 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Calibrated Indoor Tracking from Backscatter Fiducials under NLOS Transmitter Illumination
Jun 15, 2026This paper studies indoor tracking from wall-mounted backscatter fiducials in corridor segments outside direct transmitter illumination. In the measured setup, the transmitter-to-fiducial links are NLOS, whereas the fiducial-to-receiver links along the corridor are largely LOS. The main challenge is that the effective fiducial response is deployment-dependent, so a fixed calibrated link budget is not reliable. We therefore use a grid-based penalized-likelihood tracker that profiles the receiver path, a fitted log-distance slope parameter, and fiducial-specific offsets directly from received powers. The resulting paths can then be reused as surrogate calibration coordinates for residual-map correction, while the same correction with measured calibration coordinates is reported only as a reference. On a short four-fiducial corridor segment, the profiled dual-band tracker gives a 0.52 m median error without measured calibration coordinates, and surrogate residual correction improves this to 0.46 m. With measured calibration coordinates, the same correction and a RADAR-style fingerprint reference both reach 0.31 m. The main remaining limitation is therefore the quality of the surrogate calibration paths rather than the structured observation model itself.
Backscatter Assisted Indoor NLOS Positioning
Jun 15, 2026Passive backscatter devices (BDs) can enable indoor non-line-of-sight (NLOS) positioning by serving as virtual anchors whose Doppler-separated signatures are observable in standard channel estimates. This paper studies continuous user-equipment (UE) tracking in corridor environments using a noncoherent power-domain formulation that avoids BD phase synchronization and remains robust to residual carrier offsets and strong multipath. The BD-dependent measurements are modeled by a log-distance law with unknown BD-specific offsets, which allows passive asynchronous devices to be used as anchors without transmit-power calibration. Based on this model, we develop a corridor-constrained maximum a posteriori (MAP) tracker with motion regularization and Huber-robust estimation. In ray-tracing-inspired simulations, the method achieves median positioning errors of 0.23--0.27 m with 90th-percentile errors below 0.45 m. In office-corridor measurements with four passive BDs at 866 MHz, it attains an aggregated median error of 0.505 m and outperforms a simple weighted-average baseline. The results show that passive asynchronous BDs can provide practical sub-meter indoor NLOS tracking while remaining compatible with existing channel-estimation pipelines and energy-autonomous BD deployments.
Unlocking Cognitive Capabilities and Analyzing the Perception-Logic Trade-off
Feb 27, 2026Recent advancements in Multimodal Large Language Models (MLLMs) pursue omni-perception capabilities, yet integrating robust sensory grounding with complex reasoning remains a challenge, particularly for underrepresented regions. In this report, we introduce the research preview of MERaLiON2-Omni (Alpha), a 10B-parameter multilingual omni-perception tailored for Southeast Asia (SEA). We present a progressive training pipeline that explicitly decouples and then integrates "System 1" (Perception) and "System 2" (Reasoning) capabilities. First, we establish a robust Perception Backbone by aligning region-specific audio-visual cues (e.g., Singlish code-switching, local cultural landmarks) with a multilingual LLM through orthogonal modality adaptation. Second, to inject cognitive capabilities without large-scale supervision, we propose a cost-effective Generate-Judge-Refine pipeline. By utilizing a Super-LLM to filter hallucinations and resolve conflicts via a consensus mechanism, we synthesize high-quality silver data that transfers textual Chain-of-Thought reasoning to multimodal scenarios. Comprehensive evaluation on our newly introduced SEA-Omni Benchmark Suite reveals an Efficiency-Stability Paradox: while reasoning acts as a non-linear amplifier for abstract tasks (boosting mathematical and instruction-following performance significantly), it introduces instability in low-level sensory processing. Specifically, we identify Temporal Drift in long-context audio, where extended reasoning desynchronizes the model from acoustic timestamps, and Visual Over-interpretation, where logic overrides pixel-level reality. This report details the architecture, the data-efficient training recipe, and a diagnostic analysis of the trade-offs between robust perception and structured reasoning.
SPA-Cache: Singular Proxies for Adaptive Caching in Diffusion Language Models
Jan 30, 2026While Diffusion Language Models (DLMs) offer a flexible, arbitrary-order alternative to the autoregressive paradigm, their non-causal nature precludes standard KV caching, forcing costly hidden state recomputation at every decoding step. Existing DLM caching approaches reduce this cost by selective hidden state updates; however, they are still limited by (i) costly token-wise update identification heuristics and (ii) rigid, uniform budget allocation that fails to account for heterogeneous hidden state dynamics. To address these challenges, we present SPA-Cache that jointly optimizes update identification and budget allocation in DLM cache. First, we derive a low-dimensional singular proxy that enables the identification of update-critical tokens in a low-dimensional subspace, substantially reducing the overhead of update identification. Second, we introduce an adaptive strategy that allocates fewer updates to stable layers without degrading generation quality. Together, these contributions significantly improve the efficiency of DLMs, yielding up to an $8\times$ throughput improvement over vanilla decoding and a $2$--$4\times$ speedup over existing caching baselines.
Patch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs
Oct 02, 2025
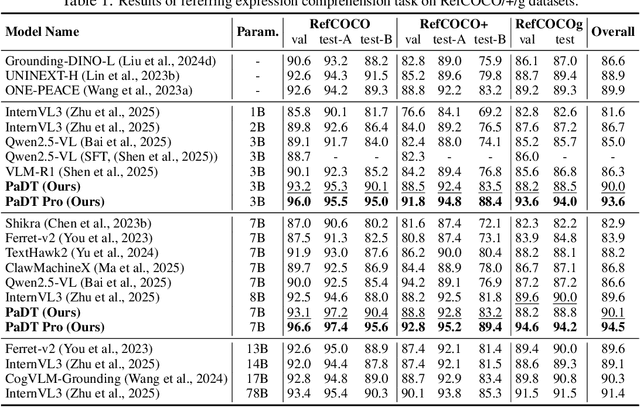

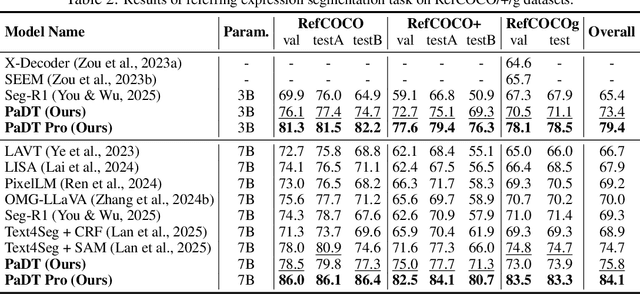
Multimodal large language models (MLLMs) have advanced rapidly in recent years. However, existing approaches for vision tasks often rely on indirect representations, such as generating coordinates as text for detection, which limits performance and prevents dense prediction tasks like segmentation. To overcome these challenges, we introduce Patch-as-Decodable Token (PaDT), a unified paradigm that enables MLLMs to directly generate both textual and diverse visual outputs. Central to PaDT are Visual Reference Tokens (VRTs), derived from visual patch embeddings of query images and interleaved seamlessly with LLM's output textual tokens. A lightweight decoder then transforms LLM's outputs into detection, segmentation, and grounding predictions. Unlike prior methods, PaDT processes VRTs independently at each forward pass and dynamically expands the embedding table, thus improving localization and differentiation among similar objects. We further tailor a training strategy for PaDT by randomly selecting VRTs for supervised fine-tuning and introducing a robust per-token cross-entropy loss. Our empirical studies across four visual perception and understanding tasks suggest PaDT consistently achieving state-of-the-art performance, even compared with significantly larger MLLM models. The code is available at https://github.com/Gorilla-Lab-SCUT/PaDT.
Box-Level Class-Balanced Sampling for Active Object Detection
Aug 25, 2025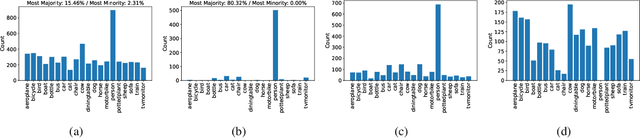
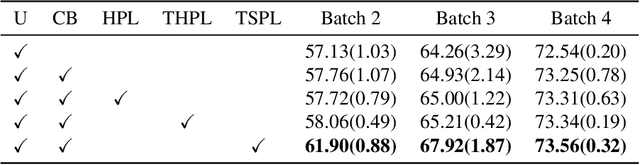

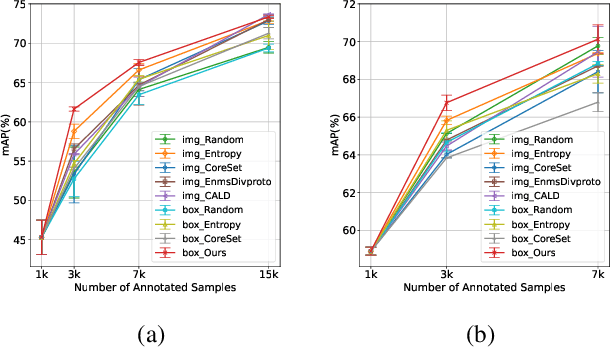
Training deep object detectors demands expensive bounding box annotation. Active learning (AL) is a promising technique to alleviate the annotation burden. Performing AL at box-level for object detection, i.e., selecting the most informative boxes to label and supplementing the sparsely-labelled image with pseudo labels, has been shown to be more cost-effective than selecting and labelling the entire image. In box-level AL for object detection, we observe that models at early stage can only perform well on majority classes, making the pseudo labels severely class-imbalanced. We propose a class-balanced sampling strategy to select more objects from minority classes for labelling, so as to make the final training data, \ie, ground truth labels obtained by AL and pseudo labels, more class-balanced to train a better model. We also propose a task-aware soft pseudo labelling strategy to increase the accuracy of pseudo labels. We evaluate our method on public benchmarking datasets and show that our method achieves state-of-the-art performance.
AD-FM: Multimodal LLMs for Anomaly Detection via Multi-Stage Reasoning and Fine-Grained Reward Optimization
Aug 06, 2025



While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities across diverse domains, their application to specialized anomaly detection (AD) remains constrained by domain adaptation challenges. Existing Group Relative Policy Optimization (GRPO) based approaches suffer from two critical limitations: inadequate training data utilization when models produce uniform responses, and insufficient supervision over reasoning processes that encourage immediate binary decisions without deliberative analysis. We propose a comprehensive framework addressing these limitations through two synergistic innovations. First, we introduce a multi-stage deliberative reasoning process that guides models from region identification to focused examination, generating diverse response patterns essential for GRPO optimization while enabling structured supervision over analytical workflows. Second, we develop a fine-grained reward mechanism incorporating classification accuracy and localization supervision, transforming binary feedback into continuous signals that distinguish genuine analytical insight from spurious correctness. Comprehensive evaluation across multiple industrial datasets demonstrates substantial performance improvements in adapting general vision-language models to specialized anomaly detection. Our method achieves superior accuracy with efficient adaptation of existing annotations, effectively bridging the gap between general-purpose MLLM capabilities and the fine-grained visual discrimination required for detecting subtle manufacturing defects and structural irregularities.
MLLM-Guided VLM Fine-Tuning with Joint Inference for Zero-Shot Composed Image Retrieval
May 26, 2025Existing Zero-Shot Composed Image Retrieval (ZS-CIR) methods typically train adapters that convert reference images into pseudo-text tokens, which are concatenated with the modifying text and processed by frozen text encoders in pretrained VLMs or LLMs. While this design leverages the strengths of large pretrained models, it only supervises the adapter to produce encoder-compatible tokens that loosely preserve visual semantics. Crucially, it does not directly optimize the composed query representation to capture the full intent of the composition or to align with the target semantics, thereby limiting retrieval performance, particularly in cases involving fine-grained or complex visual transformations. To address this problem, we propose MLLM-Guided VLM Fine-Tuning with Joint Inference (MVFT-JI), a novel approach that leverages a pretrained multimodal large language model (MLLM) to construct two complementary training tasks using only unlabeled images: target text retrieval taskand text-to-image retrieval task. By jointly optimizing these tasks, our method enables the VLM to inherently acquire robust compositional retrieval capabilities, supported by the provided theoretical justifications and empirical validation. Furthermore, during inference, we further prompt the MLLM to generate target texts from composed queries and compute retrieval scores by integrating similarities between (i) the composed query and candidate images, and (ii) the MLLM-generated target text and candidate images. This strategy effectively combines the VLM's semantic alignment strengths with the MLLM's reasoning capabilities.
VORTA: Efficient Video Diffusion via Routing Sparse Attention
May 24, 2025



Video Diffusion Transformers (VDiTs) have achieved remarkable progress in high-quality video generation, but remain computationally expensive due to the quadratic complexity of attention over high-dimensional video sequences. Recent attention acceleration methods leverage the sparsity of attention patterns to improve efficiency; however, they often overlook inefficiencies of redundant long-range interactions. To address this problem, we propose \textbf{VORTA}, an acceleration framework with two novel components: 1) a sparse attention mechanism that efficiently captures long-range dependencies, and 2) a routing strategy that adaptively replaces full 3D attention with specialized sparse attention variants throughout the sampling process. It achieves a $1.76\times$ end-to-end speedup without quality loss on VBench. Furthermore, VORTA can seamlessly integrate with various other acceleration methods, such as caching and step distillation, reaching up to $14.41\times$ speedup with negligible performance degradation. VORTA demonstrates its efficiency and enhances the practicality of VDiTs in real-world settings.
Robust Distribution Alignment for Industrial Anomaly Detection under Distribution Shift
Mar 19, 2025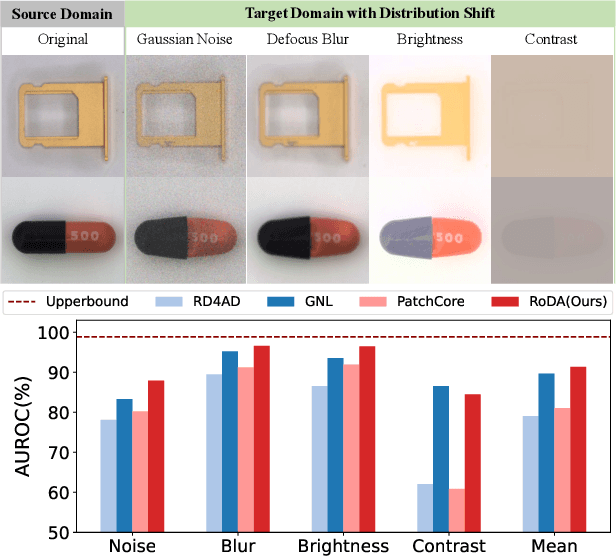
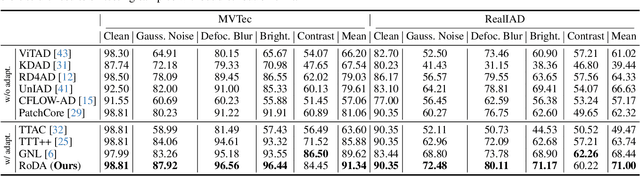
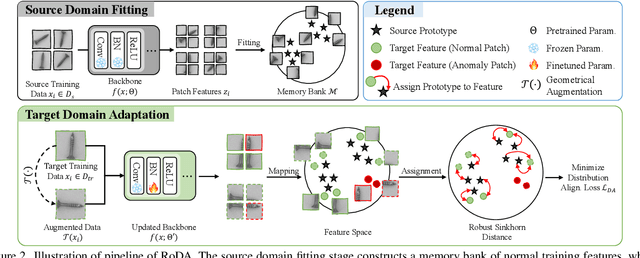

Anomaly detection plays a crucial role in quality control for industrial applications. However, ensuring robustness under unseen domain shifts such as lighting variations or sensor drift remains a significant challenge. Existing methods attempt to address domain shifts by training generalizable models but often rely on prior knowledge of target distributions and can hardly generalise to backbones designed for other data modalities. To overcome these limitations, we build upon memory-bank-based anomaly detection methods, optimizing a robust Sinkhorn distance on limited target training data to enhance generalization to unseen target domains. We evaluate the effectiveness on both 2D and 3D anomaly detection benchmarks with simulated distribution shifts. Our proposed method demonstrates superior results compared with state-of-the-art anomaly detection and domain adaptation methods.