 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoFFT: Chain of Foresight-Focus Thought for Visual Language Models
Sep 26, 2025Despite significant advances in Vision Language Models (VLMs), they remain constrained by the complexity and redundancy of visual input. When images contain large amounts of irrelevant information, VLMs are susceptible to interference, thus generating excessive task-irrelevant reasoning processes or even hallucinations. This limitation stems from their inability to discover and process the required regions during reasoning precisely. To address this limitation, we present the Chain of Foresight-Focus Thought (CoFFT), a novel training-free approach that enhances VLMs' visual reasoning by emulating human visual cognition. Each Foresight-Focus Thought consists of three stages: (1) Diverse Sample Generation: generates diverse reasoning samples to explore potential reasoning paths, where each sample contains several reasoning steps; (2) Dual Foresight Decoding: rigorously evaluates these samples based on both visual focus and reasoning progression, adding the first step of optimal sample to the reasoning process; (3) Visual Focus Adjustment: precisely adjust visual focus toward regions most beneficial for future reasoning, before returning to stage (1) to generate subsequent reasoning samples until reaching the final answer. These stages function iteratively, creating an interdependent cycle where reasoning guides visual focus and visual focus informs subsequent reasoning. Empirical results across multiple benchmarks using Qwen2.5-VL, InternVL-2.5, and Llava-Next demonstrate consistent performance improvements of 3.1-5.8\% with controllable increasing computational overhead.
AutoGPS: Automated Geometry Problem Solving via Multimodal Formalization and Deductive Reasoning
May 29, 2025Geometry problem solving presents distinctive challenges in artificial intelligence, requiring exceptional multimodal comprehension and rigorous mathematical reasoning capabilities. Existing approaches typically fall into two categories: neural-based and symbolic-based methods, both of which exhibit limitations in reliability and interpretability. To address this challenge, we propose AutoGPS, a neuro-symbolic collaborative framework that solves geometry problems with concise, reliable, and human-interpretable reasoning processes. Specifically, AutoGPS employs a Multimodal Problem Formalizer (MPF) and a Deductive Symbolic Reasoner (DSR). The MPF utilizes neural cross-modal comprehension to translate geometry problems into structured formal language representations, with feedback from DSR collaboratively. The DSR takes the formalization as input and formulates geometry problem solving as a hypergraph expansion task, executing mathematically rigorous and reliable derivation to produce minimal and human-readable stepwise solutions. Extensive experimental evaluations demonstrate that AutoGPS achieves state-of-the-art performance on benchmark datasets. Furthermore, human stepwise-reasoning evaluation confirms AutoGPS's impressive reliability and interpretability, with 99\% stepwise logical coherence. The project homepage is at https://jayce-ping.github.io/AutoGPS-homepage.
PhysReason: A Comprehensive Benchmark towards Physics-Based Reasoning
Feb 17, 2025
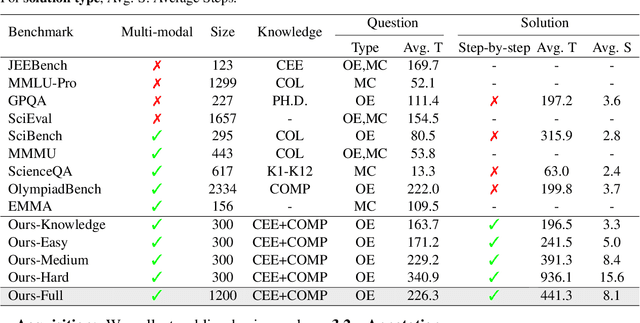


Large language models demonstrate remarkable capabilities across various domains, especially mathematics and logic reasoning. However, current evaluations overlook physics-based reasoning - a complex task requiring physics theorems and constraints. We present PhysReason, a 1,200-problem benchmark comprising knowledge-based (25%) and reasoning-based (75%) problems, where the latter are divided into three difficulty levels (easy, medium, hard). Notably, problems require an average of 8.1 solution steps, with hard requiring 15.6, reflecting the complexity of physics-based reasoning. We propose the Physics Solution Auto Scoring Framework, incorporating efficient answer-level and comprehensive step-level evaluations. Top-performing models like Deepseek-R1, Gemini-2.0-Flash-Thinking, and o3-mini-high achieve less than 60% on answer-level evaluation, with performance dropping from knowledge questions (75.11%) to hard problems (31.95%). Through step-level evaluation, we identified four key bottlenecks: Physics Theorem Application, Physics Process Understanding, Calculation, and Physics Condition Analysis. These findings position PhysReason as a novel and comprehensive benchmark for evaluating physics-based reasoning capabilities in large language models. Our code and data will be published at https:/dxzxy12138.github.io/PhysReason.
OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis
Dec 27, 2024



Graphical User Interface (GUI) agents powered by Vision-Language Models (VLMs) have demonstrated human-like computer control capability. Despite their utility in advancing digital automation, a critical bottleneck persists: collecting high-quality trajectory data for training. Common practices for collecting such data rely on human supervision or synthetic data generation through executing pre-defined tasks, which are either resource-intensive or unable to guarantee data quality. Moreover, these methods suffer from limited data diversity and significant gaps between synthetic data and real-world environments. To address these challenges, we propose OS-Genesis, a novel GUI data synthesis pipeline that reverses the conventional trajectory collection process. Instead of relying on pre-defined tasks, OS-Genesis enables agents first to perceive environments and perform step-wise interactions, then retrospectively derive high-quality tasks to enable trajectory-level exploration. A trajectory reward model is then employed to ensure the quality of the generated trajectories. We demonstrate that training GUI agents with OS-Genesis significantly improves their performance on highly challenging online benchmarks. In-depth analysis further validates OS-Genesis's efficiency and its superior data quality and diversity compared to existing synthesis methods. Our codes, data, and checkpoints are available at \href{https://qiushisun.github.io/OS-Genesis-Home/}{OS-Genesis Homepage}.
ChatGen: Automatic Text-to-Image Generation From FreeStyle Chatting
Nov 26, 2024Despite the significant advancements in text-to-image (T2I) generative models, users often face a trial-and-error challenge in practical scenarios. This challenge arises from the complexity and uncertainty of tedious steps such as crafting suitable prompts, selecting appropriate models, and configuring specific arguments, making users resort to labor-intensive attempts for desired images. This paper proposes Automatic T2I generation, which aims to automate these tedious steps, allowing users to simply describe their needs in a freestyle chatting way. To systematically study this problem, we first introduce ChatGenBench, a novel benchmark designed for Automatic T2I. It features high-quality paired data with diverse freestyle inputs, enabling comprehensive evaluation of automatic T2I models across all steps. Additionally, recognizing Automatic T2I as a complex multi-step reasoning task, we propose ChatGen-Evo, a multi-stage evolution strategy that progressively equips models with essential automation skills. Through extensive evaluation across step-wise accuracy and image quality, ChatGen-Evo significantly enhances performance over various baselines. Our evaluation also uncovers valuable insights for advancing automatic T2I. All our data, code, and models will be available in \url{https://chengyou-jia.github.io/ChatGen-Home}
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Oct 30, 2024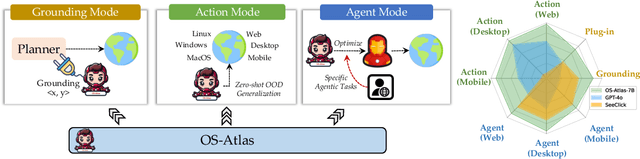
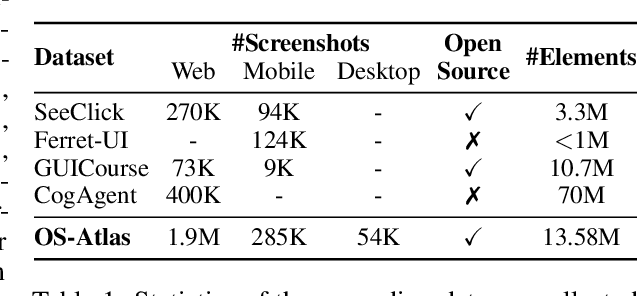
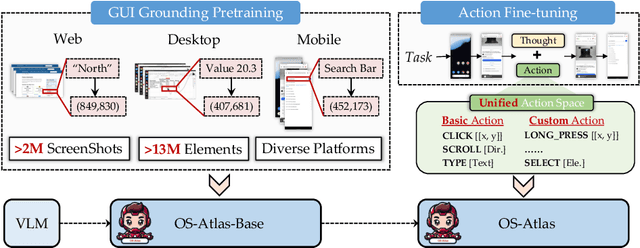
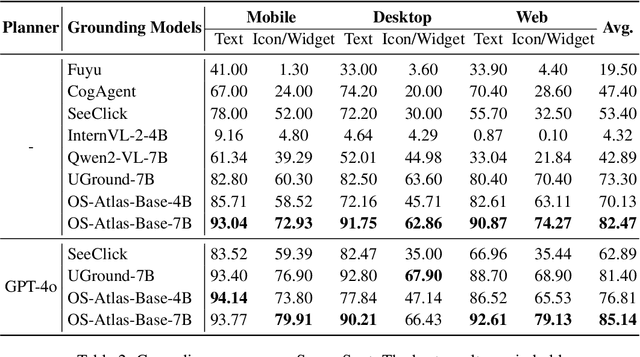
Existing efforts in building GUI agents heavily rely on the availability of robust commercial Vision-Language Models (VLMs) such as GPT-4o and GeminiProVision. Practitioners are often reluctant to use open-source VLMs due to their significant performance lag compared to their closed-source counterparts, particularly in GUI grounding and Out-Of-Distribution (OOD) scenarios. To facilitate future research in this area, we developed OS-Atlas - a foundational GUI action model that excels at GUI grounding and OOD agentic tasks through innovations in both data and modeling. We have invested significant engineering effort in developing an open-source toolkit for synthesizing GUI grounding data across multiple platforms, including Windows, Linux, MacOS, Android, and the web. Leveraging this toolkit, we are releasing the largest open-source cross-platform GUI grounding corpus to date, which contains over 13 million GUI elements. This dataset, combined with innovations in model training, provides a solid foundation for OS-Atlas to understand GUI screenshots and generalize to unseen interfaces. Through extensive evaluation across six benchmarks spanning three different platforms (mobile, desktop, and web), OS-Atlas demonstrates significant performance improvements over previous state-of-the-art models. Our evaluation also uncovers valuable insights into continuously improving and scaling the agentic capabilities of open-source VLMs.
AgentStore: Scalable Integration of Heterogeneous Agents As Specialized Generalist Computer Assistant
Oct 24, 2024Digital agents capable of automating complex computer tasks have attracted considerable attention due to their immense potential to enhance human-computer interaction. However, existing agent methods exhibit deficiencies in their generalization and specialization capabilities, especially in handling open-ended computer tasks in real-world environments. Inspired by the rich functionality of the App store, we present AgentStore, a scalable platform designed to dynamically integrate heterogeneous agents for automating computer tasks. AgentStore empowers users to integrate third-party agents, allowing the system to continuously enrich its capabilities and adapt to rapidly evolving operating systems. Additionally, we propose a novel core \textbf{MetaAgent} with the \textbf{AgentToken} strategy to efficiently manage diverse agents and utilize their specialized and generalist abilities for both domain-specific and system-wide tasks. Extensive experiments on three challenging benchmarks demonstrate that AgentStore surpasses the limitations of previous systems with narrow capabilities, particularly achieving a significant improvement from 11.21\% to 23.85\% on the OSWorld benchmark, more than doubling the previous results. Comprehensive quantitative and qualitative results further demonstrate AgentStore's ability to enhance agent systems in both generalization and specialization, underscoring its potential for developing the specialized generalist computer assistant. All our codes will be made publicly available in https://chengyou-jia.github.io/AgentStore-Home.
Disentangled Noisy Correspondence Learning
Aug 10, 2024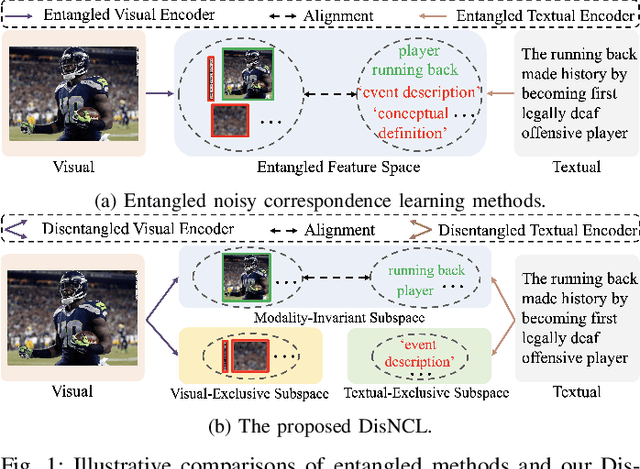
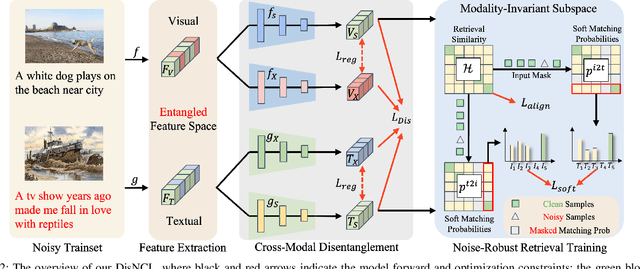
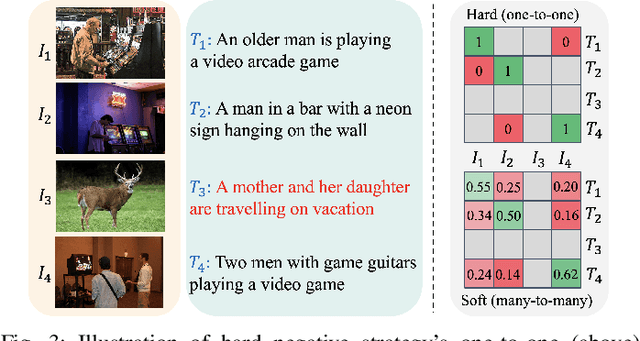
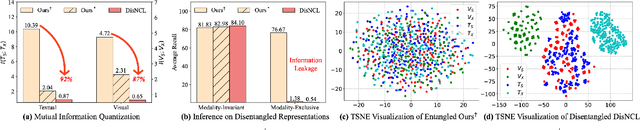
Cross-modal retrieval is crucial in understanding latent correspondences across modalities. However, existing methods implicitly assume well-matched training data, which is impractical as real-world data inevitably involves imperfect alignments, i.e., noisy correspondences. Although some works explore similarity-based strategies to address such noise, they suffer from sub-optimal similarity predictions influenced by modality-exclusive information (MEI), e.g., background noise in images and abstract definitions in texts. This issue arises as MEI is not shared across modalities, thus aligning it in training can markedly mislead similarity predictions. Moreover, although intuitive, directly applying previous cross-modal disentanglement methods suffers from limited noise tolerance and disentanglement efficacy. Inspired by the robustness of information bottlenecks against noise, we introduce DisNCL, a novel information-theoretic framework for feature Disentanglement in Noisy Correspondence Learning, to adaptively balance the extraction of MII and MEI with certifiable optimal cross-modal disentanglement efficacy. DisNCL then enhances similarity predictions in modality-invariant subspace, thereby greatly boosting similarity-based alleviation strategy for noisy correspondences. Furthermore, DisNCL introduces soft matching targets to model noisy many-to-many relationships inherent in multi-modal input for noise-robust and accurate cross-modal alignment. Extensive experiments confirm DisNCL's efficacy by 2% average recall improvement. Mutual information estimation and visualization results show that DisNCL learns meaningful MII/MEI subspaces, validating our theoretical analyses.
Noisy Correspondence Learning with Self-Reinforcing Errors Mitigation
Dec 27, 2023Cross-modal retrieval relies on well-matched large-scale datasets that are laborious in practice. Recently, to alleviate expensive data collection, co-occurring pairs from the Internet are automatically harvested for training. However, it inevitably includes mismatched pairs, \ie, noisy correspondences, undermining supervision reliability and degrading performance. Current methods leverage deep neural networks' memorization effect to address noisy correspondences, which overconfidently focus on \emph{similarity-guided training with hard negatives} and suffer from self-reinforcing errors. In light of above, we introduce a novel noisy correspondence learning framework, namely \textbf{S}elf-\textbf{R}einforcing \textbf{E}rrors \textbf{M}itigation (SREM). Specifically, by viewing sample matching as classification tasks within the batch, we generate classification logits for the given sample. Instead of a single similarity score, we refine sample filtration through energy uncertainty and estimate model's sensitivity of selected clean samples using swapped classification entropy, in view of the overall prediction distribution. Additionally, we propose cross-modal biased complementary learning to leverage negative matches overlooked in hard-negative training, further improving model optimization stability and curbing self-reinforcing errors. Extensive experiments on challenging benchmarks affirm the efficacy and efficiency of SREM.
Generating Action-conditioned Prompts for Open-vocabulary Video Action Recognition
Dec 04, 2023Exploring open-vocabulary video action recognition is a promising venture, which aims to recognize previously unseen actions within any arbitrary set of categories. Existing methods typically adapt pretrained image-text models to the video domain, capitalizing on their inherent strengths in generalization. A common thread among such methods is the augmentation of visual embeddings with temporal information to improve the recognition of seen actions. Yet, they compromise with standard less-informative action descriptions, thus faltering when confronted with novel actions. Drawing inspiration from human cognitive processes, we argue that augmenting text embeddings with human prior knowledge is pivotal for open-vocabulary video action recognition. To realize this, we innovatively blend video models with Large Language Models (LLMs) to devise Action-conditioned Prompts. Specifically, we harness the knowledge in LLMs to produce a set of descriptive sentences that contain distinctive features for identifying given actions. Building upon this foundation, we further introduce a multi-modal action knowledge alignment mechanism to align concepts in video and textual knowledge encapsulated within the prompts. Extensive experiments on various video benchmarks, including zero-shot, few-shot, and base-to-novel generalization settings, demonstrate that our method not only sets new SOTA performance but also possesses excellent interpretability.