 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\textbf{AGT$^{AO}$}$: Robust and Stabilized LLM Unlearning via Adversarial Gating Training with Adaptive Orthogonality
Feb 02, 2026While Large Language Models (LLMs) have achieved remarkable capabilities, they unintentionally memorize sensitive data, posing critical privacy and security risks. Machine unlearning is pivotal for mitigating these risks, yet existing paradigms face a fundamental dilemma: aggressive unlearning often induces catastrophic forgetting that degrades model utility, whereas conservative strategies risk superficial forgetting, leaving models vulnerable to adversarial recovery. To address this trade-off, we propose $\textbf{AGT$^{AO}$}$ (Adversarial Gating Training with Adaptive Orthogonality), a unified framework designed to reconcile robust erasure with utility preservation. Specifically, our approach introduces $\textbf{Adaptive Orthogonality (AO)}$ to dynamically mitigate geometric gradient conflicts between forgetting and retention objectives, thereby minimizing unintended knowledge degradation. Concurrently, $\textbf{Adversarial Gating Training (AGT)}$ formulates unlearning as a latent-space min-max game, employing a curriculum-based gating mechanism to simulate and counter internal recovery attempts. Extensive experiments demonstrate that $\textbf{AGT$^{AO}$}$ achieves a superior trade-off between unlearning efficacy (KUR $\approx$ 0.01) and model utility (MMLU 58.30). Code is available at https://github.com/TiezMind/AGT-unlearning.
GeoLaux: A Benchmark for Evaluating MLLMs' Geometry Performance on Long-Step Problems Requiring Auxiliary Lines
Aug 08, 2025Geometry problem solving (GPS) requires models to master diagram comprehension, logical reasoning, knowledge application, numerical computation, and auxiliary line construction. This presents a significant challenge for Multimodal Large Language Models (MLLMs). However, existing benchmarks for evaluating MLLM geometry skills overlook auxiliary line construction and lack fine-grained process evaluation, making them insufficient for assessing MLLMs' long-step reasoning abilities. To bridge these gaps, we present the GeoLaux benchmark, comprising 2,186 geometry problems, incorporating both calculation and proving questions. Notably, the problems require an average of 6.51 reasoning steps, with a maximum of 24 steps, and 41.8% of them need auxiliary line construction. Building on the dataset, we design a novel five-dimensional evaluation strategy assessing answer correctness, process correctness, process quality, auxiliary line impact, and error causes. Extensive experiments on 13 leading MLLMs (including thinking models and non-thinking models) yield three pivotal findings: First, models exhibit substantial performance degradation in extended reasoning steps (nine models demonstrate over 50% performance drop). Second, compared to calculation problems, MLLMs tend to take shortcuts when solving proving problems. Third, models lack auxiliary line awareness, and enhancing this capability proves particularly beneficial for overall geometry reasoning improvement. These findings establish GeoLaux as both a benchmark for evaluating MLLMs' long-step geometric reasoning with auxiliary lines and a guide for capability advancement. Our dataset and code are included in supplementary materials and will be released.
PhysReason: A Comprehensive Benchmark towards Physics-Based Reasoning
Feb 17, 2025
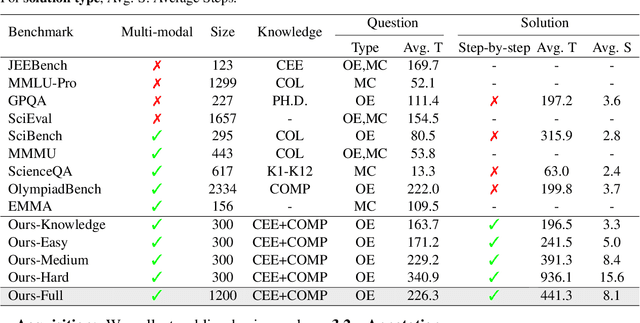


Large language models demonstrate remarkable capabilities across various domains, especially mathematics and logic reasoning. However, current evaluations overlook physics-based reasoning - a complex task requiring physics theorems and constraints. We present PhysReason, a 1,200-problem benchmark comprising knowledge-based (25%) and reasoning-based (75%) problems, where the latter are divided into three difficulty levels (easy, medium, hard). Notably, problems require an average of 8.1 solution steps, with hard requiring 15.6, reflecting the complexity of physics-based reasoning. We propose the Physics Solution Auto Scoring Framework, incorporating efficient answer-level and comprehensive step-level evaluations. Top-performing models like Deepseek-R1, Gemini-2.0-Flash-Thinking, and o3-mini-high achieve less than 60% on answer-level evaluation, with performance dropping from knowledge questions (75.11%) to hard problems (31.95%). Through step-level evaluation, we identified four key bottlenecks: Physics Theorem Application, Physics Process Understanding, Calculation, and Physics Condition Analysis. These findings position PhysReason as a novel and comprehensive benchmark for evaluating physics-based reasoning capabilities in large language models. Our code and data will be published at https:/dxzxy12138.github.io/PhysReason.
DiagramQG: A Dataset for Generating Concept-Focused Questions from Diagrams
Nov 26, 2024



Visual Question Generation (VQG) has gained significant attention due to its potential in educational applications. However, VQG researches mainly focus on natural images, neglecting diagrams in educational materials used to assess students' conceptual understanding. To address this gap, we introduce DiagramQG, a dataset containing 8,372 diagrams and 19,475 questions across various subjects. DiagramQG introduces concept and target text constraints, guiding the model to generate concept-focused questions for educational purposes. Meanwhile, we present the Hierarchical Knowledge Integration framework for Diagram Question Generation (HKI-DQG) as a strong baseline. This framework obtains multi-scale patches of diagrams and acquires knowledge using a visual language model with frozen parameters. It then integrates knowledge, text constraints and patches to generate concept-focused questions. We evaluate the performance of existing VQG models, open-source and closed-source vision-language models, and HKI-DQG on the DiagramQG dataset. Our HKI-DQG outperform existing methods, demonstrating that it serves as a strong baseline. Furthermore, to assess its generalizability, we apply HKI-DQG to two other VQG datasets of natural images, namely VQG-COCO and K-VQG, achieving state-of-the-art performance.The dataset and code are available at https://dxzxy12138.github.io/diagramqg-home.