 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimeKG-CL: A Continual Graph Learning Benchmark on Evolving Biomedical Knowledge Graphs
May 11, 2026Biomedical knowledge graphs underwrite drug repurposing and clinical decision support, yet the upstream ontologies they depend on update on independent cycles that add millions of edges and deprecate hundreds of thousands more between releases. Yet existing continual graph learning has been studied almost exclusively on synthetic random splits of static, generic KGs, a regime that cannot reproduce the asynchronous, structured evolution real biomedical KGs undergo. To this end, we introduce PrimeKG-CL, a CGL benchmark built from nine authoritative biomedical databases (129K+ nodes, 8.1M+ edges, 10 node types, 30 relation types) with two genuine temporal snapshots (June 2021, July 2023; 5.83M edges added, 889K removed, 7.21M persistent), 10 entity-type-grouped tasks, multimodal node features, and a per-task persistent/added/removed test stratification. On three tasks (biomedical relationship prediction, entity classification, KGQA), we evaluate six CL strategies across four KGE decoders, plus LKGE, an LLM-RAG agent, and CMKL. We find that decoder choice and continual learning strategy interact strongly: no single strategy performs best across all decoders, and mismatched combinations can significantly degrade performance. Moreover, only DistMult exhibits a clear separation between persistent and deprecated knowledge, indicating that standard metrics conflate retention of still-valid facts with failure to forget outdated ones; this effect is absent under RotatE. In addition, multimodal features improve entity-level tasks by up to 60%, and a recent CKGE framework (IncDE) failed to scale to our 5.67M-triple base task across five attempts up to 350GB RAM. Data, pipeline, baselines, and the stratified split are released openly. Dataset:huggingface.co/datasets/yradwan147/PrimeKGCL|Code:github.com/yradwan147/primekg-cl-neurips2026
Bridging Sequence and Graph Structure for Epigenetic Age Prediction
May 11, 2026Epigenetic clocks based on DNA methylation have emerged as powerful tools for estimating biological age, with broad applications in aging research, age-related disease studies, and longevity science. Despite advances across machine learning approaches to epigenetic age prediction, spanning penalised linear regression, deep feedforward networks, residual architectures, and graph neural networks, no existing method jointly models co-methylation graph structure and site-specific DNA sequence context within a unified framework. We propose a unified sequence--graph integration framework for epigenetic age prediction that addresses this gap, integrating eight-dimensional DNA sequence statistical features through a lightweight gated modulation mechanism that adaptively scales each site's methylation signal according to its sequence-determined biological relevance prior to graph convolution. Evaluated on 3,707 blood methylation samples against a comprehensive set of baselines, our method achieves a test MAE of 3.149 years, a 12.8\% improvement over the strongest graph-based baseline. Biologically informed statistical features outperform CNN-based sequence encoding, demonstrating that handcrafted sequence features are more effective than end-to-end learned representations in this data regime. Post-hoc interpretability analysis identifies CpG density and local adenine frequency as features with age-dependent importance shifts, consistent with known mechanisms of age-related hypermethylation at CpG-dense promoter regions. Our code is at https://github.com/yaoli2022/graphage-seq.
MM-DeepResearch: A Simple and Effective Multimodal Agentic Search Baseline
Mar 01, 2026We aim to develop a multimodal research agent capable of explicit reasoning and planning, multi-tool invocation, and cross-modal information synthesis, enabling it to conduct deep research tasks. However, we observe three main challenges in developing such agents: (1) scarcity of search-intensive multimodal QA data, (2) lack of effective search trajectories, and (3) prohibitive cost of training with online search APIs. To tackle them, we first propose Hyper-Search, a hypergraph-based QA generation method that models and connects visual and textual nodes within and across modalities, enabling to generate search-intensive multimodal QA pairs that require invoking various search tools to solve. Second, we introduce DR-TTS, which first decomposes search-involved tasks into several categories according to search tool types, and respectively optimize specialized search tool experts for each tool. It then recomposes tool experts to jointly explore search trajectories via tree search, producing trajectories that successfully solve complex tasks using various search tools. Third, we build an offline search engine supporting multiple search tools, enabling agentic reinforcement learning without using costly online search APIs. With the three designs, we develop MM-DeepResearch, a powerful multimodal deep research agent, and extensive results shows its superiority across benchmarks. Code is available at https://github.com/HJYao00/MM-DeepResearch
Recycling Failures: Salvaging Exploration in RLVR via Fine-Grained Off-Policy Guidance
Feb 27, 2026Reinforcement Learning from Verifiable Rewards (RLVR) has emerged as a powerful paradigm for enhancing the complex reasoning capabilities of Large Reasoning Models. However, standard outcome-based supervision suffers from a critical limitation that penalizes trajectories that are largely correct but fail due to several missteps as heavily as completely erroneous ones. This coarse feedback signal causes the model to discard valuable largely correct rollouts, leading to a degradation in rollout diversity that prematurely narrows the exploration space. Process Reward Models have demonstrated efficacy in providing reliable step-wise verification for test-time scaling, naively integrating these signals into RLVR as dense rewards proves ineffective.Prior methods attempt to introduce off-policy guided whole-trajectory replacement that often outside the policy model's distribution, but still fail to utilize the largely correct rollouts generated by the model itself and thus do not effectively mitigate the narrowing of the exploration space. To address these issues, we propose SCOPE (Step-wise Correction for On-Policy Exploration), a novel framework that utilizes Process Reward Models to pinpoint the first erroneous step in suboptimal rollouts and applies fine-grained, step-wise off-policy rectification. By applying precise refinement on partially correct rollout, our method effectively salvages partially correct trajectories and increases diversity score by 13.5%, thereby sustaining a broad exploration space. Extensive experiments demonstrate that our approach establishes new state-of-the-art results, achieving an average accuracy of 46.6% on math reasoning and exhibiting robust generalization with 53.4% accuracy on out-of-distribution reasoning tasks.
BadCLIP++: Stealthy and Persistent Backdoors in Multimodal Contrastive Learning
Feb 19, 2026Research on backdoor attacks against multimodal contrastive learning models faces two key challenges: stealthiness and persistence. Existing methods often fail under strong detection or continuous fine-tuning, largely due to (1) cross-modal inconsistency that exposes trigger patterns and (2) gradient dilution at low poisoning rates that accelerates backdoor forgetting. These coupled causes remain insufficiently modeled and addressed. We propose BadCLIP++, a unified framework that tackles both challenges. For stealthiness, we introduce a semantic-fusion QR micro-trigger that embeds imperceptible patterns near task-relevant regions, preserving clean-data statistics while producing compact trigger distributions. We further apply target-aligned subset selection to strengthen signals at low injection rates. For persistence, we stabilize trigger embeddings via radius shrinkage and centroid alignment, and stabilize model parameters through curvature control and elastic weight consolidation, maintaining solutions within a low-curvature wide basin resistant to fine-tuning. We also provide the first theoretical analysis showing that, within a trust region, gradients from clean fine-tuning and backdoor objectives are co-directional, yielding a non-increasing upper bound on attack success degradation. Experiments demonstrate that with only 0.3% poisoning, BadCLIP++ achieves 99.99% attack success rate (ASR) in digital settings, surpassing baselines by 11.4 points. Across nineteen defenses, ASR remains above 99.90% with less than 0.8% drop in clean accuracy. The method further attains 65.03% success in physical attacks and shows robustness against watermark removal defenses.
R1-SyntheticVL: Is Synthetic Data from Generative Models Ready for Multimodal Large Language Model?
Feb 03, 2026In this work, we aim to develop effective data synthesis techniques that autonomously synthesize multimodal training data for enhancing MLLMs in solving complex real-world tasks. To this end, we propose Collective Adversarial Data Synthesis (CADS), a novel and general approach to synthesize high-quality, diverse and challenging multimodal data for MLLMs. The core idea of CADS is to leverage collective intelligence to ensure high-quality and diverse generation, while exploring adversarial learning to synthesize challenging samples for effectively driving model improvement. Specifically, CADS operates with two cyclic phases, i.e., Collective Adversarial Data Generation (CAD-Generate) and Collective Adversarial Data Judgment (CAD-Judge). CAD-Generate leverages collective knowledge to jointly generate new and diverse multimodal data, while CAD-Judge collaboratively assesses the quality of synthesized data. In addition, CADS introduces an Adversarial Context Optimization mechanism to optimize the generation context to encourage challenging and high-value data generation. With CADS, we construct MMSynthetic-20K and train our model R1-SyntheticVL, which demonstrates superior performance on various benchmarks.
Improving large language models with concept-aware fine-tuning
Jun 09, 2025Large language models (LLMs) have become the cornerstone of modern AI. However, the existing paradigm of next-token prediction fundamentally limits their ability to form coherent, high-level concepts, making it a critical barrier to human-like understanding and reasoning. Take the phrase "ribonucleic acid" as an example: an LLM will first decompose it into tokens, i.e., artificial text fragments ("rib", "on", ...), then learn each token sequentially, rather than grasping the phrase as a unified, coherent semantic entity. This fragmented representation hinders deeper conceptual understanding and, ultimately, the development of truly intelligent systems. In response, we introduce Concept-Aware Fine-Tuning (CAFT), a novel multi-token training method that redefines how LLMs are fine-tuned. By enabling the learning of sequences that span multiple tokens, this method fosters stronger concept-aware learning. Our experiments demonstrate significant improvements compared to conventional next-token finetuning methods across diverse tasks, including traditional applications like text summarization and domain-specific ones like de novo protein design. Multi-token prediction was previously only possible in the prohibitively expensive pretraining phase; CAFT, to our knowledge, is the first to bring the multi-token setting to the post-training phase, thus effectively democratizing its benefits for the broader community of practitioners and researchers. Finally, the unexpected effectiveness of our proposed method suggests wider implications for the machine learning research community. All code and data are available at https://github.com/michaelchen-lab/caft-llm
SIGMA: Refining Large Language Model Reasoning via Sibling-Guided Monte Carlo Augmentation
Jun 06, 2025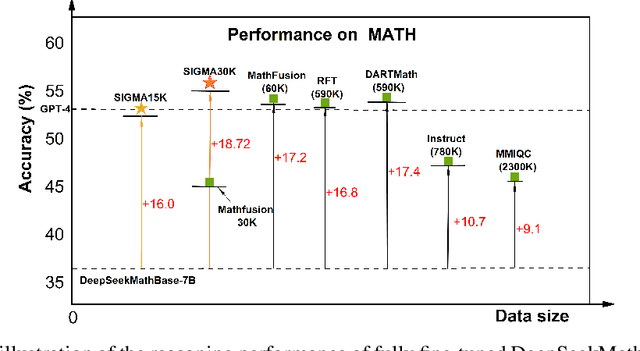



Enhancing large language models by simply scaling up datasets has begun to yield diminishing returns, shifting the spotlight to data quality. Monte Carlo Tree Search (MCTS) has emerged as a powerful technique for generating high-quality chain-of-thought data, yet conventional approaches typically retain only the top-scoring trajectory from the search tree, discarding sibling nodes that often contain valuable partial insights, recurrent error patterns, and alternative reasoning strategies. This unconditional rejection of non-optimal reasoning branches may waste vast amounts of informative data in the whole search tree. We propose SIGMA (Sibling Guided Monte Carlo Augmentation), a novel framework that reintegrates these discarded sibling nodes to refine LLM reasoning. SIGMA forges semantic links among sibling nodes along each search path and applies a two-stage refinement: a critique model identifies overlooked strengths and weaknesses across the sibling set, and a revision model conducts text-based backpropagation to refine the top-scoring trajectory in light of this comparative feedback. By recovering and amplifying the underutilized but valuable signals from non-optimal reasoning branches, SIGMA substantially improves reasoning trajectories. On the challenging MATH benchmark, our SIGMA-tuned 7B model achieves 54.92% accuracy using only 30K samples, outperforming state-of-the-art models trained on 590K samples. This result highlights that our sibling-guided optimization not only significantly reduces data usage but also significantly boosts LLM reasoning.
Multimodal Reasoning Agent for Zero-Shot Composed Image Retrieval
May 26, 2025Zero-Shot Composed Image Retrieval (ZS-CIR) aims to retrieve target images given a compositional query, consisting of a reference image and a modifying text-without relying on annotated training data. Existing approaches often generate a synthetic target text using large language models (LLMs) to serve as an intermediate anchor between the compositional query and the target image. Models are then trained to align the compositional query with the generated text, and separately align images with their corresponding texts using contrastive learning. However, this reliance on intermediate text introduces error propagation, as inaccuracies in query-to-text and text-to-image mappings accumulate, ultimately degrading retrieval performance. To address these problems, we propose a novel framework by employing a Multimodal Reasoning Agent (MRA) for ZS-CIR. MRA eliminates the dependence on textual intermediaries by directly constructing triplets, <reference image, modification text, target image>, using only unlabeled image data. By training on these synthetic triplets, our model learns to capture the relationships between compositional queries and candidate images directly. Extensive experiments on three standard CIR benchmarks demonstrate the effectiveness of our approach. On the FashionIQ dataset, our method improves Average R@10 by at least 7.5\% over existing baselines; on CIRR, it boosts R@1 by 9.6\%; and on CIRCO, it increases mAP@5 by 9.5\%.
R1-ShareVL: Incentivizing Reasoning Capability of Multimodal Large Language Models via Share-GRPO
May 22, 2025In this work, we aim to incentivize the reasoning ability of Multimodal Large Language Models (MLLMs) via reinforcement learning (RL) and develop an effective approach that mitigates the sparse reward and advantage vanishing issues during RL. To this end, we propose Share-GRPO, a novel RL approach that tackle these issues by exploring and sharing diverse reasoning trajectories over expanded question space. Specifically, Share-GRPO first expands the question space for a given question via data transformation techniques, and then encourages MLLM to effectively explore diverse reasoning trajectories over the expanded question space and shares the discovered reasoning trajectories across the expanded questions during RL. In addition, Share-GRPO also shares reward information during advantage computation, which estimates solution advantages hierarchically across and within question variants, allowing more accurate estimation of relative advantages and improving the stability of policy training. Extensive evaluations over six widely-used reasoning benchmarks showcase the superior performance of our method. Code will be available at https://github.com/HJYao00/R1-ShareVL.