 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReA-OVCD: Reliability-Aware Open-Vocabulary Change Detection via Semantic and Spatial Refinement
Jun 18, 2026Unlike traditional remote sensing change detection that relies on predefined categories, Open-Vocabulary Change Detection (OVCD) identifies land cover changes flexibly using arbitrary text prompts. However, existing methods suffer from an inherent trade-off when modeling changes: instance-level comparison overlooks fine-grained semantic variations (e.g., partial building extensions), while direct pixel comparison proves unreliable, yielding unstable responses and boundary artifacts due to semantic ambiguity and spatial inconsistency. To this end, we propose an efficient training-free Reliability-Aware Open-Vocabulary Change Detection (ReA-OVCD) framework. It first derives candidate change regions from pixel-wise semantic discrepancies to ensure flexible and detailed localization. To ensure reliability, it subsequently introduces a collaborative refinement strategy to explicitly model change validity from both semantic and spatial perspectives. Specifically, we develop a Semantic Change Reasoning (SCR) module that reassesses changes by jointly analyzing distributional divergence and response variation, enabling the suppression of incidental inconsistencies while preserving reliable semantic shifts. In addition, a Boundary-aware Change Refinement (BCR) module is designed to mitigate artifacts stemming from boundary misalignment and uncertainty through validating whether candidate regions are supported by reliable interior pixels. Extensive experiments across multiple datasets (LEVIR-CD, WHU-CD, DSIFN, and SECOND) demonstrate that our method consistently outperforms state-of-the-art approaches, achieving $\mathrm{F}_{1}^{C}$ improvements of 2.13\% to 9.75\% with higher computational efficiency. The code is publicly available at \https://github.com/Funny0101/ReA-OVCD
A Clinical Point Cloud Paradigm for In-Hospital Mortality Prediction from Multi-Level Incomplete Multimodal EHRs
Apr 06, 2026Deep learning-based modeling of multimodal Electronic Health Records (EHRs) has become an important approach for clinical diagnosis and risk prediction. However, due to diverse clinical workflows and privacy constraints, raw EHRs are inherently multi-level incomplete, including irregular sampling, missing modalities, and sparse labels. These issues cause temporal misalignment, modality imbalance, and limited supervision. Most existing multimodal methods assume relatively complete data, and even methods designed for incompleteness usually address only one or two of these issues in isolation. As a result, they often rely on rigid temporal/modal alignment or discard incomplete data, which may distort raw clinical semantics. To address this problem, we propose HealthPoint (HP), a unified clinical point cloud paradigm for multi-level incomplete EHRs. HP represents heterogeneous clinical events as points in a continuous 4D space defined by content, time, modality, and case. To model interactions between arbitrary point pairs, we introduce a Low-Rank Relational Attention mechanism that efficiently captures high-order dependencies across these four dimensions. We further develop a hierarchical interaction and sampling strategy to balance fine-grained modeling and computational efficiency. Built on this framework, HP enables flexible event-level interaction and fine-grained self-supervision, supporting robust modality recovery and effective use of unlabeled data. Experiments on large-scale EHR datasets for risk prediction show that HP consistently achieves state-of-the-art performance and strong robustness under varying degrees of incompleteness.
Incident-Guided Spatiotemporal Traffic Forecasting
Jan 27, 2026Recent years have witnessed the rapid development of deep-learning-based, graph-neural-network-based forecasting methods for modern intelligent transportation systems. However, most existing work focuses exclusively on capturing spatio-temporal dependencies from historical traffic data, while overlooking the fact that suddenly occurring transportation incidents, such as traffic accidents and adverse weather, serve as external disturbances that can substantially alter temporal patterns. We argue that this issue has become a major obstacle to modeling the dynamics of traffic systems and improving prediction accuracy, but the unpredictability of incidents makes it difficult to observe patterns from historical sequences. To address these challenges, this paper proposes a novel framework named the Incident-Guided Spatiotemporal Graph Neural Network (IGSTGNN). IGSTGNN explicitly models the incident's impact through two core components: an Incident-Context Spatial Fusion (ICSF) module to capture the initial heterogeneous spatial influence, and a Temporal Incident Impact Decay (TIID) module to model the subsequent dynamic dissipation. To facilitate research on the spatio-temporal impact of incidents on traffic flow, a large-scale dataset is constructed and released, featuring incident records that are time-aligned with traffic time series. On this new benchmark, the proposed IGSTGNN framework is demonstrated to achieve state-of-the-art performance. Furthermore, the generalizability of the ICSF and TIID modules is validated by integrating them into various existing models.
Global-Lens Transformers: Adaptive Token Mixing for Dynamic Link Prediction
Nov 16, 2025Dynamic graph learning plays a pivotal role in modeling evolving relationships over time, especially for temporal link prediction tasks in domains such as traffic systems, social networks, and recommendation platforms. While Transformer-based models have demonstrated strong performance by capturing long-range temporal dependencies, their reliance on self-attention results in quadratic complexity with respect to sequence length, limiting scalability on high-frequency or large-scale graphs. In this work, we revisit the necessity of self-attention in dynamic graph modeling. Inspired by recent findings that attribute the success of Transformers more to their architectural design than attention itself, we propose GLFormer, a novel attention-free Transformer-style framework for dynamic graphs. GLFormer introduces an adaptive token mixer that performs context-aware local aggregation based on interaction order and time intervals. To capture long-term dependencies, we further design a hierarchical aggregation module that expands the temporal receptive field by stacking local token mixers across layers. Experiments on six widely-used dynamic graph benchmarks show that GLFormer achieves SOTA performance, which reveals that attention-free architectures can match or surpass Transformer baselines in dynamic graph settings with significantly improved efficiency.
DyGKT: Dynamic Graph Learning for Knowledge Tracing
Jul 30, 2024



Knowledge Tracing aims to assess student learning states by predicting their performance in answering questions. Different from the existing research which utilizes fixed-length learning sequence to obtain the student states and regards KT as a static problem, this work is motivated by three dynamical characteristics: 1) The scales of students answering records are constantly growing; 2) The semantics of time intervals between the records vary; 3) The relationships between students, questions and concepts are evolving. The three dynamical characteristics above contain the great potential to revolutionize the existing knowledge tracing methods. Along this line, we propose a Dynamic Graph-based Knowledge Tracing model, namely DyGKT. In particular, a continuous-time dynamic question-answering graph for knowledge tracing is constructed to deal with the infinitely growing answering behaviors, and it is worth mentioning that it is the first time dynamic graph learning technology is used in this field. Then, a dual time encoder is proposed to capture long-term and short-term semantics among the different time intervals. Finally, a multiset indicator is utilized to model the evolving relationships between students, questions, and concepts via the graph structural feature. Numerous experiments are conducted on five real-world datasets, and the results demonstrate the superiority of our model. All the used resources are publicly available at https://github.com/PengLinzhi/DyGKT.
Co-Neighbor Encoding Schema: A Light-cost Structure Encoding Method for Dynamic Link Prediction
Jul 30, 2024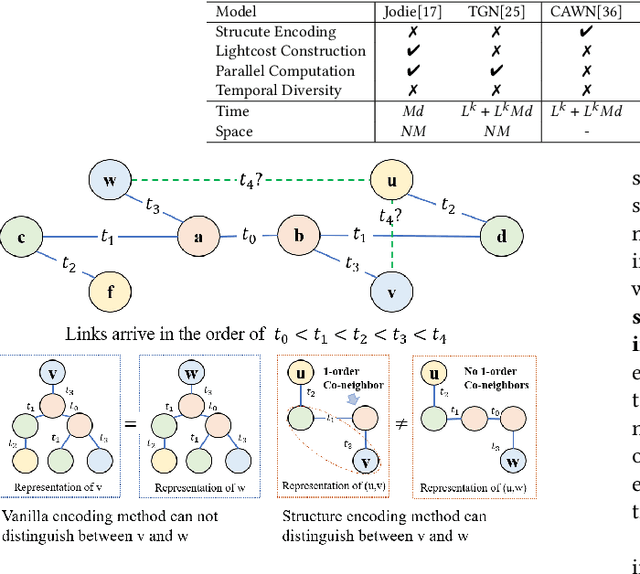

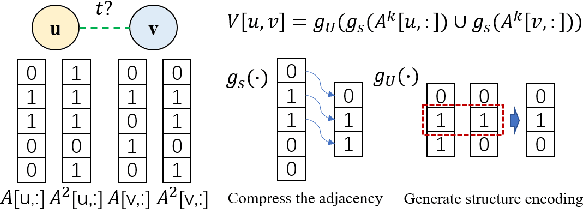
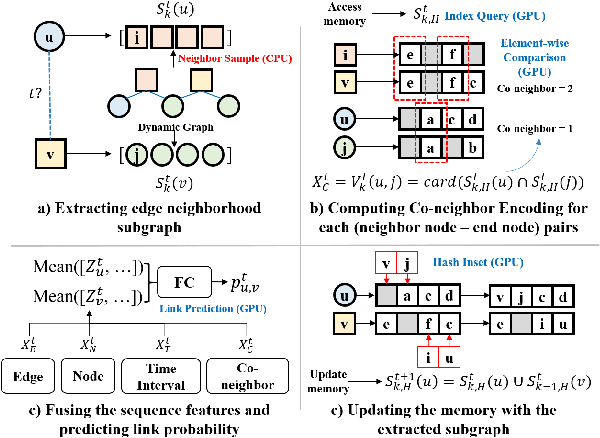
Structure encoding has proven to be the key feature to distinguishing links in a graph. However, Structure encoding in the temporal graph keeps changing as the graph evolves, repeatedly computing such features can be time-consuming due to the high-order subgraph construction. We develop the Co-Neighbor Encoding Schema (CNES) to address this issue. Instead of recomputing the feature by the link, CNES stores information in the memory to avoid redundant calculations. Besides, unlike the existing memory-based dynamic graph learning method that stores node hidden states, we introduce a hashtable-based memory to compress the adjacency matrix for efficient structure feature construction and updating with vector computation in parallel. Furthermore, CNES introduces a Temporal-Diverse Memory to generate long-term and short-term structure encoding for neighbors with different structural information. A dynamic graph learning framework, Co-Neighbor Encoding Network (CNE-N), is proposed using the aforementioned techniques. Extensive experiments on thirteen public datasets verify the effectiveness and efficiency of the proposed method.
Repeat-Aware Neighbor Sampling for Dynamic Graph Learning
May 24, 2024Dynamic graph learning equips the edges with time attributes and allows multiple links between two nodes, which is a crucial technology for understanding evolving data scenarios like traffic prediction and recommendation systems. Existing works obtain the evolving patterns mainly depending on the most recent neighbor sequences. However, we argue that whether two nodes will have interaction with each other in the future is highly correlated with the same interaction that happened in the past. Only considering the recent neighbors overlooks the phenomenon of repeat behavior and fails to accurately capture the temporal evolution of interactions. To fill this gap, this paper presents RepeatMixer, which considers evolving patterns of first and high-order repeat behavior in the neighbor sampling strategy and temporal information learning. Firstly, we define the first-order repeat-aware nodes of the source node as the destination nodes that have interacted historically and extend this concept to high orders as nodes in the destination node's high-order neighbors. Then, we extract neighbors of the source node that interacted before the appearance of repeat-aware nodes with a slide window strategy as its neighbor sequence. Next, we leverage both the first and high-order neighbor sequences of source and destination nodes to learn temporal patterns of interactions via an MLP-based encoder. Furthermore, considering the varying temporal patterns on different orders, we introduce a time-aware aggregation mechanism that adaptively aggregates the temporal representations from different orders based on the significance of their interaction time sequences. Experimental results demonstrate the superiority of RepeatMixer over state-of-the-art models in link prediction tasks, underscoring the effectiveness of the proposed repeat-aware neighbor sampling strategy.
Pretraining Language Models with Text-Attributed Heterogeneous Graphs
Oct 23, 2023In many real-world scenarios (e.g., academic networks, social platforms), different types of entities are not only associated with texts but also connected by various relationships, which can be abstracted as Text-Attributed Heterogeneous Graphs (TAHGs). Current pretraining tasks for Language Models (LMs) primarily focus on separately learning the textual information of each entity and overlook the crucial aspect of capturing topological connections among entities in TAHGs. In this paper, we present a new pretraining framework for LMs that explicitly considers the topological and heterogeneous information in TAHGs. Firstly, we define a context graph as neighborhoods of a target node within specific orders and propose a topology-aware pretraining task to predict nodes involved in the context graph by jointly optimizing an LM and an auxiliary heterogeneous graph neural network. Secondly, based on the observation that some nodes are text-rich while others have little text, we devise a text augmentation strategy to enrich textless nodes with their neighbors' texts for handling the imbalance issue. We conduct link prediction and node classification tasks on three datasets from various domains. Experimental results demonstrate the superiority of our approach over existing methods and the rationality of each design. Our code is available at https://github.com/Hope-Rita/THLM.
Adaptive Taxonomy Learning and Historical Patterns Modelling for Patent Classification
Aug 10, 2023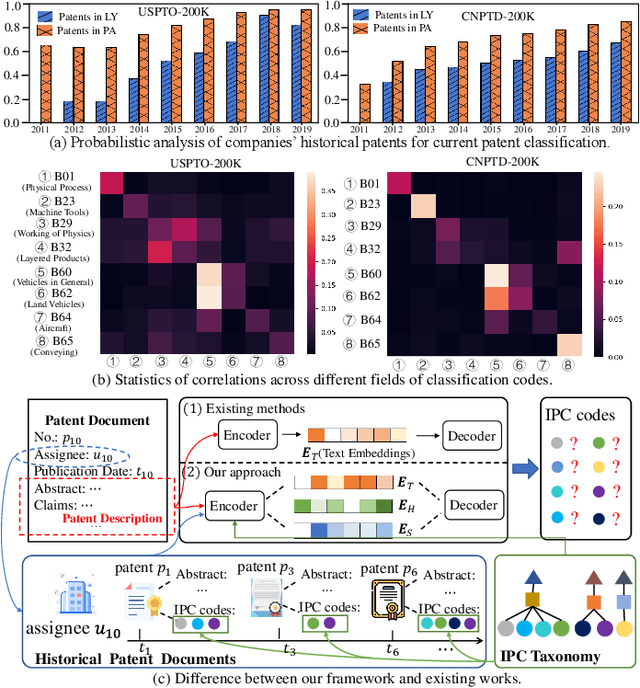

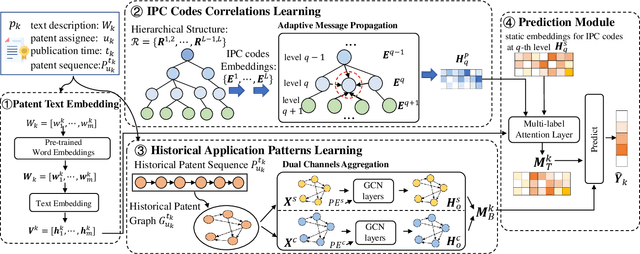
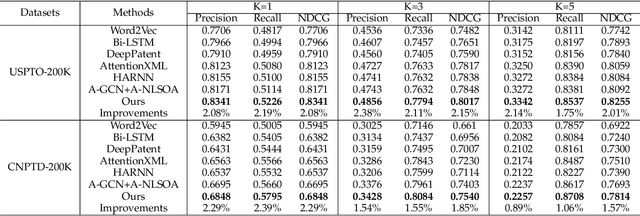
Patent classification aims to assign multiple International Patent Classification (IPC) codes to a given patent. Recent methods for automatically classifying patents mainly focus on analyzing the text descriptions of patents. However, apart from the texts, each patent is also associated with some assignees, and the knowledge of their applied patents is often valuable for classification. Furthermore, the hierarchical taxonomy formulated by the IPC system provides important contextual information and enables models to leverage the correlations between IPC codes for more accurate classification. However, existing methods fail to incorporate the above aspects. In this paper, we propose an integrated framework that comprehensively considers the information on patents for patent classification. To be specific, we first present an IPC codes correlations learning module to derive their semantic representations via adaptively passing and aggregating messages within the same level and across different levels along the hierarchical taxonomy. Moreover, we design a historical application patterns learning component to incorporate the corresponding assignee's previous patents by a dual channel aggregation mechanism. Finally, we combine the contextual information of patent texts that contains the semantics of IPC codes, and assignees' sequential preferences to make predictions. Experiments on real-world datasets demonstrate the superiority of our approach over the existing methods. Besides, we present the model's ability to capture the temporal patterns of assignees and the semantic dependencies among IPC codes.
Event-based Dynamic Graph Representation Learning for Patent Application Trend Prediction
Aug 04, 2023Accurate prediction of what types of patents that companies will apply for in the next period of time can figure out their development strategies and help them discover potential partners or competitors in advance. Although important, this problem has been rarely studied in previous research due to the challenges in modelling companies' continuously evolving preferences and capturing the semantic correlations of classification codes. To fill in this gap, we propose an event-based dynamic graph learning framework for patent application trend prediction. In particular, our method is founded on the memorable representations of both companies and patent classification codes. When a new patent is observed, the representations of the related companies and classification codes are updated according to the historical memories and the currently encoded messages. Moreover, a hierarchical message passing mechanism is provided to capture the semantic proximities of patent classification codes by updating their representations along the hierarchical taxonomy. Finally, the patent application trend is predicted by aggregating the representations of the target company and classification codes from static, dynamic, and hierarchical perspectives. Experiments on real-world data demonstrate the effectiveness of our approach under various experimental conditions, and also reveal the abilities of our method in learning semantics of classification codes and tracking technology developing trajectories of companies.