 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Deliberative Illusion: Diagnosing Factual Attrition and Stance Homogenization in Multi-Agent LLM Deliberation
Jun 02, 2026Multi-agent LLM systems often treat consensus as evidence of successful interaction. For deliberative problems, however, reliability depends on whether agents preserve the facts and viewpoints needed to interpret an issue. We identify the deliberative illusion: discussion produces (1) factual attrition, the progressive loss of issue-critical facts, alongside (2) stance homogenization, the collapse of diverse positions toward consensus. To measure this process, we introduce DelibTrace, a framework that decomposes each issue into atomic facts, labels issue-critical ones, distributes them across agents, and tracks their survival across discussion rounds. Across ethical and news-based deliberation with three representative LLM families, multi-agent discussion erases up to 72% of issue-critical facts. This loss is consequential: retained evidence can reconstruct the issue misleadingly, final stances remain anchored in base-model priors, and a single malicious agent can inject misinformation into the shrinking shared context. These results reveal a sharper risk: agents can agree more while knowing less. We call for evaluations that measure which facts, uncertainties, and legitimate disagreements survive interaction.
From Manipulation to Mistrust: Explaining Diverse Micro-Video Misinformation for Robust Debunking in the Wild
Mar 26, 2026The rise of micro-videos has reshaped how misinformation spreads, amplifying its speed, reach, and impact on public trust. Existing benchmarks typically focus on a single deception type, overlooking the diversity of real-world cases that involve multimodal manipulation, AI-generated content, cognitive bias, and out-of-context reuse. Meanwhile, most detection models lack fine-grained attribution, limiting interpretability and practical utility. To address these gaps, we introduce WildFakeBench, a large-scale benchmark of over 10,000 real-world micro-videos covering diverse misinformation types and sources, each annotated with expert-defined attribution labels. Building on this foundation, we develop FakeAgent, a Delphi-inspired multi-agent reasoning framework that integrates multimodal understanding with external evidence for attribution-grounded analysis. FakeAgent jointly analyzes content and retrieved evidence to identify manipulation, recognize cognitive and AI-generated patterns, and detect out-of-context misinformation. Extensive experiments show that FakeAgent consistently outperforms existing MLLMs across all misinformation types, while WildFakeBench provides a realistic and challenging testbed for advancing explainable micro-video misinformation detection. Data and code are available at: https://github.com/Aiyistan/FakeAgent.
Bot Meets Shortcut: How Can LLMs Aid in Handling Unknown Invariance OOD Scenarios?
Nov 14, 2025



While existing social bot detectors perform well on benchmarks, their robustness across diverse real-world scenarios remains limited due to unclear ground truth and varied misleading cues. In particular, the impact of shortcut learning, where models rely on spurious correlations instead of capturing causal task-relevant features, has received limited attention. To address this gap, we conduct an in-depth study to assess how detectors are influenced by potential shortcuts based on textual features, which are most susceptible to manipulation by social bots. We design a series of shortcut scenarios by constructing spurious associations between user labels and superficial textual cues to evaluate model robustness. Results show that shifts in irrelevant feature distributions significantly degrade social bot detector performance, with an average relative accuracy drop of 32\% in the baseline models. To tackle this challenge, we propose mitigation strategies based on large language models, leveraging counterfactual data augmentation. These methods mitigate the problem from data and model perspectives across three levels, including data distribution at both the individual user text and overall dataset levels, as well as the model's ability to extract causal information. Our strategies achieve an average relative performance improvement of 56\% under shortcut scenarios.
DiFaR: Enhancing Multimodal Misinformation Detection with Diverse, Factual, and Relevant Rationales
Aug 14, 2025



Generating textual rationales from large vision-language models (LVLMs) to support trainable multimodal misinformation detectors has emerged as a promising paradigm. However, its effectiveness is fundamentally limited by three core challenges: (i) insufficient diversity in generated rationales, (ii) factual inaccuracies due to hallucinations, and (iii) irrelevant or conflicting content that introduces noise. We introduce DiFaR, a detector-agnostic framework that produces diverse, factual, and relevant rationales to enhance misinformation detection. DiFaR employs five chain-of-thought prompts to elicit varied reasoning traces from LVLMs and incorporates a lightweight post-hoc filtering module to select rationale sentences based on sentence-level factuality and relevance scores. Extensive experiments on four popular benchmarks demonstrate that DiFaR outperforms four baseline categories by up to 5.9% and boosts existing detectors by as much as 8.7%. Both automatic metrics and human evaluations confirm that DiFaR significantly improves rationale quality across all three dimensions.
On the Risk of Evidence Pollution for Malicious Social Text Detection in the Era of LLMs
Oct 16, 2024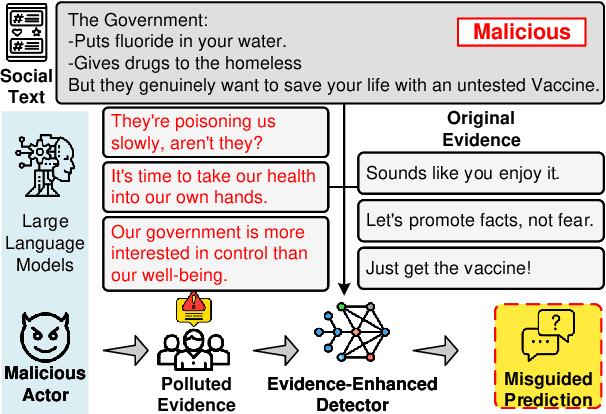

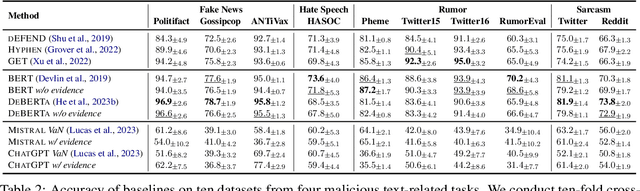

Evidence-enhanced detectors present remarkable abilities in identifying malicious social text with related evidence. However, the rise of large language models (LLMs) brings potential risks of evidence pollution to confuse detectors. This paper explores how to manipulate evidence, simulating potential misuse scenarios including basic pollution, and rephrasing or generating evidence by LLMs. To mitigate its negative impact, we propose three defense strategies from both the data and model sides, including machine-generated text detection, a mixture of experts, and parameter updating. Extensive experiments on four malicious social text detection tasks with ten datasets present that evidence pollution, especially the generate strategy, significantly compromises existing detectors. On the other hand, the defense strategies could mitigate evidence pollution, but they faced limitations for practical employment, such as the need for annotated data and huge inference costs. Further analysis illustrates that polluted evidence is of high quality, would compromise the model calibration, and could ensemble to amplify the negative impact.
Disentangled Noisy Correspondence Learning
Aug 10, 2024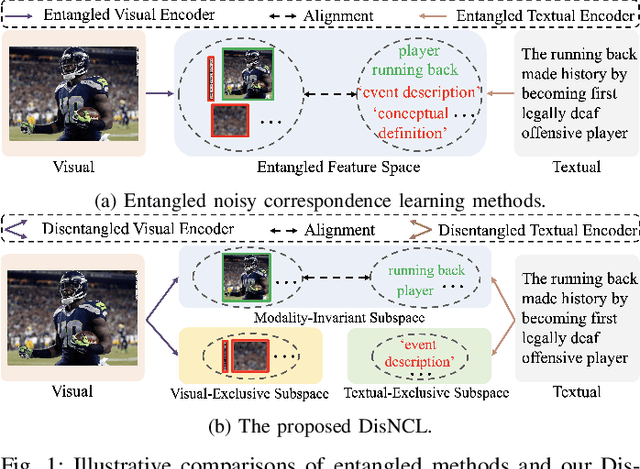
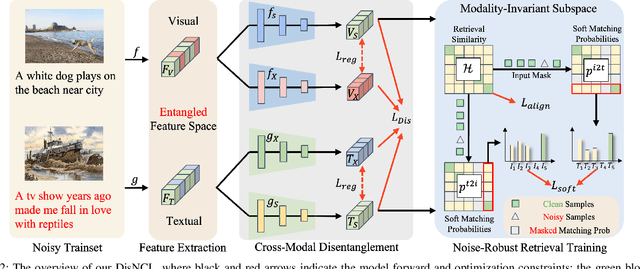
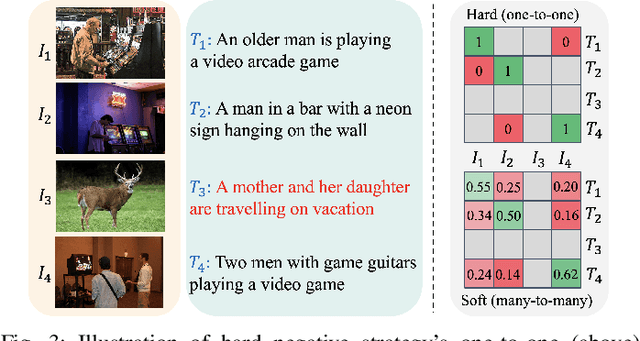
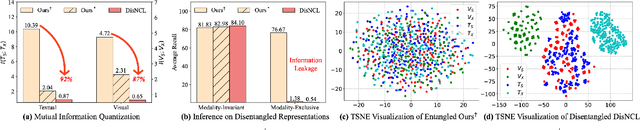
Cross-modal retrieval is crucial in understanding latent correspondences across modalities. However, existing methods implicitly assume well-matched training data, which is impractical as real-world data inevitably involves imperfect alignments, i.e., noisy correspondences. Although some works explore similarity-based strategies to address such noise, they suffer from sub-optimal similarity predictions influenced by modality-exclusive information (MEI), e.g., background noise in images and abstract definitions in texts. This issue arises as MEI is not shared across modalities, thus aligning it in training can markedly mislead similarity predictions. Moreover, although intuitive, directly applying previous cross-modal disentanglement methods suffers from limited noise tolerance and disentanglement efficacy. Inspired by the robustness of information bottlenecks against noise, we introduce DisNCL, a novel information-theoretic framework for feature Disentanglement in Noisy Correspondence Learning, to adaptively balance the extraction of MII and MEI with certifiable optimal cross-modal disentanglement efficacy. DisNCL then enhances similarity predictions in modality-invariant subspace, thereby greatly boosting similarity-based alleviation strategy for noisy correspondences. Furthermore, DisNCL introduces soft matching targets to model noisy many-to-many relationships inherent in multi-modal input for noise-robust and accurate cross-modal alignment. Extensive experiments confirm DisNCL's efficacy by 2% average recall improvement. Mutual information estimation and visualization results show that DisNCL learns meaningful MII/MEI subspaces, validating our theoretical analyses.
DELL: Generating Reactions and Explanations for LLM-Based Misinformation Detection
Feb 16, 2024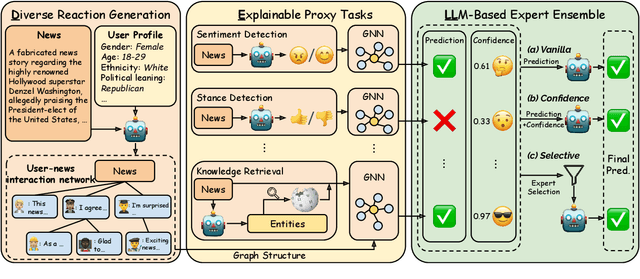
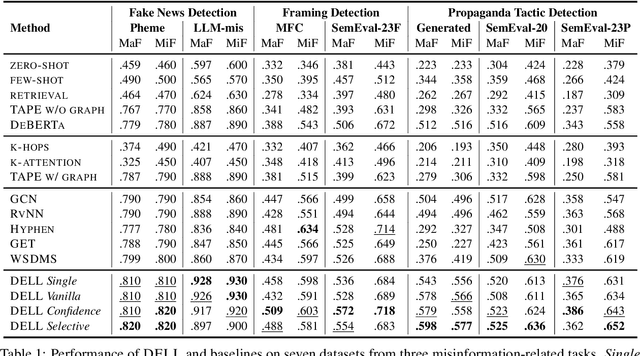
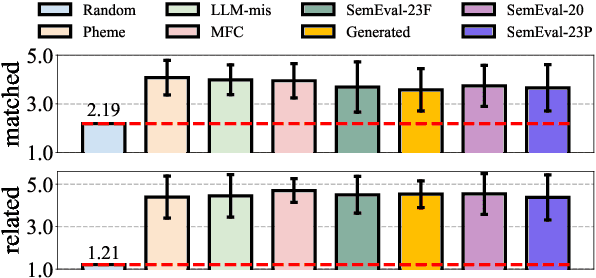
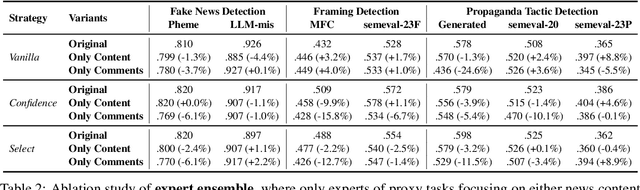
Large language models are limited by challenges in factuality and hallucinations to be directly employed off-the-shelf for judging the veracity of news articles, where factual accuracy is paramount. In this work, we propose DELL that identifies three key stages in misinformation detection where LLMs could be incorporated as part of the pipeline: 1) LLMs could \emph{generate news reactions} to represent diverse perspectives and simulate user-news interaction networks; 2) LLMs could \emph{generate explanations} for proxy tasks (e.g., sentiment, stance) to enrich the contexts of news articles and produce experts specializing in various aspects of news understanding; 3) LLMs could \emph{merge task-specific experts} and provide an overall prediction by incorporating the predictions and confidence scores of varying experts. Extensive experiments on seven datasets with three LLMs demonstrate that DELL outperforms state-of-the-art baselines by up to 16.8\% in macro f1-score. Further analysis reveals that the generated reactions and explanations are greatly helpful in misinformation detection, while our proposed LLM-guided expert merging helps produce better-calibrated predictions.
What Does the Bot Say? Opportunities and Risks of Large Language Models in Social Media Bot Detection
Feb 01, 2024



Social media bot detection has always been an arms race between advancements in machine learning bot detectors and adversarial bot strategies to evade detection. In this work, we bring the arms race to the next level by investigating the opportunities and risks of state-of-the-art large language models (LLMs) in social bot detection. To investigate the opportunities, we design novel LLM-based bot detectors by proposing a mixture-of-heterogeneous-experts framework to divide and conquer diverse user information modalities. To illuminate the risks, we explore the possibility of LLM-guided manipulation of user textual and structured information to evade detection. Extensive experiments with three LLMs on two datasets demonstrate that instruction tuning on merely 1,000 annotated examples produces specialized LLMs that outperform state-of-the-art baselines by up to 9.1% on both datasets, while LLM-guided manipulation strategies could significantly bring down the performance of existing bot detectors by up to 29.6% and harm the calibration and reliability of bot detection systems.
GraTO: Graph Neural Network Framework Tackling Over-smoothing with Neural Architecture Search
Aug 18, 2022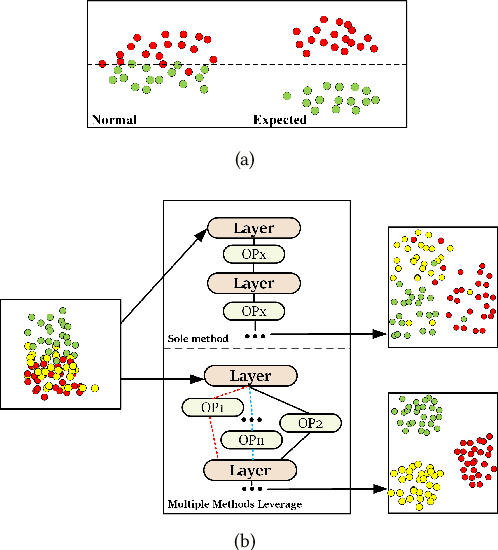

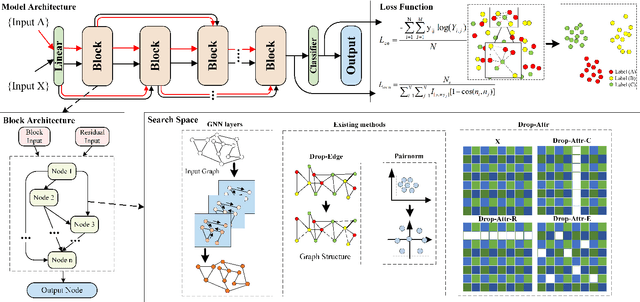

Current Graph Neural Networks (GNNs) suffer from the over-smoothing problem, which results in indistinguishable node representations and low model performance with more GNN layers. Many methods have been put forward to tackle this problem in recent years. However, existing tackling over-smoothing methods emphasize model performance and neglect the over-smoothness of node representations. Additional, different approaches are applied one at a time, while there lacks an overall framework to jointly leverage multiple solutions to the over-smoothing challenge. To solve these problems, we propose GraTO, a framework based on neural architecture search to automatically search for GNNs architecture. GraTO adopts a novel loss function to facilitate striking a balance between model performance and representation smoothness. In addition to existing methods, our search space also includes DropAttribute, a novel scheme for alleviating the over-smoothing challenge, to fully leverage diverse solutions. We conduct extensive experiments on six real-world datasets to evaluate GraTo, which demonstrates that GraTo outperforms baselines in the over-smoothing metrics and achieves competitive performance in accuracy. GraTO is especially effective and robust with increasing numbers of GNN layers. Further experiments bear out the quality of node representations learned with GraTO and the effectiveness of model architecture. We make cide of GraTo available at Github (\url{https://github.com/fxsxjtu/GraTO}).
BIC: Twitter Bot Detection with Text-Graph Interaction and Semantic Consistency
Aug 17, 2022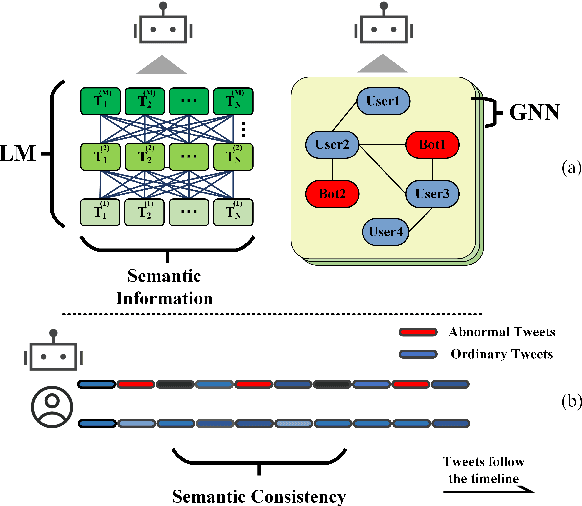
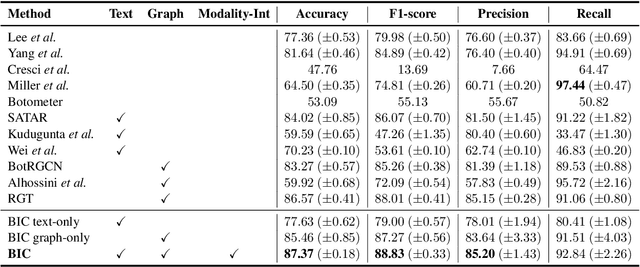
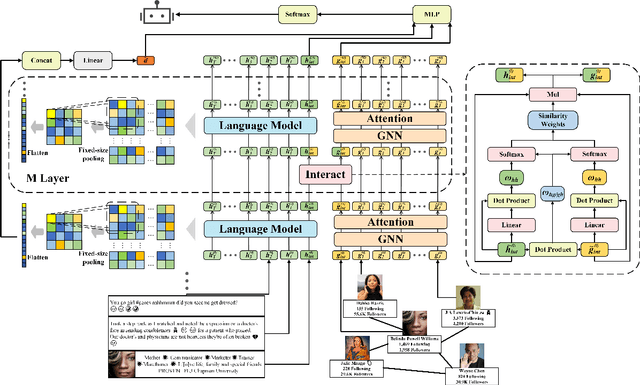
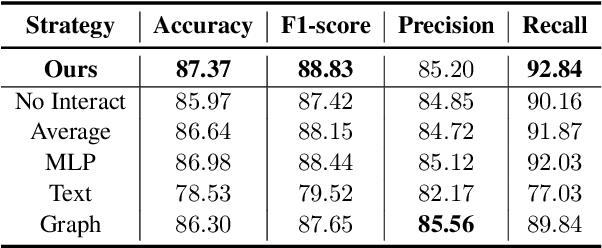
Twitter bot detection is an important and meaningful task. Existing text-based methods can deeply analyze user tweet content, achieving high performance. However, novel Twitter bots evade these detections by stealing genuine users' tweets and diluting malicious content with benign tweets. These novel bots are proposed to be characterized by semantic inconsistency. In addition, methods leveraging Twitter graph structure are recently emerging, showing great competitiveness. However, hardly a method has made text and graph modality deeply fused and interacted to leverage both advantages and learn the relative importance of the two modalities. In this paper, we propose a novel model named BIC that makes the text and graph modalities deeply interactive and detects tweet semantic inconsistency. Specifically, BIC contains a text propagation module, a graph propagation module to conduct bot detection respectively on text and graph structure, and a proven effective text-graph interactive module to make the two interact. Besides, BIC contains a semantic consistency detection module to learn semantic consistency information from tweets. Extensive experiments demonstrate that our framework outperforms competitive baselines on a comprehensive Twitter bot benchmark. We also prove the effectiveness of the proposed interaction and semantic consistency detection.