText 2.0: Large-Scale High-quality Chinese Web Text with Multi-dimensional and fine-grained information
Nov 29, 2024



During the development of large language models (LLMs), pre-training data play a critical role in shaping LLMs' capabilities. In recent years several large-scale and high-quality pre-training datasets have been released to accelerate the research of LLMs, including ChineseWebText1.0, C4, Pile, WanJuan, MAPCC and others. However, as LLMs continue to evolve, focus has increasingly shifted to domain-specific capabilities and safety concerns, making those previous coarse-grained texts insufficient for meeting training requirements. Furthermore, fine-grained information, such as quality, domain and toxicity, is becoming increasingly important in building powerful and reliable LLMs for various scenarios. To address these challenges, in this paper we propose a new tool-chain called MDFG-tool for constructing large-scale and high-quality Chinese datasets with multi-dimensional and fine-grained information. First, we employ manually crafted rules to discard explicit noisy texts from raw contents. Second, the quality evaluation model, domain classifier, and toxicity evaluation model are well-designed to assess the remaining cleaned data respectively. Finally, we integrate these three types of fine-grained information for each text. With this approach, we release the largest, high-quality and fine-grained Chinese text ChineseWebText2.0, which consists of 3.8TB and each text is associated with a quality score, domain labels, a toxicity label and a toxicity score, facilitating the LLM researchers to select data based on various types of fine-grained information. The data, codes and the tool-chain are available on this website https://github.com/CASIA-LM/ChineseWebText-2.0
ROAM: Robust and Object-aware Motion Generation using Neural Pose Descriptors
Aug 24, 2023



Existing automatic approaches for 3D virtual character motion synthesis supporting scene interactions do not generalise well to new objects outside training distributions, even when trained on extensive motion capture datasets with diverse objects and annotated interactions. This paper addresses this limitation and shows that robustness and generalisation to novel scene objects in 3D object-aware character synthesis can be achieved by training a motion model with as few as one reference object. We leverage an implicit feature representation trained on object-only datasets, which encodes an SE(3)-equivariant descriptor field around the object. Given an unseen object and a reference pose-object pair, we optimise for the object-aware pose that is closest in the feature space to the reference pose. Finally, we use l-NSM, i.e., our motion generation model that is trained to seamlessly transition from locomotion to object interaction with the proposed bidirectional pose blending scheme. Through comprehensive numerical comparisons to state-of-the-art methods and in a user study, we demonstrate substantial improvements in 3D virtual character motion and interaction quality and robustness to scenarios with unseen objects. Our project page is available at https://vcai.mpi-inf.mpg.de/projects/ROAM/.
Few-Shot Adaptation of Pre-Trained Networks for Domain Shift
May 30, 2022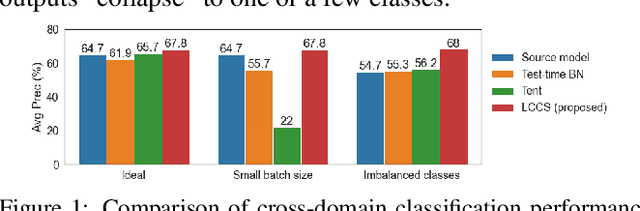



Deep networks are prone to performance degradation when there is a domain shift between the source (training) data and target (test) data. Recent test-time adaptation methods update batch normalization layers of pre-trained source models deployed in new target environments with streaming data to mitigate such performance degradation. Although such methods can adapt on-the-fly without first collecting a large target domain dataset, their performance is dependent on streaming conditions such as mini-batch size and class-distribution, which can be unpredictable in practice. In this work, we propose a framework for few-shot domain adaptation to address the practical challenges of data-efficient adaptation. Specifically, we propose a constrained optimization of feature normalization statistics in pre-trained source models supervised by a small support set from the target domain. Our method is easy to implement and improves source model performance with as few as one sample per class for classification tasks. Extensive experiments on 5 cross-domain classification and 4 semantic segmentation datasets show that our method achieves more accurate and reliable performance than test-time adaptation, while not being constrained by streaming conditions.
Revisiting Pretraining for Semi-Supervised Learning in the Low-Label Regime
May 06, 2022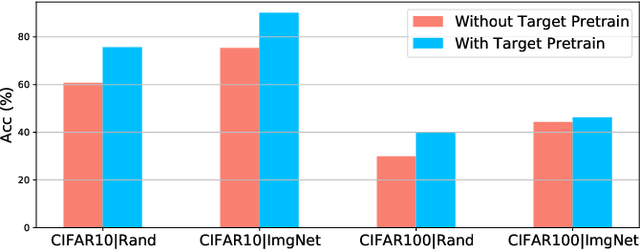
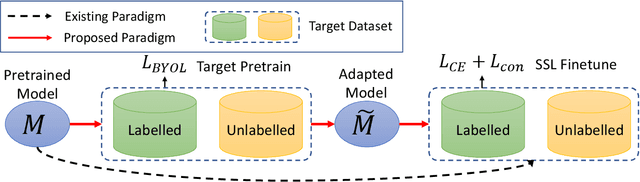
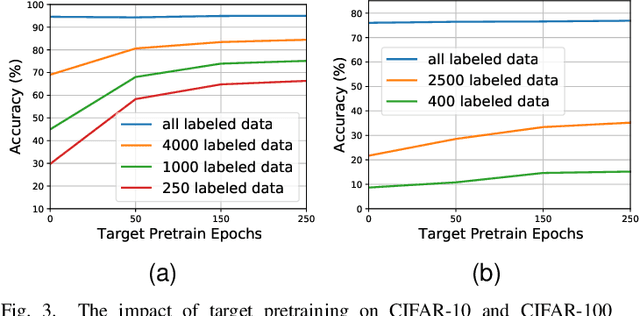
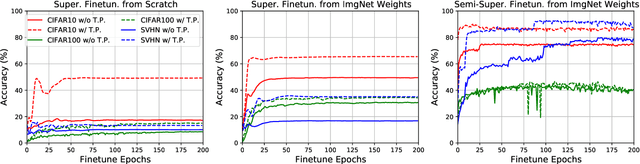
Semi-supervised learning (SSL) addresses the lack of labeled data by exploiting large unlabeled data through pseudolabeling. However, in the extremely low-label regime, pseudo labels could be incorrect, a.k.a. the confirmation bias, and the pseudo labels will in turn harm the network training. Recent studies combined finetuning (FT) from pretrained weights with SSL to mitigate the challenges and claimed superior results in the low-label regime. In this work, we first show that the better pretrained weights brought in by FT account for the state-of-the-art performance, and importantly that they are universally helpful to off-the-shelf semi-supervised learners. We further argue that direct finetuning from pretrained weights is suboptimal due to covariate shift and propose a contrastive target pretraining step to adapt model weights towards target dataset. We carried out extensive experiments on both classification and segmentation tasks by doing target pretraining then followed by semi-supervised finetuning. The promising results validate the efficacy of target pretraining for SSL, in particular in the low-label regime.
Open-Set Semi-Supervised Learning for 3D Point Cloud Understanding
May 02, 2022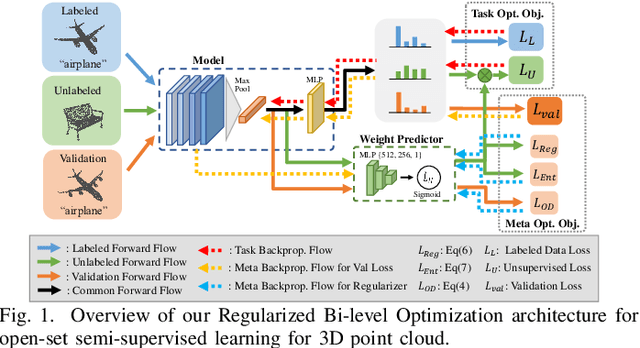
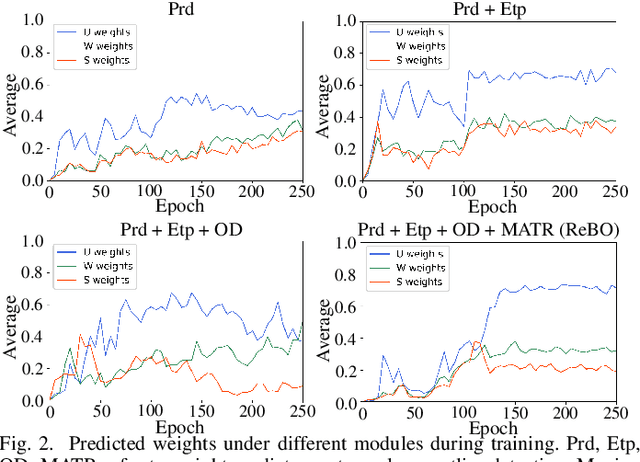
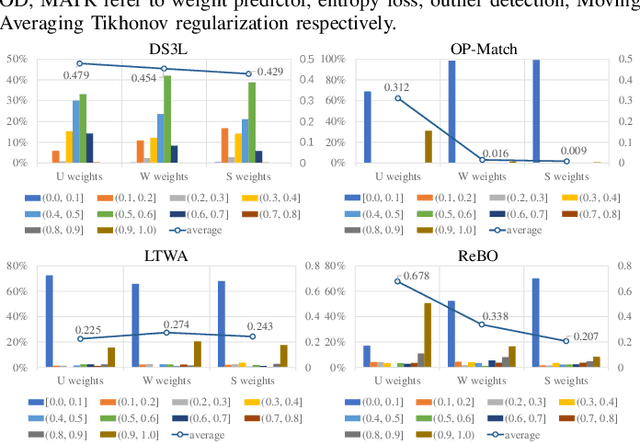
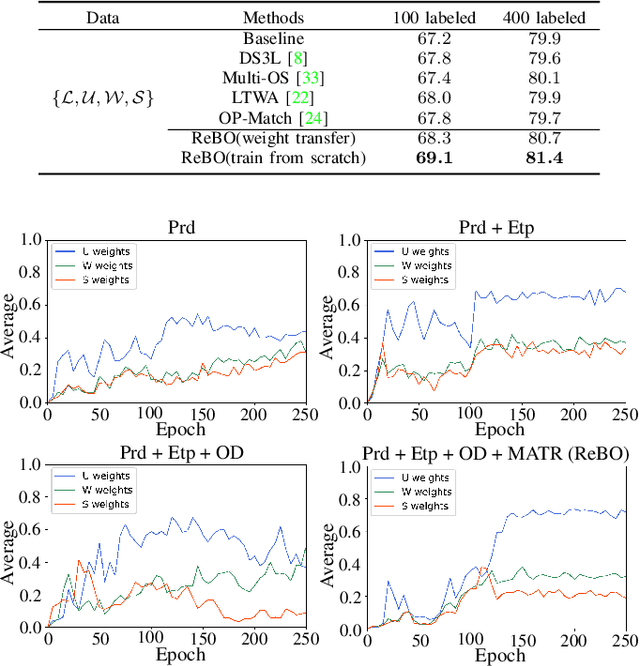
Semantic understanding of 3D point cloud relies on learning models with massively annotated data, which, in many cases, are expensive or difficult to collect. This has led to an emerging research interest in semi-supervised learning (SSL) for 3D point cloud. It is commonly assumed in SSL that the unlabeled data are drawn from the same distribution as that of the labeled ones; This assumption, however, rarely holds true in realistic environments. Blindly using out-of-distribution (OOD) unlabeled data could harm SSL performance. In this work, we propose to selectively utilize unlabeled data through sample weighting, so that only conducive unlabeled data would be prioritized. To estimate the weights, we adopt a bi-level optimization framework which iteratively optimizes a metaobjective on a held-out validation set and a task-objective on a training set. Faced with the instability of efficient bi-level optimizers, we further propose three regularization techniques to enhance the training stability. Extensive experiments on 3D point cloud classification and segmentation tasks verify the effectiveness of our proposed method. We also demonstrate the feasibility of a more efficient training strategy.
On Automatic Data Augmentation for 3D Point Cloud Classification
Dec 18, 2021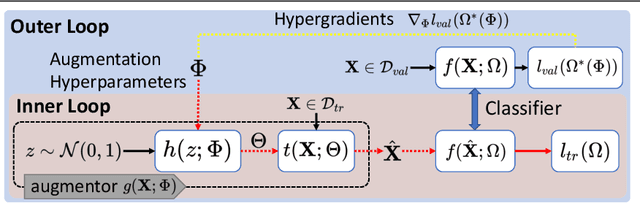
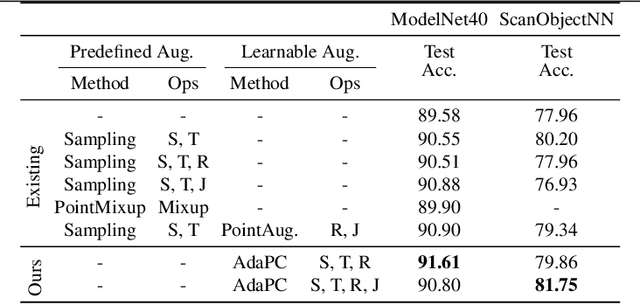


Data augmentation is an important technique to reduce overfitting and improve learning performance, but existing works on data augmentation for 3D point cloud data are based on heuristics. In this work, we instead propose to automatically learn a data augmentation strategy using bilevel optimization. An augmentor is designed in a similar fashion to a conditional generator and is optimized by minimizing a base model's loss on a validation set when the augmented input is used for training the model. This formulation provides a more principled way to learn data augmentation on 3D point clouds. We evaluate our approach on standard point cloud classification tasks and a more challenging setting with pose misalignment between training and validation/test sets. The proposed strategy achieves competitive performance on both tasks and we provide further insight into the augmentor's ability to learn the validation set distribution.
An LSTM Approach to Temporal 3D Object Detection in LiDAR Point Clouds
Jul 24, 2020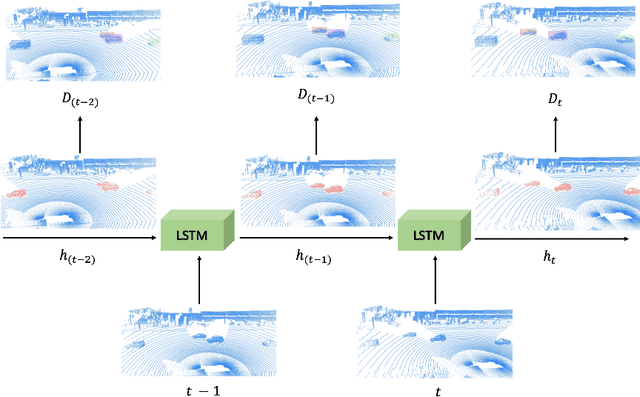
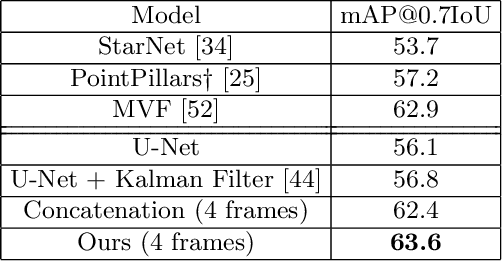
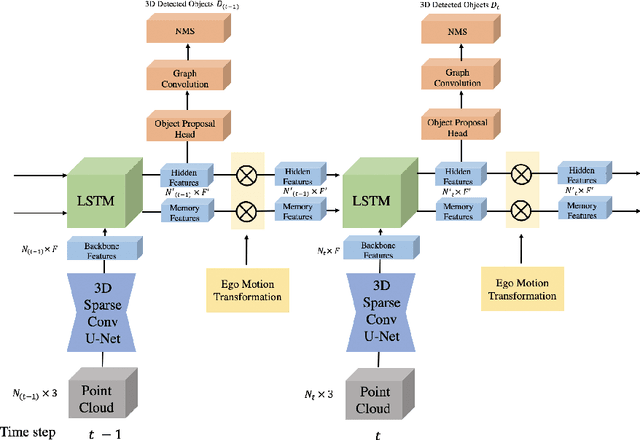
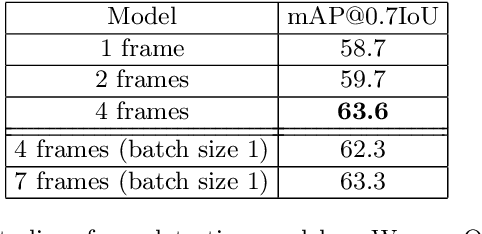
Detecting objects in 3D LiDAR data is a core technology for autonomous driving and other robotics applications. Although LiDAR data is acquired over time, most of the 3D object detection algorithms propose object bounding boxes independently for each frame and neglect the useful information available in the temporal domain. To address this problem, in this paper we propose a sparse LSTM-based multi-frame 3d object detection algorithm. We use a U-Net style 3D sparse convolution network to extract features for each frame's LiDAR point-cloud. These features are fed to the LSTM module together with the hidden and memory features from last frame to predict the 3d objects in the current frame as well as hidden and memory features that are passed to the next frame. Experiments on the Waymo Open Dataset show that our algorithm outperforms the traditional frame by frame approach by 7.5% mAP@0.7 and other multi-frame approaches by 1.2% while using less memory and computation per frame. To the best of our knowledge, this is the first work to use an LSTM for 3D object detection in sparse point clouds.