 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior Tokens Speak Louder: Disentangled Explainable Recommendation with Behavior Vocabulary
Dec 17, 2025
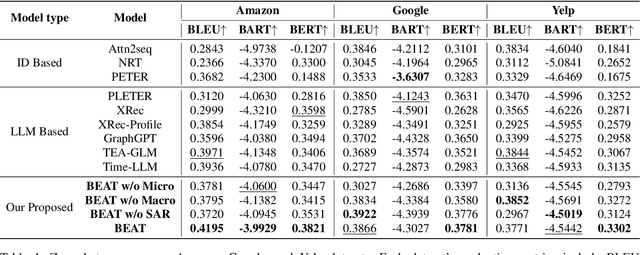


Recent advances in explainable recommendations have explored the integration of language models to analyze natural language rationales for user-item interactions. Despite their potential, existing methods often rely on ID-based representations that obscure semantic meaning and impose structural constraints on language models, thereby limiting their applicability in open-ended scenarios. These challenges are intensified by the complex nature of real-world interactions, where diverse user intents are entangled and collaborative signals rarely align with linguistic semantics. To overcome these limitations, we propose BEAT, a unified and transferable framework that tokenizes user and item behaviors into discrete, interpretable sequences. We construct a behavior vocabulary via a vector-quantized autoencoding process that disentangles macro-level interests and micro-level intentions from graph-based representations. We then introduce multi-level semantic supervision to bridge the gap between behavioral signals and language space. A semantic alignment regularization mechanism is designed to embed behavior tokens directly into the input space of frozen language models. Experiments on three public datasets show that BEAT improves zero-shot recommendation performance while generating coherent and informative explanations. Further analysis demonstrates that our behavior tokens capture fine-grained semantics and offer a plug-and-play interface for integrating complex behavior patterns into large language models.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
GraTO: Graph Neural Network Framework Tackling Over-smoothing with Neural Architecture Search
Aug 18, 2022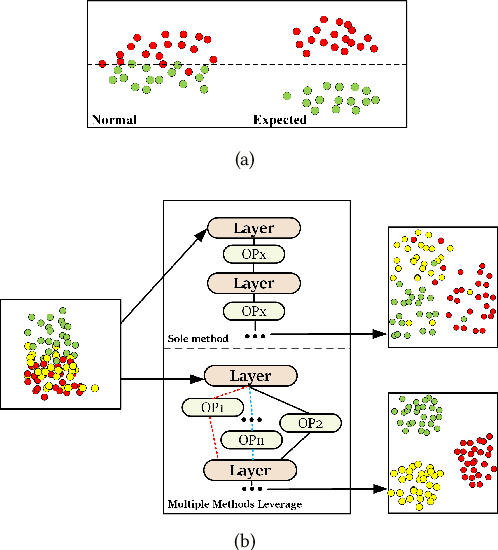

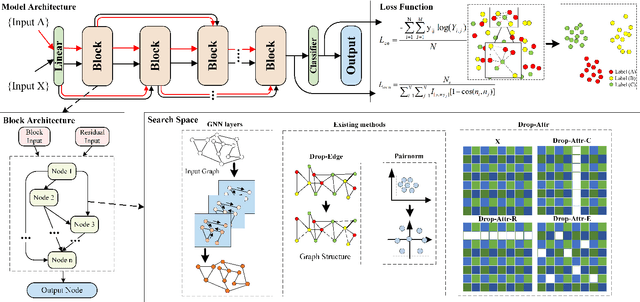

Current Graph Neural Networks (GNNs) suffer from the over-smoothing problem, which results in indistinguishable node representations and low model performance with more GNN layers. Many methods have been put forward to tackle this problem in recent years. However, existing tackling over-smoothing methods emphasize model performance and neglect the over-smoothness of node representations. Additional, different approaches are applied one at a time, while there lacks an overall framework to jointly leverage multiple solutions to the over-smoothing challenge. To solve these problems, we propose GraTO, a framework based on neural architecture search to automatically search for GNNs architecture. GraTO adopts a novel loss function to facilitate striking a balance between model performance and representation smoothness. In addition to existing methods, our search space also includes DropAttribute, a novel scheme for alleviating the over-smoothing challenge, to fully leverage diverse solutions. We conduct extensive experiments on six real-world datasets to evaluate GraTo, which demonstrates that GraTo outperforms baselines in the over-smoothing metrics and achieves competitive performance in accuracy. GraTO is especially effective and robust with increasing numbers of GNN layers. Further experiments bear out the quality of node representations learned with GraTO and the effectiveness of model architecture. We make cide of GraTo available at Github (\url{https://github.com/fxsxjtu/GraTO}).
TwiBot-22: Towards Graph-Based Twitter Bot Detection
Jun 12, 2022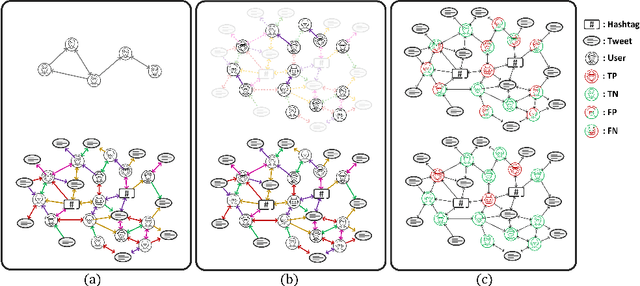
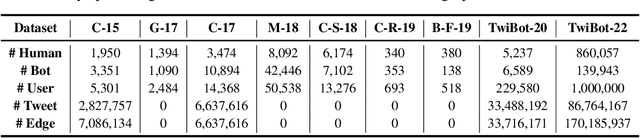
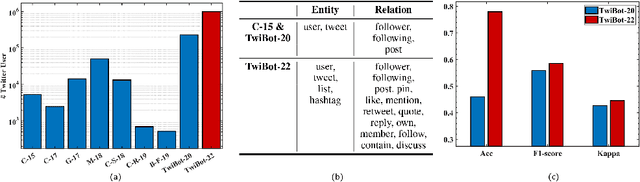
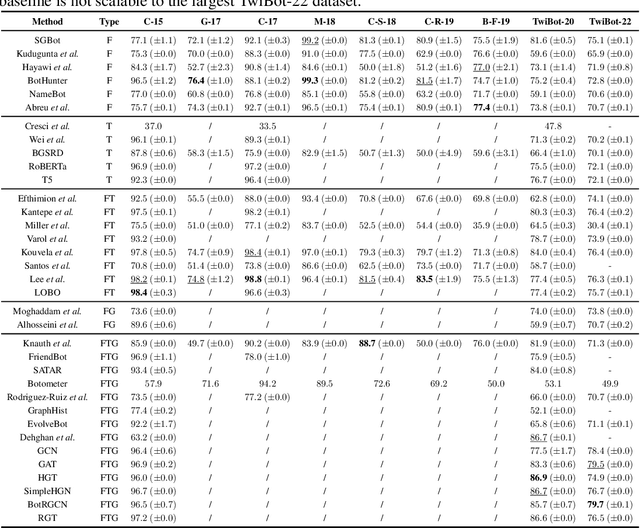
Twitter bot detection has become an increasingly important task to combat misinformation, facilitate social media moderation, and preserve the integrity of the online discourse. State-of-the-art bot detection methods generally leverage the graph structure of the Twitter network, and they exhibit promising performance when confronting novel Twitter bots that traditional methods fail to detect. However, very few of the existing Twitter bot detection datasets are graph-based, and even these few graph-based datasets suffer from limited dataset scale, incomplete graph structure, as well as low annotation quality. In fact, the lack of a large-scale graph-based Twitter bot detection benchmark that addresses these issues has seriously hindered the development and evaluation of novel graph-based bot detection approaches. In this paper, we propose TwiBot-22, a comprehensive graph-based Twitter bot detection benchmark that presents the largest dataset to date, provides diversified entities and relations on the Twitter network, and has considerably better annotation quality than existing datasets. In addition, we re-implement 35 representative Twitter bot detection baselines and evaluate them on 9 datasets, including TwiBot-22, to promote a fair comparison of model performance and a holistic understanding of research progress. To facilitate further research, we consolidate all implemented codes and datasets into the TwiBot-22 evaluation framework, where researchers could consistently evaluate new models and datasets. The TwiBot-22 Twitter bot detection benchmark and evaluation framework are publicly available at https://twibot22.github.io/