 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan-MCTS: Plan Exploration for Action Exploitation in Web Navigation
Feb 15, 2026Large Language Models (LLMs) have empowered autonomous agents to handle complex web navigation tasks. While recent studies integrate tree search to enhance long-horizon reasoning, applying these algorithms in web navigation faces two critical challenges: sparse valid paths that lead to inefficient exploration, and a noisy context that dilutes accurate state perception. To address this, we introduce Plan-MCTS, a framework that reformulates web navigation by shifting exploration to a semantic Plan Space. By decoupling strategic planning from execution grounding, it transforms sparse action space into a Dense Plan Tree for efficient exploration, and distills noisy contexts into an Abstracted Semantic History for precise state awareness. To ensure efficiency and robustness, Plan-MCTS incorporates a Dual-Gating Reward to strictly validate both physical executability and strategic alignment and Structural Refinement for on-policy repair of failed subplans. Extensive experiments on WebArena demonstrate that Plan-MCTS achieves state-of-the-art performance, surpassing current approaches with higher task effectiveness and search efficiency.
ColorEcosystem: Powering Personalized, Standardized, and Trustworthy Agentic Service in massive-agent Ecosystem
Oct 27, 2025With the rapid development of (multimodal) large language model-based agents, the landscape of agentic service management has evolved from single-agent systems to multi-agent systems, and now to massive-agent ecosystems. Current massive-agent ecosystems face growing challenges, including impersonal service experiences, a lack of standardization, and untrustworthy behavior. To address these issues, we propose ColorEcosystem, a novel blueprint designed to enable personalized, standardized, and trustworthy agentic service at scale. Concretely, ColorEcosystem consists of three key components: agent carrier, agent store, and agent audit. The agent carrier provides personalized service experiences by utilizing user-specific data and creating a digital twin, while the agent store serves as a centralized, standardized platform for managing diverse agentic services. The agent audit, based on the supervision of developer and user activities, ensures the integrity and credibility of both service providers and users. Through the analysis of challenges, transitional forms, and practical considerations, the ColorEcosystem is poised to power personalized, standardized, and trustworthy agentic service across massive-agent ecosystems. Meanwhile, we have also implemented part of ColorEcosystem's functionality, and the relevant code is open-sourced at https://github.com/opas-lab/color-ecosystem.
A physics-guided smoothing method for material modeling with digital image correlation (DIC) measurements
May 24, 2025In this work, we present a novel approach to process the DIC measurements of multiple biaxial stretching protocols. In particular, we develop a optimization-based approach, which calculates the smoothed nodal displacements using a moving least-squares algorithm subject to positive strain constraints. As such, physically consistent displacement and strain fields are obtained. Then, we further deploy a data-driven workflow to heterogeneous material modeling from these physically consistent DIC measurements, by estimating a nonlocal constitutive law together with the material microstructure. To demonstrate the applicability of our approach, we apply it in learning a material model and fiber orientation field from DIC measurements of a porcine tricuspid valve anterior leaflet. Our results demonstrate that the proposed DIC data processing approach can significantly improve the accuracy of modeling biological materials.
Monotone Peridynamic Neural Operator for Nonlinear Material Modeling with Conditionally Unique Solutions
May 02, 2025



Data-driven methods have emerged as powerful tools for modeling the responses of complex nonlinear materials directly from experimental measurements. Among these methods, the data-driven constitutive models present advantages in physical interpretability and generalizability across different boundary conditions/domain settings. However, the well-posedness of these learned models is generally not guaranteed a priori, which makes the models prone to non-physical solutions in downstream simulation tasks. In this study, we introduce monotone peridynamic neural operator (MPNO), a novel data-driven nonlocal constitutive model learning approach based on neural operators. Our approach learns a nonlocal kernel together with a nonlinear constitutive relation, while ensuring solution uniqueness through a monotone gradient network. This architectural constraint on gradient induces convexity of the learnt energy density function, thereby guaranteeing solution uniqueness of MPNO in small deformation regimes. To validate our approach, we evaluate MPNO's performance on both synthetic and real-world datasets. On synthetic datasets with manufactured kernel and constitutive relation, we show that the learnt model converges to the ground-truth as the measurement grid size decreases both theoretically and numerically. Additionally, our MPNO exhibits superior generalization capabilities than the conventional neural networks: it yields smaller displacement solution errors in down-stream tasks with new and unseen loadings. Finally, we showcase the practical utility of our approach through applications in learning a homogenized model from molecular dynamics data, highlighting its expressivity and robustness in real-world scenarios.
Disentangled Noisy Correspondence Learning
Aug 10, 2024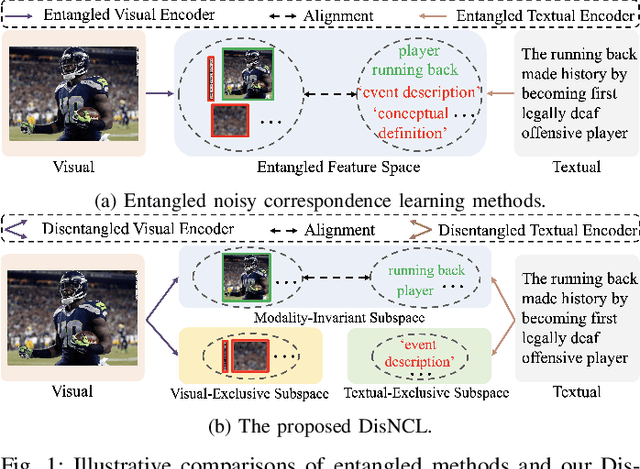
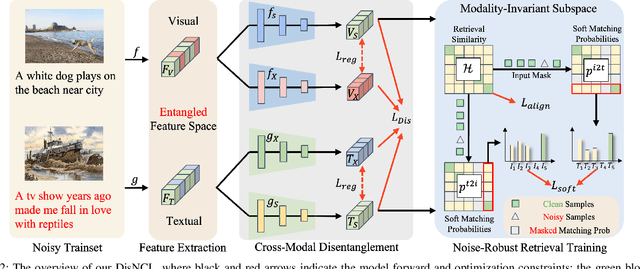
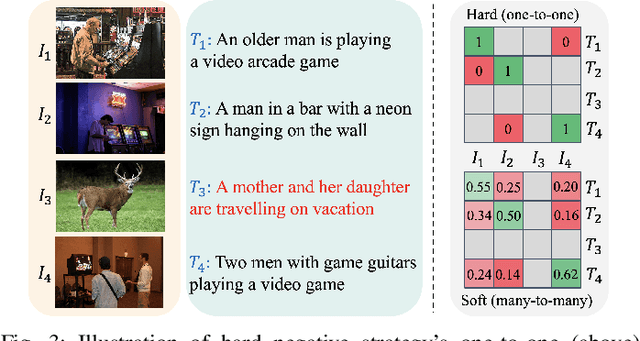
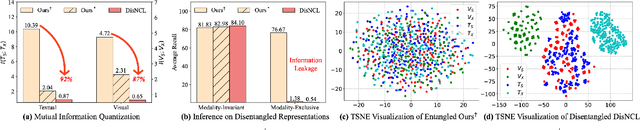
Cross-modal retrieval is crucial in understanding latent correspondences across modalities. However, existing methods implicitly assume well-matched training data, which is impractical as real-world data inevitably involves imperfect alignments, i.e., noisy correspondences. Although some works explore similarity-based strategies to address such noise, they suffer from sub-optimal similarity predictions influenced by modality-exclusive information (MEI), e.g., background noise in images and abstract definitions in texts. This issue arises as MEI is not shared across modalities, thus aligning it in training can markedly mislead similarity predictions. Moreover, although intuitive, directly applying previous cross-modal disentanglement methods suffers from limited noise tolerance and disentanglement efficacy. Inspired by the robustness of information bottlenecks against noise, we introduce DisNCL, a novel information-theoretic framework for feature Disentanglement in Noisy Correspondence Learning, to adaptively balance the extraction of MII and MEI with certifiable optimal cross-modal disentanglement efficacy. DisNCL then enhances similarity predictions in modality-invariant subspace, thereby greatly boosting similarity-based alleviation strategy for noisy correspondences. Furthermore, DisNCL introduces soft matching targets to model noisy many-to-many relationships inherent in multi-modal input for noise-robust and accurate cross-modal alignment. Extensive experiments confirm DisNCL's efficacy by 2% average recall improvement. Mutual information estimation and visualization results show that DisNCL learns meaningful MII/MEI subspaces, validating our theoretical analyses.
Disentangled Representation Learning with Transmitted Information Bottleneck
Nov 03, 2023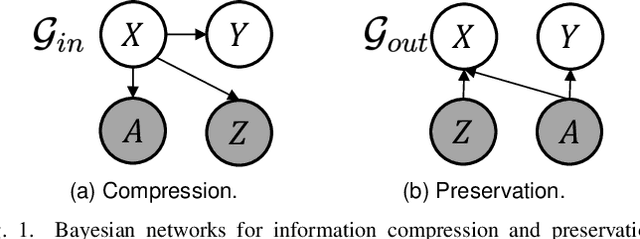



Encoding only the task-related information from the raw data, \ie, disentangled representation learning, can greatly contribute to the robustness and generalizability of models. Although significant advances have been made by regularizing the information in representations with information theory, two major challenges remain: 1) the representation compression inevitably leads to performance drop; 2) the disentanglement constraints on representations are in complicated optimization. To these issues, we introduce Bayesian networks with transmitted information to formulate the interaction among input and representations during disentanglement. Building upon this framework, we propose \textbf{DisTIB} (\textbf{T}ransmitted \textbf{I}nformation \textbf{B}ottleneck for \textbf{Dis}entangled representation learning), a novel objective that navigates the balance between information compression and preservation. We employ variational inference to derive a tractable estimation for DisTIB. This estimation can be simply optimized via standard gradient descent with a reparameterization trick. Moreover, we theoretically prove that DisTIB can achieve optimal disentanglement, underscoring its superior efficacy. To solidify our claims, we conduct extensive experiments on various downstream tasks to demonstrate the appealing efficacy of DisTIB and validate our theoretical analyses.
Disentangled Generation with Information Bottleneck for Few-Shot Learning
Nov 29, 2022



Few-shot learning (FSL), which aims to classify unseen classes with few samples, is challenging due to data scarcity. Although various generative methods have been explored for FSL, the entangled generation process of these methods exacerbates the distribution shift in FSL, thus greatly limiting the quality of generated samples. To these challenges, we propose a novel Information Bottleneck (IB) based Disentangled Generation Framework for FSL, termed as DisGenIB, that can simultaneously guarantee the discrimination and diversity of generated samples. Specifically, we formulate a novel framework with information bottleneck that applies for both disentangled representation learning and sample generation. Different from existing IB-based methods that can hardly exploit priors, we demonstrate our DisGenIB can effectively utilize priors to further facilitate disentanglement. We further prove in theory that some previous generative and disentanglement methods are special cases of our DisGenIB, which demonstrates the generality of the proposed DisGenIB. Extensive experiments on challenging FSL benchmarks confirm the effectiveness and superiority of DisGenIB, together with the validity of our theoretical analyses. Our codes will be open-source upon acceptance.
Towards Explanation for Unsupervised Graph-Level Representation Learning
May 20, 2022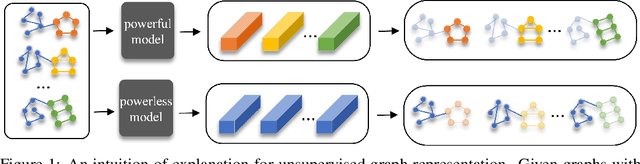

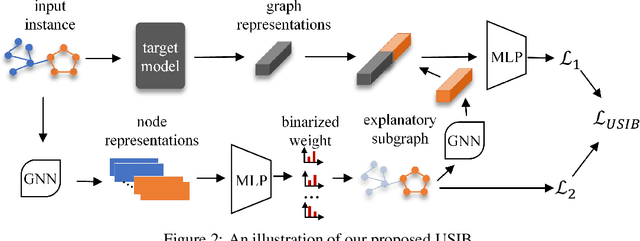
Due to the superior performance of Graph Neural Networks (GNNs) in various domains, there is an increasing interest in the GNN explanation problem "\emph{which fraction of the input graph is the most crucial to decide the model's decision?}" Existing explanation methods focus on the supervised settings, \eg, node classification and graph classification, while the explanation for unsupervised graph-level representation learning is still unexplored. The opaqueness of the graph representations may lead to unexpected risks when deployed for high-stake decision-making scenarios. In this paper, we advance the Information Bottleneck principle (IB) to tackle the proposed explanation problem for unsupervised graph representations, which leads to a novel principle, \textit{Unsupervised Subgraph Information Bottleneck} (USIB). We also theoretically analyze the connection between graph representations and explanatory subgraphs on the label space, which reveals that the expressiveness and robustness of representations benefit the fidelity of explanatory subgraphs. Experimental results on both synthetic and real-world datasets demonstrate the superiority of our developed explainer and the validity of our theoretical analysis.
Robust Unsupervised Graph Representation Learning via Mutual Information Maximization
Jan 21, 2022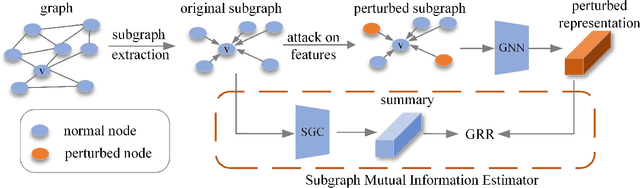

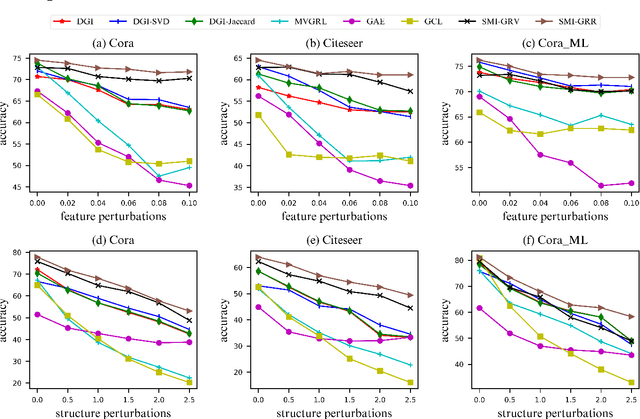
Recent studies have shown that GNNs are vulnerable to adversarial attack. Thus, many approaches are proposed to improve the robustness of GNNs against adversarial attacks. Nevertheless, most of these methods measure the model robustness based on label information and thus become infeasible when labels information is not available. Therefore, this paper focuses on robust unsupervised graph representation learning. In particular, to quantify the robustness of GNNs without label information, we propose a robustness measure, named graph representation robustness (GRR), to evaluate the mutual information between adversarially perturbed node representations and the original graph. There are mainly two challenges to estimate GRR: 1) mutual information estimation upon adversarially attacked graphs; 2) high complexity of adversarial attack to perturb node features and graph structure jointly in the training procedure. To tackle these problems, we further propose an effective mutual information estimator with subgraph-level summary and an efficient adversarial training strategy with only feature perturbations. Moreover, we theoretically establish a connection between our proposed GRR measure and the robustness of downstream classifiers, which reveals that GRR can provide a lower bound to the adversarial risk of downstream classifiers. Extensive experiments over several benchmarks demonstrate the effectiveness and superiority of our proposed method.
Scalable Attack on Graph Data by Injecting Vicious Nodes
Apr 22, 2020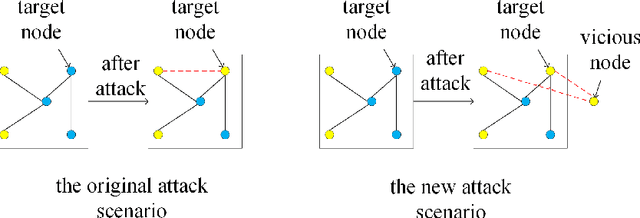
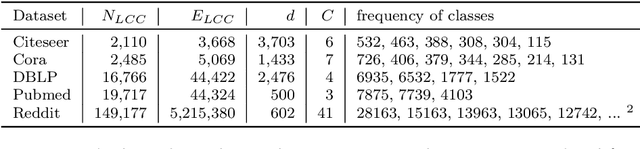

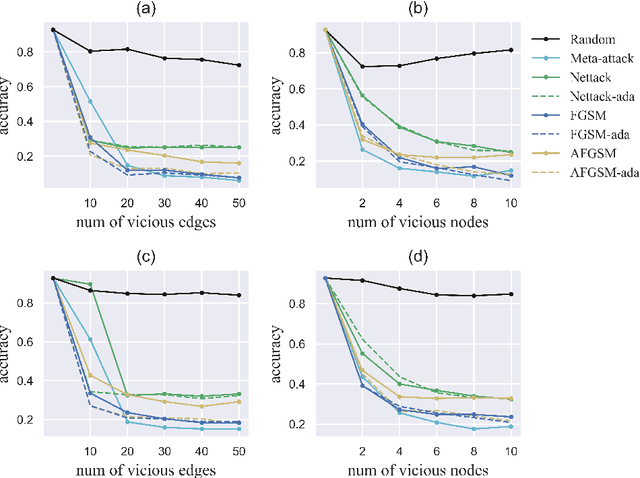
Recent studies have shown that graph convolution networks (GCNs) are vulnerable to carefully designed attacks, which aim to cause misclassification of a specific node on the graph with unnoticeable perturbations. However, a vast majority of existing works cannot handle large-scale graphs because of their high time complexity. Additionally, existing works mainly focus on manipulating existing nodes on the graph, while in practice, attackers usually do not have the privilege to modify information of existing nodes. In this paper, we develop a more scalable framework named Approximate Fast Gradient Sign Method (AFGSM) which considers a more practical attack scenario where adversaries can only inject new vicious nodes to the graph while having no control over the original graph. Methodologically, we provide an approximation strategy to linearize the model we attack and then derive an approximate closed-from solution with a lower time cost. To have a fair comparison with existing attack methods that manipulate the original graph, we adapt them to the new attack scenario by injecting vicious nodes. Empirical experimental results show that our proposed attack method can significantly reduce the classification accuracy of GCNs and is much faster than existing methods without jeopardizing the attack performance.