 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the Prompt Becomes Visual: Vision-Centric Jailbreak Attacks for Large Image Editing Models
Feb 10, 2026Recent advances in large image editing models have shifted the paradigm from text-driven instructions to vision-prompt editing, where user intent is inferred directly from visual inputs such as marks, arrows, and visual-text prompts. While this paradigm greatly expands usability, it also introduces a critical and underexplored safety risk: the attack surface itself becomes visual. In this work, we propose Vision-Centric Jailbreak Attack (VJA), the first visual-to-visual jailbreak attack that conveys malicious instructions purely through visual inputs. To systematically study this emerging threat, we introduce IESBench, a safety-oriented benchmark for image editing models. Extensive experiments on IESBench demonstrate that VJA effectively compromises state-of-the-art commercial models, achieving attack success rates of up to 80.9% on Nano Banana Pro and 70.1% on GPT-Image-1.5. To mitigate this vulnerability, we propose a training-free defense based on introspective multimodal reasoning, which substantially improves the safety of poorly aligned models to a level comparable with commercial systems, without auxiliary guard models and with negligible computational overhead. Our findings expose new vulnerabilities, provide both a benchmark and practical defense to advance safe and trustworthy modern image editing systems. Warning: This paper contains offensive images created by large image editing models.
TextEditBench: Evaluating Reasoning-aware Text Editing Beyond Rendering
Dec 18, 2025Text rendering has recently emerged as one of the most challenging frontiers in visual generation, drawing significant attention from large-scale diffusion and multimodal models. However, text editing within images remains largely unexplored, as it requires generating legible characters while preserving semantic, geometric, and contextual coherence. To fill this gap, we introduce TextEditBench, a comprehensive evaluation benchmark that explicitly focuses on text-centric regions in images. Beyond basic pixel manipulations, our benchmark emphasizes reasoning-intensive editing scenarios that require models to understand physical plausibility, linguistic meaning, and cross-modal dependencies. We further propose a novel evaluation dimension, Semantic Expectation (SE), which measures reasoning ability of model to maintain semantic consistency, contextual coherence, and cross-modal alignment during text editing. Extensive experiments on state-of-the-art editing systems reveal that while current models can follow simple textual instructions, they still struggle with context-dependent reasoning, physical consistency, and layout-aware integration. By focusing evaluation on this long-overlooked yet fundamental capability, TextEditBench establishes a new testing ground for advancing text-guided image editing and reasoning in multimodal generation.
RECALL: REpresentation-aligned Catastrophic-forgetting ALLeviation via Hierarchical Model Merging
Oct 23, 2025We unveil that internal representations in large language models (LLMs) serve as reliable proxies of learned knowledge, and propose RECALL, a novel representation-aware model merging framework for continual learning without access to historical data. RECALL computes inter-model similarity from layer-wise hidden representations over clustered typical samples, and performs adaptive, hierarchical parameter fusion to align knowledge across models. This design enables the preservation of domain-general features in shallow layers while allowing task-specific adaptation in deeper layers. Unlike prior methods that require task labels or incur performance trade-offs, RECALL achieves seamless multi-domain integration and strong resistance to catastrophic forgetting. Extensive experiments across five NLP tasks and multiple continual learning scenarios show that RECALL outperforms baselines in both knowledge retention and generalization, providing a scalable and data-free solution for evolving LLMs.
Seeing is Not Reasoning: MVPBench for Graph-based Evaluation of Multi-path Visual Physical CoT
May 30, 2025Understanding the physical world - governed by laws of motion, spatial relations, and causality - poses a fundamental challenge for multimodal large language models (MLLMs). While recent advances such as OpenAI o3 and GPT-4o demonstrate impressive perceptual and reasoning capabilities, our investigation reveals these models struggle profoundly with visual physical reasoning, failing to grasp basic physical laws, spatial interactions, and causal effects in complex scenes. More importantly, they often fail to follow coherent reasoning chains grounded in visual evidence, especially when multiple steps are needed to arrive at the correct answer. To rigorously evaluate this capability, we introduce MVPBench, a curated benchmark designed to rigorously evaluate visual physical reasoning through the lens of visual chain-of-thought (CoT). Each example features interleaved multi-image inputs and demands not only the correct final answer but also a coherent, step-by-step reasoning path grounded in evolving visual cues. This setup mirrors how humans reason through real-world physical processes over time. To ensure fine-grained evaluation, we introduce a graph-based CoT consistency metric that verifies whether the reasoning path of model adheres to valid physical logic. Additionally, we minimize shortcut exploitation from text priors, encouraging models to rely on visual understanding. Experimental results reveal a concerning trend: even cutting-edge MLLMs exhibit poor visual reasoning accuracy and weak image-text alignment in physical domains. Surprisingly, RL-based post-training alignment - commonly believed to improve visual reasoning performance - often harms spatial reasoning, suggesting a need to rethink current fine-tuning practices.
Disentangled Noisy Correspondence Learning
Aug 10, 2024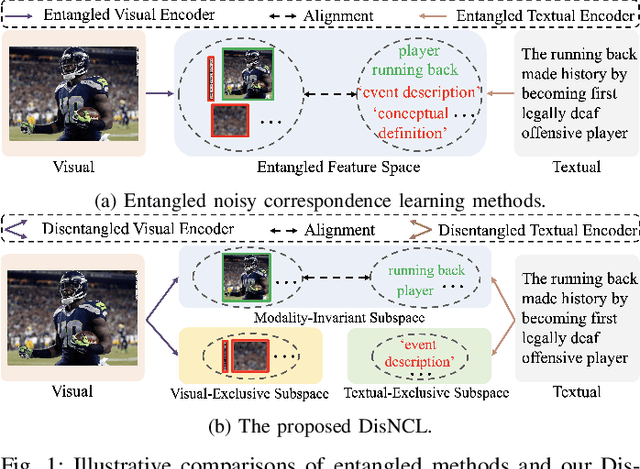
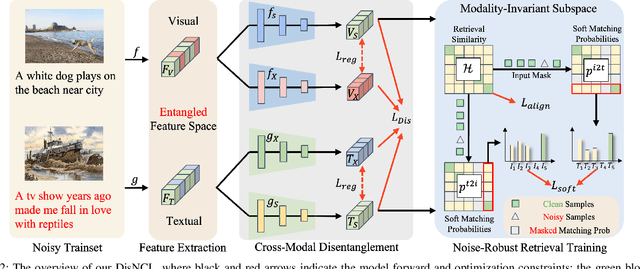
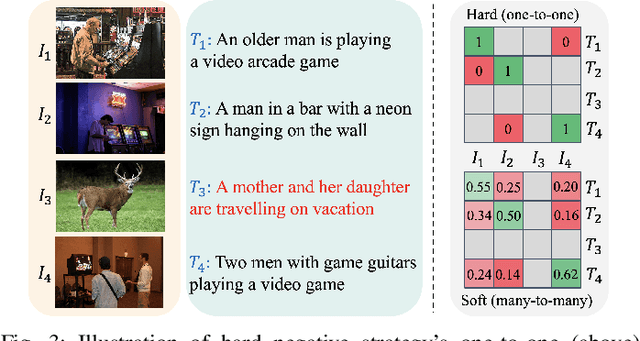
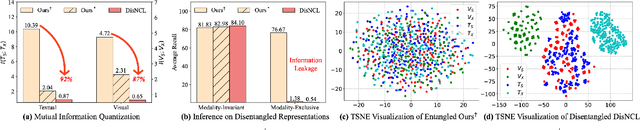
Cross-modal retrieval is crucial in understanding latent correspondences across modalities. However, existing methods implicitly assume well-matched training data, which is impractical as real-world data inevitably involves imperfect alignments, i.e., noisy correspondences. Although some works explore similarity-based strategies to address such noise, they suffer from sub-optimal similarity predictions influenced by modality-exclusive information (MEI), e.g., background noise in images and abstract definitions in texts. This issue arises as MEI is not shared across modalities, thus aligning it in training can markedly mislead similarity predictions. Moreover, although intuitive, directly applying previous cross-modal disentanglement methods suffers from limited noise tolerance and disentanglement efficacy. Inspired by the robustness of information bottlenecks against noise, we introduce DisNCL, a novel information-theoretic framework for feature Disentanglement in Noisy Correspondence Learning, to adaptively balance the extraction of MII and MEI with certifiable optimal cross-modal disentanglement efficacy. DisNCL then enhances similarity predictions in modality-invariant subspace, thereby greatly boosting similarity-based alleviation strategy for noisy correspondences. Furthermore, DisNCL introduces soft matching targets to model noisy many-to-many relationships inherent in multi-modal input for noise-robust and accurate cross-modal alignment. Extensive experiments confirm DisNCL's efficacy by 2% average recall improvement. Mutual information estimation and visualization results show that DisNCL learns meaningful MII/MEI subspaces, validating our theoretical analyses.
A Unified Optimal Transport Framework for Cross-Modal Retrieval with Noisy Labels
Mar 20, 2024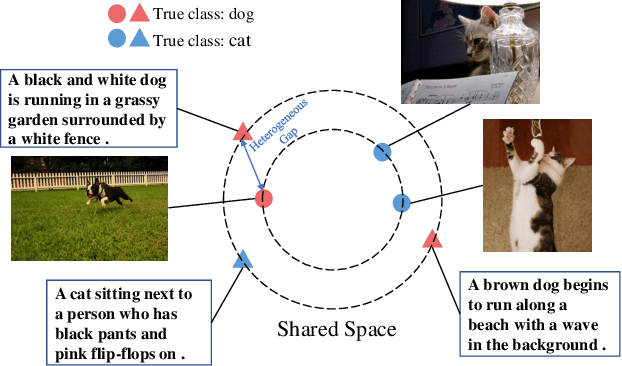
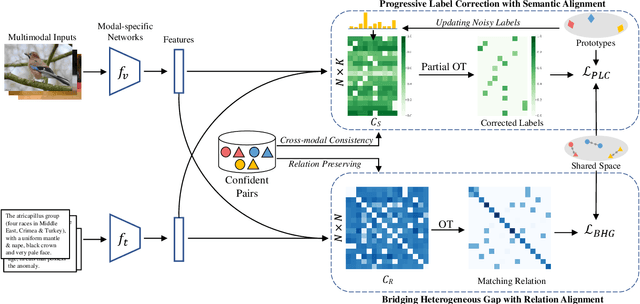
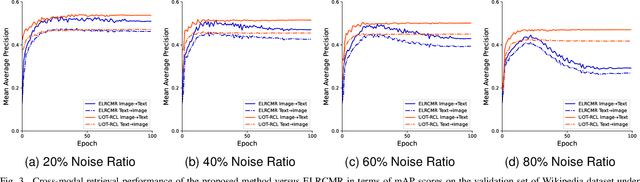
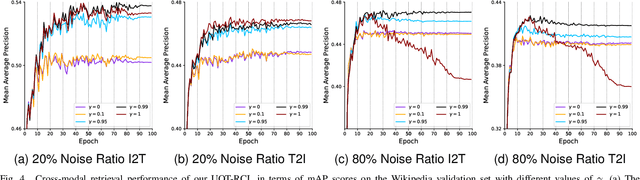
Cross-modal retrieval (CMR) aims to establish interaction between different modalities, among which supervised CMR is emerging due to its flexibility in learning semantic category discrimination. Despite the remarkable performance of previous supervised CMR methods, much of their success can be attributed to the well-annotated data. However, even for unimodal data, precise annotation is expensive and time-consuming, and it becomes more challenging with the multimodal scenario. In practice, massive multimodal data are collected from the Internet with coarse annotation, which inevitably introduces noisy labels. Training with such misleading labels would bring two key challenges -- enforcing the multimodal samples to \emph{align incorrect semantics} and \emph{widen the heterogeneous gap}, resulting in poor retrieval performance. To tackle these challenges, this work proposes UOT-RCL, a Unified framework based on Optimal Transport (OT) for Robust Cross-modal Retrieval. First, we propose a semantic alignment based on partial OT to progressively correct the noisy labels, where a novel cross-modal consistent cost function is designed to blend different modalities and provide precise transport cost. Second, to narrow the discrepancy in multi-modal data, an OT-based relation alignment is proposed to infer the semantic-level cross-modal matching. Both of these two components leverage the inherent correlation among multi-modal data to facilitate effective cost function. The experiments on three widely-used cross-modal retrieval datasets demonstrate that our UOT-RCL surpasses the state-of-the-art approaches and significantly improves the robustness against noisy labels.
Learning to Rematch Mismatched Pairs for Robust Cross-Modal Retrieval
Mar 08, 2024



Collecting well-matched multimedia datasets is crucial for training cross-modal retrieval models. However, in real-world scenarios, massive multimodal data are harvested from the Internet, which inevitably contains Partially Mismatched Pairs (PMPs). Undoubtedly, such semantical irrelevant data will remarkably harm the cross-modal retrieval performance. Previous efforts tend to mitigate this problem by estimating a soft correspondence to down-weight the contribution of PMPs. In this paper, we aim to address this challenge from a new perspective: the potential semantic similarity among unpaired samples makes it possible to excavate useful knowledge from mismatched pairs. To achieve this, we propose L2RM, a general framework based on Optimal Transport (OT) that learns to rematch mismatched pairs. In detail, L2RM aims to generate refined alignments by seeking a minimal-cost transport plan across different modalities. To formalize the rematching idea in OT, first, we propose a self-supervised cost function that automatically learns from explicit similarity-cost mapping relation. Second, we present to model a partial OT problem while restricting the transport among false positives to further boost refined alignments. Extensive experiments on three benchmarks demonstrate our L2RM significantly improves the robustness against PMPs for existing models. The code is available at https://github.com/hhc1997/L2RM.
Noisy Correspondence Learning with Meta Similarity Correction
Apr 13, 2023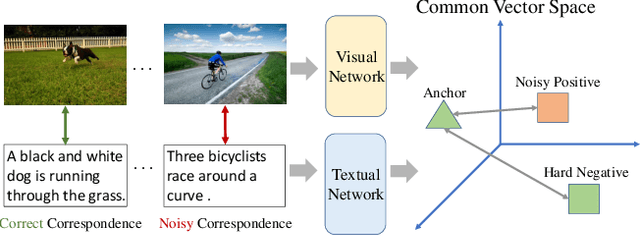
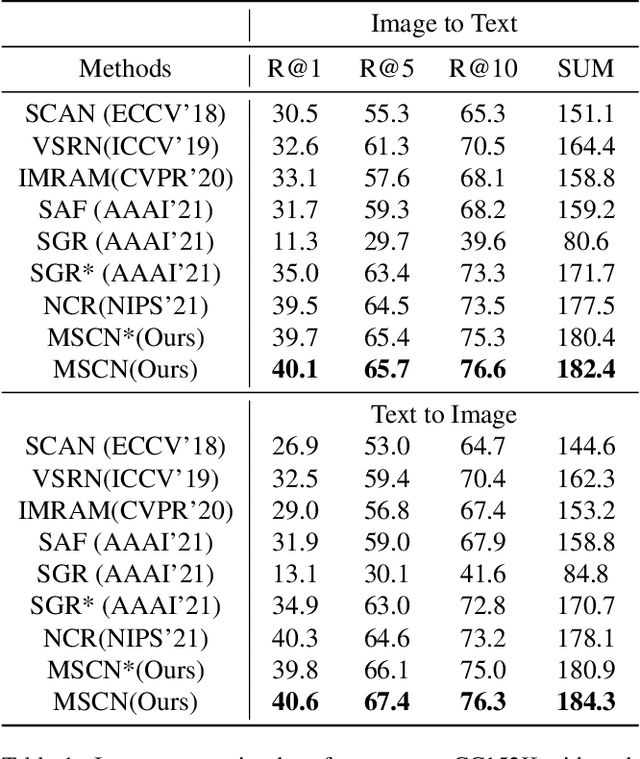
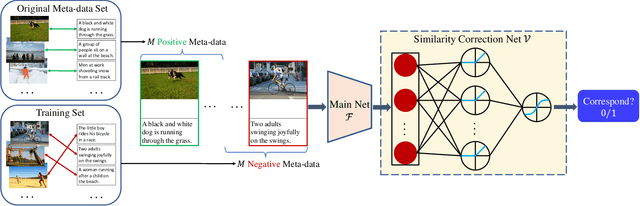
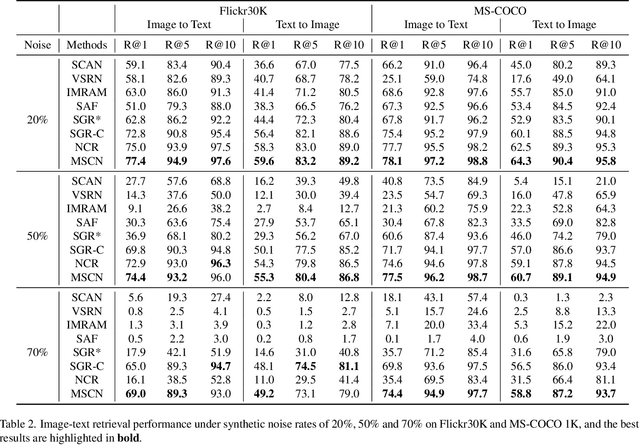
Despite the success of multimodal learning in cross-modal retrieval task, the remarkable progress relies on the correct correspondence among multimedia data. However, collecting such ideal data is expensive and time-consuming. In practice, most widely used datasets are harvested from the Internet and inevitably contain mismatched pairs. Training on such noisy correspondence datasets causes performance degradation because the cross-modal retrieval methods can wrongly enforce the mismatched data to be similar. To tackle this problem, we propose a Meta Similarity Correction Network (MSCN) to provide reliable similarity scores. We view a binary classification task as the meta-process that encourages the MSCN to learn discrimination from positive and negative meta-data. To further alleviate the influence of noise, we design an effective data purification strategy using meta-data as prior knowledge to remove the noisy samples. Extensive experiments are conducted to demonstrate the strengths of our method in both synthetic and real-world noises, including Flickr30K, MS-COCO, and Conceptual Captions.
Noise-Tolerant Learning for Audio-Visual Action Recognition
May 20, 2022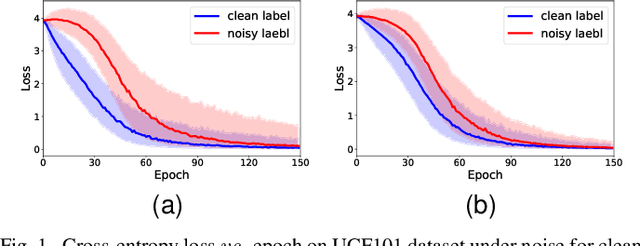
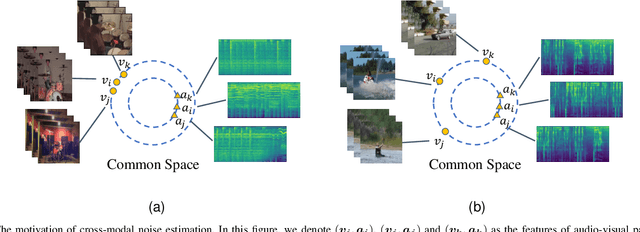
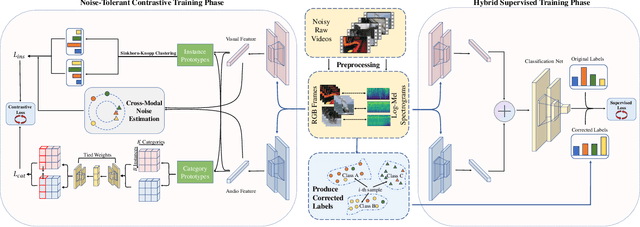
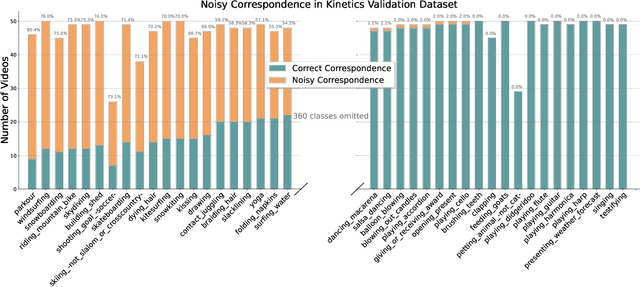
Recently, video recognition is emerging with the help of multi-modal learning, which focuses on integrating multiple modalities to improve the performance or robustness of a model. Although various multi-modal learning methods have been proposed and offer remarkable recognition results, almost all of these methods rely on high-quality manual annotations and assume that modalities among multi-modal data provide relevant semantic information. Unfortunately, most widely used video datasets are collected from the Internet and inevitably contain noisy labels and noisy correspondence. To solve this problem, we use the audio-visual action recognition task as a proxy and propose a noise-tolerant learning framework to find anti-interference model parameters to both noisy labels and noisy correspondence. Our method consists of two phases and aims to rectify noise by the inherent correlation between modalities. A noise-tolerant contrastive training phase is performed first to learn robust model parameters unaffected by the noisy labels. To reduce the influence of noisy correspondence, we propose a cross-modal noise estimation component to adjust the consistency between different modalities. Since the noisy correspondence existed at the instance level, a category-level contrastive loss is proposed to further alleviate the interference of noisy correspondence. Then in the hybrid supervised training phase, we calculate the distance metric among features to obtain corrected labels, which are used as complementary supervision. In addition, we investigate the noisy correspondence in real-world datasets and conduct comprehensive experiments with synthetic and real noise data. The results verify the advantageous performance of our method compared to state-of-the-art methods.