 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sonar Moment: Benchmarking Audio-Language Models in Audio Geo-Localization
Jan 06, 2026Geo-localization aims to infer the geographic origin of a given signal. In computer vision, geo-localization has served as a demanding benchmark for compositional reasoning and is relevant to public safety. In contrast, progress on audio geo-localization has been constrained by the lack of high-quality audio-location pairs. To address this gap, we introduce AGL1K, the first audio geo-localization benchmark for audio language models (ALMs), spanning 72 countries and territories. To extract reliably localizable samples from a crowd-sourced platform, we propose the Audio Localizability metric that quantifies the informativeness of each recording, yielding 1,444 curated audio clips. Evaluations on 16 ALMs show that ALMs have emerged with audio geo-localization capability. We find that closed-source models substantially outperform open-source models, and that linguistic clues often dominate as a scaffold for prediction. We further analyze ALMs' reasoning traces, regional bias, error causes, and the interpretability of the localizability metric. Overall, AGL1K establishes a benchmark for audio geo-localization and may advance ALMs with better geospatial reasoning capability.
Behavior Tokens Speak Louder: Disentangled Explainable Recommendation with Behavior Vocabulary
Dec 17, 2025
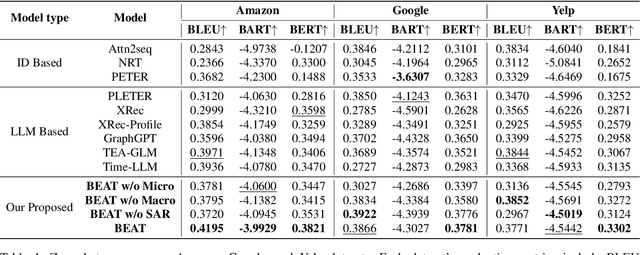


Recent advances in explainable recommendations have explored the integration of language models to analyze natural language rationales for user-item interactions. Despite their potential, existing methods often rely on ID-based representations that obscure semantic meaning and impose structural constraints on language models, thereby limiting their applicability in open-ended scenarios. These challenges are intensified by the complex nature of real-world interactions, where diverse user intents are entangled and collaborative signals rarely align with linguistic semantics. To overcome these limitations, we propose BEAT, a unified and transferable framework that tokenizes user and item behaviors into discrete, interpretable sequences. We construct a behavior vocabulary via a vector-quantized autoencoding process that disentangles macro-level interests and micro-level intentions from graph-based representations. We then introduce multi-level semantic supervision to bridge the gap between behavioral signals and language space. A semantic alignment regularization mechanism is designed to embed behavior tokens directly into the input space of frozen language models. Experiments on three public datasets show that BEAT improves zero-shot recommendation performance while generating coherent and informative explanations. Further analysis demonstrates that our behavior tokens capture fine-grained semantics and offer a plug-and-play interface for integrating complex behavior patterns into large language models.
Improving Temporal Link Prediction via Temporal Walk Matrix Projection
Oct 05, 2024



Temporal link prediction, aiming at predicting future interactions among entities based on historical interactions, is crucial for a series of real-world applications. Although previous methods have demonstrated the importance of relative encodings for effective temporal link prediction, computational efficiency remains a major concern in constructing these encodings. Moreover, existing relative encodings are usually constructed based on structural connectivity, where temporal information is seldom considered. To address the aforementioned issues, we first analyze existing relative encodings and unify them as a function of temporal walk matrices. This unification establishes a connection between relative encodings and temporal walk matrices, providing a more principled way for analyzing and designing relative encodings. Based on this analysis, we propose a new temporal graph neural network called TPNet, which introduces a temporal walk matrix that incorporates the time decay effect to simultaneously consider both temporal and structural information. Moreover, TPNet designs a random feature propagation mechanism with theoretical guarantees to implicitly maintain the temporal walk matrices, which improves the computation and storage efficiency. Experimental results on 13 benchmark datasets verify the effectiveness and efficiency of TPNet, where TPNet outperforms other baselines on most datasets and achieves a maximum speedup of $33.3 \times$ compared to the SOTA baseline. Our code can be found at \url{https://github.com/lxd99/TPNet}.
A Simple Framework for Multi-mode Spatial-Temporal Data Modeling
Aug 22, 2023
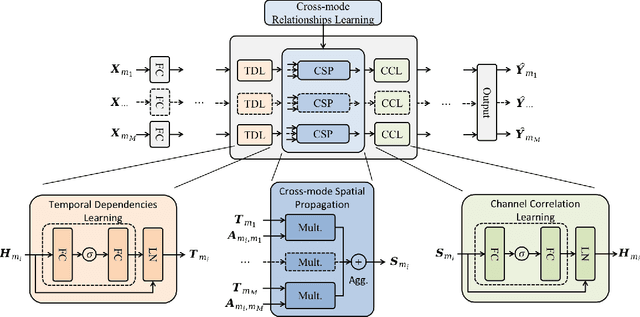
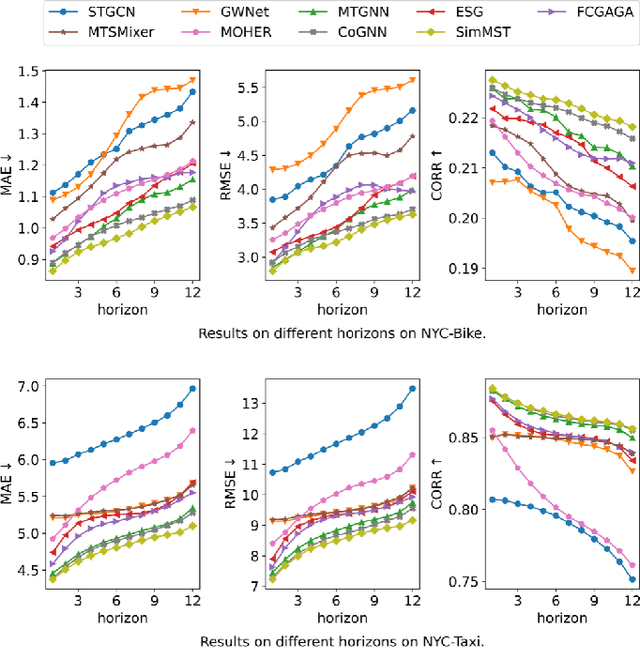

Spatial-temporal data modeling aims to mine the underlying spatial relationships and temporal dependencies of objects in a system. However, most existing methods focus on the modeling of spatial-temporal data in a single mode, lacking the understanding of multiple modes. Though very few methods have been presented to learn the multi-mode relationships recently, they are built on complicated components with higher model complexities. In this paper, we propose a simple framework for multi-mode spatial-temporal data modeling to bring both effectiveness and efficiency together. Specifically, we design a general cross-mode spatial relationships learning component to adaptively establish connections between multiple modes and propagate information along the learned connections. Moreover, we employ multi-layer perceptrons to capture the temporal dependencies and channel correlations, which are conceptually and technically succinct. Experiments on three real-world datasets show that our model can consistently outperform the baselines with lower space and time complexity, opening up a promising direction for modeling spatial-temporal data. The generalizability of the cross-mode spatial relationships learning module is also validated.
Label-Enhanced Graph Neural Network for Semi-supervised Node Classification
May 31, 2022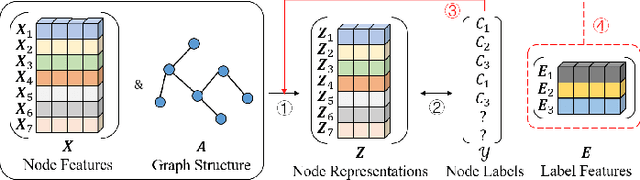

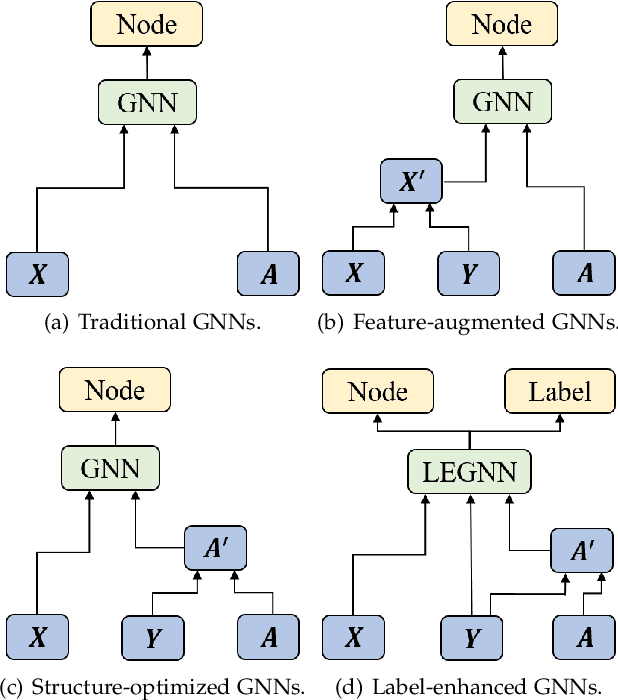
Graph Neural Networks (GNNs) have been widely applied in the semi-supervised node classification task, where a key point lies in how to sufficiently leverage the limited but valuable label information. Most of the classical GNNs solely use the known labels for computing the classification loss at the output. In recent years, several methods have been designed to additionally utilize the labels at the input. One part of the methods augment the node features via concatenating or adding them with the one-hot encodings of labels, while other methods optimize the graph structure by assuming neighboring nodes tend to have the same label. To bring into full play the rich information of labels, in this paper, we present a label-enhanced learning framework for GNNs, which first models each label as a virtual center for intra-class nodes and then jointly learns the representations of both nodes and labels. Our approach could not only smooth the representations of nodes belonging to the same class, but also explicitly encode the label semantics into the learning process of GNNs. Moreover, a training node selection technique is provided to eliminate the potential label leakage issue and guarantee the model generalization ability. Finally, an adaptive self-training strategy is proposed to iteratively enlarge the training set with more reliable pseudo labels and distinguish the importance of each pseudo-labeled node during the model training process. Experimental results on both real-world and synthetic datasets demonstrate our approach can not only consistently outperform the state-of-the-arts, but also effectively smooth the representations of intra-class nodes.
Modelling Evolutionary and Stationary User Preferences for Temporal Sets Prediction
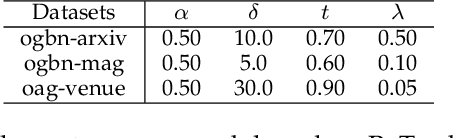
Apr 14, 2022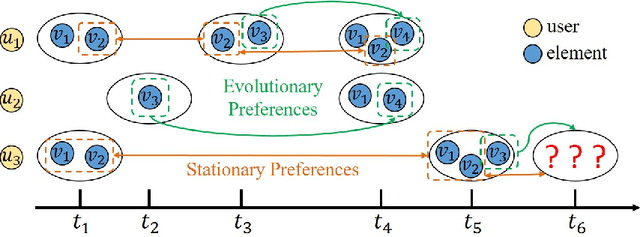

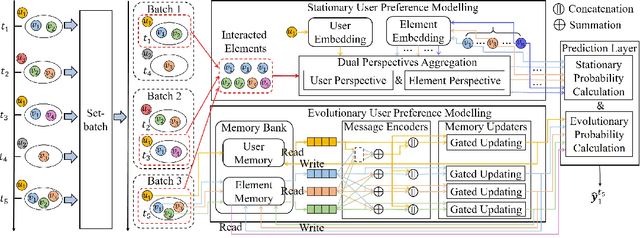

Given a sequence of sets, where each set is associated with a timestamp and contains an arbitrary number of elements, the task of temporal sets prediction aims to predict the elements in the subsequent set. Previous studies for temporal sets prediction mainly capture each user's evolutionary preference by learning from his/her own sequence. Although insightful, we argue that: 1) the collaborative signals latent in different users' sequences are essential but have not been exploited; 2) users also tend to show stationary preferences while existing methods fail to consider. To this end, we propose an integrated learning framework to model both the evolutionary and the stationary preferences of users for temporal sets prediction, which first constructs a universal sequence by chronologically arranging all the user-set interactions, and then learns on each user-set interaction. In particular, for each user-set interaction, we first design an evolutionary user preference modelling component to track the user's time-evolving preference and exploit the latent collaborative signals among different users. This component maintains a memory bank to store memories of the related user and elements, and continuously updates their memories based on the currently encoded messages and the past memories. Then, we devise a stationary user preference modelling module to discover each user's personalized characteristics according to the historical sequence, which adaptively aggregates the previously interacted elements from dual perspectives with the guidance of the user's and elements' embeddings. Finally, we develop a set-batch algorithm to improve the model efficiency, which can create time-consistent batches in advance and achieve 3.5x training speedups on average. Experiments on real-world datasets demonstrate the effectiveness and good interpretability of our approach.